Article Text

Abstract
Introduction Linkage and retention in HIV medical care remains problematic in the USA. Extensive health utilisation data collection through electronic health records (EHR) and claims data represent new opportunities for scientific discovery. Big data science (BDS) is a powerful tool for investigating HIV care utilisation patterns. The South Carolina (SC) office of Revenue and Fiscal Affairs (RFA) data warehouse captures individual-level longitudinal health utilisation data for persons living with HIV (PLWH). The data warehouse includes EHR, claims and data from private institutions, housing, prisons, mental health, Medicare, Medicaid, State Health Plan and the department of health and human services. The purpose of this study is to describe the process for creating a comprehensive database of all SC PLWH, and plans for using BDS to explore, identify, characterise and explain new predictors of missed opportunities for HIV medical care utilisation.
Methods and analysis This project will create person-level profiles guided by the Gelberg-Andersen Behavioral Model and describe new patterns of HIV care utilisation. The population for the comprehensive database comes from statewide HIV surveillance data (2005–2016) for all SC PLWH (N≈18000). Surveillance data are available from the state health department’s enhanced HIV/AIDS Reporting System (e-HARS). Additional data pulls for the e-HARS population will include Ryan White HIV/AIDS Program Service Reports, Health Sciences SC data and Area Health Resource Files. These data will be linked to the RFA data and serve as sources for traditional and vulnerable domain Gelberg-Anderson Behavioral Model variables. The project will use BDS techniques such as machine learning to identify new predictors of HIV care utilisation behaviour among PLWH, and ‘missed opportunities’ for re-engaging them back into care.
Ethics and dissemination The study team applied for data from different sources and submitted individual Institutional Review Board (IRB) applications to the University of South Carolina (USC) IRB and other local authorities/agencies/state departments. This study was approved by the USC IRB (#Pro00068124) in 2017. To protect the identity of the persons living with HIV (PLWH), researchers will only receive linked deidentified data from the RFA. Study findings will be disseminated at local community forums, community advisory group meetings, meetings with our state agencies, local partners and other key stakeholders (including PLWH, policy-makers and healthcare providers), presentations at academic conferences and through publication in peer-reviewed articles. Data security and patient confidentiality are the bedrock of this study. Extensive data agreements ensuring data security and patient confidentiality for the deidentified linked data have been established and are stringently adhered to. The RFA is authorised to collect and merge data from these different sources and to ensure the privacy of all PLWH. The legislatively mandated SC data oversight council reviewed the proposed process stringently before approving it. Researchers will get only the encrypted deidentified dataset to prevent any breach of privacy in the data transfer, management and analysis processes. In addition, established secure data governance rules, data encryption and encrypted predictive techniques will be deployed. In addition to the data anonymisation as a part of privacy-preserving analytics, encryption schemes that protect running prediction algorithms on encrypted data will also be deployed. Best practices and lessons learnt about the complex processes involved in negotiating and navigating multiple data sharing agreements between different entities are being documented for dissemination.
- HIV/AIDS
- big data science
- machine learning
- predictive modeling
- health care utilisation
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
This study is among the first in the USA to accumulate individual level data from multiple sources for predictive model development and validation of health utilisation in a statewide population of persons living with HIV (PLWH).
This study is unique in its ability to examine health utilisation for all South Carolina PLWH from initial diagnosis across different treatment points and times in the HIV treatment cascade.
Obtaining data release agreement, collecting and merging HIV sensitive data from different entities require significant time and effort to ensure privacy and confidentiality of all subjects.
Although missing data or incorrect data may be a problem for care status classification, mandatory statewide reporting of HIV diagnosis and laboratory markers (CD4 and viral load) provides confidence in data completeness.
Machine learning techniques could yield a several combinations of factors that could be difficult to interpret, but in anticipation of this problem, we have constituted a clinician expert review panel, and plan to use chart abstractions for further validation.
Introduction
Ending the HIV epidemic requires focus on ‘treatment as prevention’ as a goal. Prevention through linkage and retention in HIV medical care are key objectives of Healthy People 2020 and National HIV/AIDS Strategy.1 2 Advances in HIV medications have made living a healthy life possible for persons living with HIV (PLWH), with well-established associations between linkage to/retention in HIV medical care and viral load (VL) suppression.3–17 Recent numbers and proportions of South Carolina (SC) PLWH engaged in each step of the HIV treatment cascade show that cumulatively, only 66% received any medical care, and of these, only 54% received continuous HIV medical care.18 Similarly, national estimates show that 42%–59% of patients with HIV are not in HIV medical care.4 12 19
Health inequities persist in the HIV treatment cascade for PLWH in SC.20 These health inequities are important since a lack of engagement and retention in HIV medical care increases the likelihood of HIV transmission due to poor VL suppression.3–14 16 17 Neither access to health insurance nor early linkage to care have thus far predicted retention in and consistent use of HIV medical care. This study proposes using both statistical and machine learning techniques to identify new and important predictors of HIV cascade treatment outcomes for PLWH, that is, CD4 and VL.
A responsive healthcare system must engage all PLWH at all stages of the HIV treatment cascade from HIV testing, linkage to care, timely initiation of care, retention in care and adherence to antiretroviral treatment (ART) with repeated CD4/viral load (VL) testing. Adoption of electronic health records (EHR), combined with the use of big data science (BDS) techniques provides an opportunity to improve health outcomes and manage high-risk and high-cost PLWH.21–24 This study will create a comprehensive dataset accumulated from multiple sources, and use innovative BDS techniques to analyse new and old predictors of retention in HIV medical care. General health utilisation behaviour pre-HIV diagnosis will be studied to identify where missed opportunities for HIV testing occurs. PLWH profiles based on HIV medical care seeking behaviour will be developed with concomitant identification of gaps in HIV care and missed opportunities. The resulting model from this study will be used by the State Department of Health and Environmental Control (DHEC) to improve HIV care, through individual targeted linkage to, and retention in care. This study extends beyond the traditional scope of most HIV research in proposing novel machine learning processes for developing and validating a model of HIV medical care utilisation. In this protocol, we describe the process for acquiring datasets, data linkages and methods we will use to establish a population cohort from 2005 to 2016. Linkage of different datasets at the individual level using unique identifiers (IDs) at the population level enables us to achieve the following specific aims:
Use five commonly used measures of retention (described elsewhere) in HIV care25 to generate a profile and pattern of care-seeking behaviour for SC PLWHs.
Use data mining and predictive analytics to identify missed opportunities for HIV testing prior to HIV diagnoses for SC PLWHs using CD4 count/VL as laboratory-based markers of time.
Identify gaps in the treatment cascade for all SC PLWHs who were never in care, not in care or who transition in and out of care compared with those consistently in HIV medical care.
Develop and validate a predictive risk model useful for targeting HIV care linkage interventions to all SC PLWHs who are never in care, not in care, transition in and out of care and at risk for dropping out of care.
Purpose
The purpose of this study is to describe the framework and process for creating a comprehensive database of all SC PLWH and plans for using BDS to explore, identify, characterise and explain new predictors of missed opportunities for HIV medical care utilisation. Study findings will be integrated with ongoing efforts of the SC DHEC’s Data-to-Care (DTC) Program, and the Ryan White Care Program to link and retain PLWH in care.
Methods and analysis
This project is a population cohort-based study aimed at improving HIV treatment for all SC PLWH. Analytic focus will be on classification to predict where missed opportunities occur, gap identification and utilisation management across the HIV treatment cascade. We will classify the PLWH to four care groups: (1) never in care, (2) transitioning in and out of care, (3) not in care and (4) consistently in care using CD4/VL laboratory biomarkers and other demographics. An investigation into why certain health utilisation behaviours occur within the care group will be done using segmentation analysis. We will use predictive data mining to score newly identified variables representing the probability of the individual behaviour (action) occurring in the future (in this case HIV medical care utilisation).26–28 Findings will be validated through a triangulated process involving the use of a HIV clinician expert panel, chart abstraction review process and through the ‘DTC’ community advisory board to explain and interpret new patterns/characteristics.
Guiding conceptual framework
This study is informed by an adaptation of the Gelberg-Andersen Behavioral Model framework.11 26 This model identifies factors affecting health services utilisation among vulnerable patient populations and measures domains relevant for elucidating health utilisation patterns.29 30 Socioecological factors affecting engagement in HIV medical care model will help guide the interpretation of new clusters of predictors.12 Studies have identified factors referred to in both models as important to PLWH.18 19 31–36
Study area and population
This study will be conducted in SC located in the southeastern region of the USA, with a population of 4 961 119 in 2016.37 Current epidemiological profile shows the PLWH ((n=18998) as mostly African-American [69%], men (71%) and aged 30–49 years (41%)).38
Data sources
The proposed data linkage is complex, and the comprehensive dataset is large. To our knowledge, no such data have ever been linked to study HIV treatment outcomes at the population level in the USA. Novel application of BDS techniques using a population of PLWHs can break new grounds and provide additional tools for improving care outcomes through the estimation of individual risks. Data sources are described in greater detail below.
SC Office of Revenue and Fiscal Affairs (RFA) Integrated Data System
RFA collects individual health utilisation data based on state laws requiring mandatory data reporting. The state law Section 44-6-170 guides the RFA in collecting and releasing healthcare related data. Since 1996, the RFA receives reports on all diagnoses from emergency departments, hospital inpatient, ambulatory care and outpatient surgery facilities in the Uniform Billing form (UB-92) format.39 Non-compliant facilities face stiff penalties which increases compliance. At the RFA, individual patient information will be linked using unique patient IDs such as name, birth date and social security number.
The RFA’s integrated data structure is recognised as a great example of an integrated data system in the USA (figure 1).40 Data from RFA includes, but are not limited to:
All payer healthcare inpatient database.
Medicaid services claims data (including demographic file, visits file and pharmacy file).
State Employee Health Services Plan data.
Department of Corrections data (crime rates, prison history, etc).
Department of Mental Health.

South Carolina Office of Revenue and Fiscal Affairs Integrated Data System.
DHEC e-HARS and Ryan White RSR data
Confidential name-based reporting of HIV/AIDS in SC as a reportable disease began in February 1986 leading to the creation of DHEC’s enhanced HIV/AIDS reporting system (e-HARS).39 41 e-HARS is a laboratory-based reporting system to which all statewide CD4 and VL tests are reported since 1 January 2004 as mandated by the Code of Laws of SC Section 44-29-10: Regulation 61-20.39 41 e-HARS is a collection of computer programs and data files developed by the Centers for Disease Control and Prevention to simplify the management and analysis of HIV/AIDS surveillance data. DHEC also provides linkage to Ryan White Care clinic data through the Ryan White HIV/AIDS Program Service Reports (RSR). The annual RSR captures information regarding the services provided by all Ryan White-funded entities.42
Health Sciences South Carolina (HSSC) Data
HSSC is a biomedical research collaborative consisting of six of the state’s largest health systems namely the Greenville Hospital System, University Medical Center, Palmetto Health, Spartanburg Regional Healthcare System, McLeod Health, AnMed Health and Self Regional Healthcare and the state’s largest research-intensive universities Clemson University, the Medical University of SC and the University of SC. HSSC clinical data warehouse includes a Master Patient Index from multiple health systems that allows for the matching of clinical records across disparate information systems for a single patient.
Area Health Resources File (AHRF) and census tract data
The AHRF is a public dataset made available by Health Resources and Services Administration which contains data on healthcare professions, hospitals and healthcare facilities and US census population data. The AHRF provides health system-level information in areas such as healthcare professions, health facilities, hospital utilisation, expenditure and environment. Additional data on education, poverty, median income, employment, and so on, for different areas in SC will be extracted from the American Community Survey data.
Data linkage, release and security
RFA operations are guided by the SC data oversight council (DOC) as mandated by the state legislative assembly. The DOC oversees and regulates the collection and release of healthcare data in approved formats based on prevailing privacy laws. Data elements, which, when linked to other databases, can directly or indirectly identify a patient/healthcare professional, health insurer or healthcare facility are restricted. Protected health information such as patient name, address and social security numbers are never releasable; however, the RFA will use them to conduct final data linkages. The RFA will act as the honest data broker, deidentify the data and create unique IDs useful for research purposes. Table 1 demonstrates the extent of data linkage and highlights connections across different data sources. Detailed data release agreements are required and were secured from each data source before linkage. As a result of the scope and complexity of the data linkage, the state health department (DHEC) and the RFA created an intra-agency data sharing agreement to guide the data sharing process between both agencies. This intra-agency agreement provided specific terms and rules for data linkage to ensure confidentiality. In addition, SC Medicaid, departments of mental health, social services and corrections carefully reviewed the proposed data linkage to ensure stringent adherence to patient confidentiality. During data linkage, the RFA retained the right to create new variables in lieu of variables that could remotely identify any individual. Two examples are described here. First, the RFA scrambled the dates by introducing a modifier known only to them, while maintaining the original time between each date. This made it impossible for researchers to identify PLWH based on dates of service. In another example, rather than releasing spatial identifying data like zip codes or census block information, the RFA created the needed variables for the study, after carefully assessing the demand for the information. So instead of researchers receiving zip code data to calculate individual distance travelled for care, the RFA computed the distance travelled and included it in the final dataset as a computed variable. This workaround ensured that while the researchers did not get the zip code information, they still received the measure of interest (distance travelled to/from facility) computed by the RFA. A similar approach was deployed for all potential identifiable patient information. The state health department (DHEC) and the RFA hold the keys to the unique IDs created during the linkage. This will enable them to apply the models and algorithms created during the study, to individualised PLWH interventions in the future. All data transfers occur using secure file transfer protocols. Data are received from sources fully encrypted and stored fully encrypted with encryption software. The data are stored in a key-access only facility hosting servers. Network shares for users are created via a distributed file system and user access is controlled via user groups containing unique IDs that require complex passwords on facility site.
HIV treatment cascade and corresponding variables data sources*†
Population inclusion criteria
Only living PLWH whose residence at diagnosis was SC are included in the study. A key question when describing PLWH not in HIV medical care is outmigration. Census estimates show a positive net immigration trend for SC, and so we do not expect any problem.43 Nevertheless, we will scrutinise the data carefully to interpret our data appropriately in case migration becomes an issue. Only cases with age ≥13 in the diagnosed prevalence year are included in the analysis (ie, age must be ≥13 in 2005 to be included in analysis). We chose 2005 since this was the year after the state law mandatory reporting of all CD4 and VL tests to e-HARS began. Twelve years (2005–2016) of HIV utilisation data is available for this study.
HIV medical care patterns and Gelberg-Andersen Model variables
Gelberg-Andersen Model variables
Predisposing, enabling and need factors correspond to the wide array of HIV data associated with linkage to care, retention, re-engagement and ART monitoring in the HIV treatment cascade. Variables reflecting Gelberg-Andersen Model along with their corresponding stages along the HIV treatment cascade and their data sources are illustrated in figure 2. Focus will be placed on categorising variables under the appropriate factor predictive of their HIV medical care utilisation. These variables are available from the previously described data sources.

HIV treatment cascade including Gelberg-Andersen Model variables and data sources.
Detailed examples of specific Gelberg-Anderson predisposing variables available through the e-HARS database include patient name, birth date, social security number (restricted data elements for linkage only), date of first positive HIV test, AIDS diagnosis date, source of report and transmission risk factor. Others include gender, race/ethnicity, county of residence, year of death, cause of death (International Classification of Diseases (ICD)-9, ICD-10 codes), poverty, education, median income, employment, and so on, all CD4 +T cell counts and VL values. Vulnerable predisposing domain variables, such as criminal behaviour, violent status, mental illness, and childhood characteristics, are provided through RFA data sources. Enabling factors such as regular source of care will be obtained from Medicaid/State Healthcare plan. Data related to social support and public benefits will be obtained from RSR through medical case management and RFA. Need factor variables will be obtained through inpatient claims data from HSSC and RFA. The inpatient data include patient demographics, source and type of admission, visits/encounters, diagnoses, procedures, laboratory results and length of stay. For HIV utilisation outcomes data, e-HARS will provide CD4 and VL measures as predictors of retention in care. The core variables for HIV utilisation, for example, missed visits, appointment adherence, constancy in 3-month or 4-month, 6-month interval (retention in care variables) are described in table 2. We will define visits/health encounters that lead care providers to suggest HIV testing, that is, to persons belonging to a high-risk group for HIV acquisition and who presented with HIV-related or non-HIV-related clinical conditions.
Selected variables for HIV care pattern determination*
Antiretroviral medication and polypharmacy
EHR from patient encounters available through the RFA and HSSC capturing information about PLWH healthcare service utilisation and medications will be analysed during the study. EHR data from the RFA contain information related to encounter visits, diagnosis, laboratory services and medications (number prescribed, drug class, indication, strength and dosage). Binary variables will be created for ART status.
Data analysis plan
Data management, cleaning and mining
Data will be assessed for reliability to deal with issues related to missing, aberrant or extreme values. New variables and data inclusion criteria in each aim will be validated through chart review, HIV clinicians’ expert panel and the DTC community advisory board.26–28 We will reduce the dimension of the variables (number of variables) using autocorrelation, multicollinearity and principal component analysis as guided. The focus during data management will be on eliminating extreme outliers, and excluding irrelevant variables and discretising (binning) continuous variables. Appropriate methods will be deployed to prepare for classification and prediction.
Population segmentation
To achieve specific aim #1, supervised and unsupervised machine learning will be used to identify care patterns or HIV utilisation. Once an individual is assigned to a certain care group, it is necessary to discover a pattern that may lead them to this care group. Thus, we will try to classify them based on the individual and system factors that lead the recognition of the care group. Many classification tools are available in machine learning: logistic regression, naive Bayes classifier, support vector machine and random forest. Most can be implemented in R. Different distance methods (eg, Jaccard or Gower) will be deployed to measure similarities between HIV utilisation. Once the distance between variable is correctly measured, the clustering method, a method of unsupervised learning, will be operated over a distance matrix instead of the original data matrix. Both the K-means clustering and partitioning around medoids algorithms (PAM) will be applied to classify the data into ‘k’ groups.26–28 40 For example, we will use cluster analysis to partition the health utilisation data into groups of similar health utilisation behaviour. Derived clusters will be interpretable based on relevant Gelberg-Andersen variables and as such can be assigned a description/class label. The result of a cluster analysis is a binary tree, or dendrogram, with n–1 nodes. We propose using tree pruning to adjust model complexity for the creation of an optimal model. The simplest model with the highest validation assessment will be considered the best model. Statistics for judging the model will depend on the type of prediction classifications, rankings or estimates. For prediction estimates, the squared error (difference between target and estimate) will be used to assess model performance.2 26–28 40
Predictive modelling
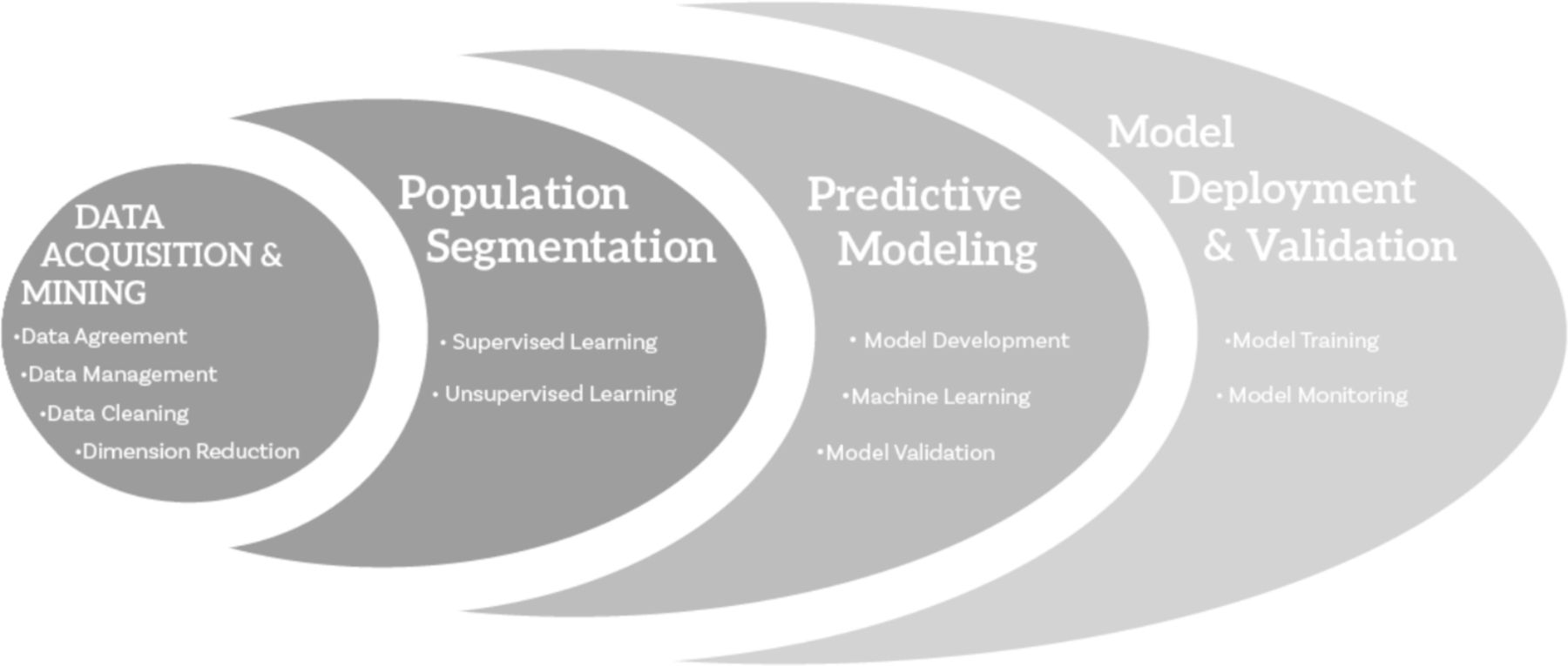
For specific aims #2–3, we will identify the associations between the missed opportunities and/or treatment cascade, such as timing to care and consistency in care with Gelberg-Andersen domain inputs such as gender, race, sexual orientation, crime history, location, and so on. To achieve specific aim #4, we will build and validate appropriate predictive statistical models, such as multinomial logistic regression model, Cox proportional hazards model and generalised linear mixed model, to investigate the impact of care pattern, missed opportunity and Gelberg-Andersen variables to investigate how soon linkage to care, status in care and CD4/VL level changes. A HIV clinician expert panel and the DTC community group will provide guidance on the interpretation of new findings. Once the model is validated, trained and assessed using test data, it will be deployed and monitored for performance. An overview of the analytic plan is illustrated in figure 3.

{kind=link}
{kind=link}
{kind=link}
Analytic plan.
Model development and validation
Once the pattern is identified such as health utilisation pattern, variable distributions will be summarised for pattern status (mean, SD and counts), and compared using the t-test, analysis of variance test and χ2 test. Where test assumptions are not satisfied, non-parametric tests (Wilcoxon rank test and Kruskal-Wallis Test) will be applied. Results will be discussed among the investigation team to find the most appropriate pattern characteristic. Care patterns identified in aim 1 and the risk factors and missed opportunities identified in aim 2 will serve as the main exposure variables to identify the association between the HIV treatment cascade, HIV care patterns and missed opportunities. All variables in Gelberg-Andersen Behavioral Model, which can be identified in the linked dataset, will be used as the potential risk factors. With the patient characteristics, hospital information, care information and variables in Gelberg-Andersen Behavioral Model, a high dimension of predictors is expected. Cross validation will be used to evaluate the prediction performance and to compare the different risks prediction model. The data will be divided into training, testing and validation data. Potential interactions between variables will be examined, using the log-likelihood ratio test to determine statistical significance. Using machine learning techniques, we will create algorithms that can alert/flag high dropout risk PLWH. In addition, we will automate the algorithms to determine the best predictors of re-engagement into HIV medical care based on historical health utilisation patterns, CD4 counts and viral suppression. The algorithms will be shared with DHEC and RFA, who will apply these algorithms to the original data. The algorithms will also be shared with the Ryan White Program for use in monitoring and retaining PLWH in care.
Model monitoring and validation
While the promise inherent in data mining is in discovering new and useful patterns in big data, its true value is in responding to these patterns by acting on them. This ultimately moves data into information, information into action and action into value. We anticipate developing 2–3 predictive models. After predictive models are developed, and validated, they will be deployed against new claims data showing healthcare utilisation. Since we have observations for PLWH who use HIV medical care consistently (an identified segment/cluster), we will create a unique normalised score for this population and set it as the norm for comparison. Profiles and predictors of care status for the not-in-care population will be assessed by the models deployed against new claims data (2017–2018). Model scores will be assessed to evaluate model performance and accuracy using a propensity score analysis.2 26–28 40 Findings will be reviewed by the HIV clinician’s expert panel as well as the DTC advisory group. They will help inform the identification of new variables and predictors by cross validating them based on abstracted charts. Validation rules will be established to guide this process.19 Algorithms for the model will be created and embedded with DHEC’s HIV surveillance system and Ryan White Program. Qualified state personnel will use this information to identify/flag those at risk for dropping out of care, those out of care and those not likely to engage in care after linkage. The goal in doing this is to help provide targeted assistance to such high-risk individuals. The algorithms will be reviewed intermittently based on the availability of new data to ensure good performance.
Patient involvement
Patients were not involved in preparing this study protocol.
Discussion
The linkage of several databases capturing traditional clinical outcomes through the EHR and other health claims-based system, integrated to a social determinants of health data system under the purview of this study, holds significant promise for HIV medical care. Prior to this study, the confidential nature of HIV has limited translational research across the HIV treatment cascade to either clinical or social determinants studies, but rarely both. The challenges with finding such data sources are significant, as is the ability to measure variables at the individual level. BDS techniques offer the potential of opening new possibilities for managing complex health conditions like HIV.43 The robust value inherent in using population-based cohorts for improving health outcomes and predicting future health utilisation is documented.44 45 Successful examples of previous and ongoing application of BDS techniques can be found in automated ECG interpretation, automated detection of lung nodules from X-rays, and creation of Framingham Risk Score.46 Other examples using unsupervised learning for pattern identification exist in the ongoing development of precision medicine,47–51 systolic heart failure survival prediction52 and the use of machine learning to automate diagnosis of acute brain infractions.53 BDS techniques have successfully been applied to large-scale clinical studies such as the CArdiovascular disease research using LInked Bespoke studies and Electronic health Record study in the UK44 and Comparison of Medical Therapy, Pacing, and Defibrillation in Heart Failure (COMPANION) trials in the USA.45 Studies point to these examples as the future and real added value of BDS techniques like machine learning.54 The combination of machine learning techniques with expert clinicians, case workers, stakeholders together has serious potential to improve the collective health of PLWH. This study is unique in its data linkage and population focus, giving it strengths and precision unavailable to previous studies using samples of PLWH for retention in care studies. This study also goes beyond prior studies by integrating both model development and model validation using BDS techniques and meet the checklists for reporting as recommended by the ‘Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis’ guidelines.55 The novelty in this study is the integration of traditional and vulnerable domain factors with large troves of EHR data, and its tieback to actual linkage and retention in care. The state department of health (DHEC) surveillance programme, and Ryan White Program will be strengthened with the ability to flag PLWH at risk for not engaging in care after linkage, or those at risk at dropping out of care. This study plans to automate a process that had been previously manually done. It also improves the process by flagging individuals at high risk for not engaging in or dropping out of care for intervention. In addition, locations/providers where missed opportunities for HIV care re-engagement occurred will also receive strengthening to improve patient engagement. DHEC’s legal mandates allow them to work closely with clinical providers in targeting individualised interventions to such at-risk PLWH. This will help improve engagement in, and future retention in care among PLWH.
Future improvement and application of the model
Plans for model improvement using future population HIV care utilisation data will improve model performance and external validation as we focus on evaluating the incremental value of specific predictors (new and old) for HIV care utilisation. Future data will be deployed to the models for model maintenance and improvement. The use of the health system by PLWH not in care represents missed opportunities for re-engaging them into HIV medical care. Without treatment as a form of prevention, ending the HIV epidemic is harder to achieve. Benefits from advances in HIV treatment are also lost for those not in care. However, investigating characteristics for those who are not in care is difficult and expensive for health departments. The application of BDS to this process will make substantive improvements, and allow clinicians, social workers and other stakeholders help re-engage this hard to reach population back into care.
Acknowledgments
The authors thank SC Department of Health and Environmental Control, SC Revenue and Fiscal Affairs office, Health Sciences South Carolina for providing the data on People Living with HIV in South Carolina.
References
Footnotes
Contributors BO, XL and MRH drafted the manuscript. XL, BO and JZ conceived and designed the study. JZ, SW, and JH made substantial contributions to the study design and manuscript editing. XL and BO are responsible for study coordination; BO, JZ, JH and MRH are responsible for data quality control, management and analysis. All authors contributed to the writing of the study protocol in an iterative manner and have read and approved the final manuscript.
Funding This study is supported by the National Institute of Allergy and Infectious Diseases of the National Institutes of Health under Award Number 1R01AI127203-01A1. Li and Olatosi are the PI for the study.
Disclaimer The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Patient consent for publication Not required.