Article Text

Abstract
BACKGROUND Interventions based in the community can be evaluated by randomising clusters, such as general practices, rather than individuals, as in conventional randomised trials. This increases the sample size needed because of intracluster correlation.
AIMS To estimate sample size requirements for cluster randomised trials of interventions based in general practice directed at common health problems affecting mothers and infants.
METHODS Data were collected from a pilot trial of the effect of Citizen's Advice Bureau services involving six general practices. Outcome measures included the Edinburgh postnatal depression score, the Warwick child health and morbidity profile, number of visits to the general practitioner, and two questionnaires delivered at the beginning and end of the study. Intracluster correlation coefficients and inflation factors (the ratio of the sample size required for a cluster randomised trial to that required for an individually randomised trial) were calculated.
RESULTS Intracluster correlation coefficients ranged from 0 (sleeping problems, accidental injury, hospitalisation) to 0.09 (maternal smoking), with most being < 0.04 (for example, maternal depression, breast feeding, general health, minor illness, behavioural problems, and visits to the general practitioner). Assuming 50 cases/practice, cluster randomised trials require sample sizes up to 3 times greater than individually randomised trials for most health outcomes measured.
CONCLUSIONS These data enable sample sizes to be estimated for cluster randomised trials into a range of maternal and child health outcomes. Using such a design, approximately 40 practices would be sufficient to evaluate the effect of an intervention on maternal depression, sleeping, and behavioural problems, and non-routine visits to the general practitioner.
- cluster randomisation
- primary care
- sample size
- intracluster correlation
- maternal and child health
Statistics from Altmetric.com
In general, randomised controlled trials are thought to be the gold standard for evaluation of interventions to improve health. The design evolved from trials of drug treatment and now includes evaluations of many other modalities of treatment, including social and psychological interventions.1 2 However, where the intervention is directed at a whole community, randomisation of individuals to treatment or control might be impossible or impractical. In these circumstances, randomisation of communities (or clusters) is an alternative that retains the methodological strength of randomisation.3 4 Communities in this context can be clinics, general practices, schools, neighbourhoods, urban districts, or even whole towns and cities. In this paper we concentrate on randomisation of general practices.
Cluster randomised trials are an important method of evaluating community based interventions.5 Paediatricians need to be aware of their strengths and weaknesses because they can be widely applied to evaluative research in maternal and child health. The practical advantages are that whole practice populations can be studied; the organisation of the trial might be simpler; primary care workers might find this method of randomisation less intrusive; and the practical problems of offering an intervention to some, but not others, within a practice are overcome.
The theoretical advantages are that contamination of the effects of the intervention from subjects to controls is minimised,6 an important consideration for trials of health promotion interventions. In addition, this method is the only way of evaluating an intervention that is designed to influence the way a primary health care worker or team operates. Finally, it might be possible to evaluate interventions at the cluster level that could not ethically be introduced on an individually randomised basis.7 For all these reasons, cluster randomised trials are likely to be used much more frequently in the future.
However, there are disadvantages to this type of study design.3 8 For example, it might be difficult, or even impossible, to blind subjects and researchers. The decision of whether to recruit individuals within practices or to enrol whole practices en bloc throws up many ethical and practical dilemmas.7 Here, we consider the specific issue of the potential loss of statistical power caused by randomising groups rather than individuals, and how this affects sample size considerations. This is not simply an obscure statistical problem, but a fundamental aspect of the study design of such trials.9
We have conducted a pilot study for a cluster randomised trial of the effects on child and maternal health of providing a Citizen's Advice Bureau service within primary care. Citizen's Advice Bureaus in the UK are a network of organisations in which trained volunteers provide advice to clients on welfare, legal, employment, housing, and consumer rights; on financial and debt management; on resolution of disputes; and on a range of other related issues. This is an example of the type of intervention that is best evaluated using a cluster randomised design. It is also typical of the social interventions currently being proposed for reducing health inequalities.10 Data from our study show how sample size calculations are affected by the group randomisation design. The results should also be applicable in the design of other studies of interventions to improve child and maternal health where general practices are to be randomised.
Statistical background
In a conventional randomised controlled trial it is routinely assumed that the data from each subject are independent of each other. Independence of data is a prerequisite for simple tests of significance such as t tests, and also for more complex statistical methods, such as regression. When clusters are randomised, the individuals within each group or cluster are unlikely to be independent of each other.
There are many possible reasons for this. If the cluster is a clinic or general practice, it might attract patients or clients who share similar attitudes or socioeconomic circumstances. If the intervention involves primary health care workers, their individual style and approach might profoundly affect the efficacy of the intervention. If the cluster is a school, its health ethos might influence the outcome measures of interest—for example, whether it has an antismoking policy. If the cluster is a neighbourhood, environmental factors are likely to affect all people in the neighbourhood similarly. The consequence of all these potential influences is that results from individuals within clusters tend to be more similar to each other than results from individuals between different clusters. The technical description of this phenomenon is intracluster correlation, and it can be measured by the intracluster correlation coefficient, or ρ.
Intracluster correlation reduces statistical power, which means that overall numbers of subjects have to be increased. Factors that need to be taken into account in sample size calculations are the distribution of the outcome measure in the population and the presumed effect of the intervention,10 the size of the individual clusters, the number of clusters, and the amount of intracluster correlation. It is intuitively obvious that increasing the number of clusters will increase the power, and that the lower the intracluster correlation, the greater the power. It is perhaps less obvious that simply increasing the number of subjects in each cluster will do relatively little to change the power because the increased precision of the results might be offset by a stronger effect of the intracluster correlation.
The ratio of the number required in a cluster randomised study to the number that would be required in an equivalent individually randomised study is called the inflation factor. To calculate the inflation factor, the intracluster correlation coefficient of the outcome measure is needed.3 9 11 12 Several investigators have called for the publication of such data to inform the design of other studies in the same field.4 6
Methods
SOURCE OF DATA
Six general practices from an urban area covering a mixed population took part. Three practices were randomly selected to provide Citizen's Advice Bureau services from within primary care, with the other three practices acting as controls. Eligible families were those with an infant under 1 year of age at the start of the trial and all new births during the nine months of the intervention. Two hundred and ninety families were recruited from these practices. We have included data on the mother and the first infant recruited in these families. We have omitted data from five families with more than one eligible infant because these data would complicate the intracluster correlation calculations. Outcomes included a range of measures of both maternal and child health derived from two questionnaires at the beginning and end of the intervention, and from examination of the general practice notes. From the questionnaires we selected for detailed consideration the Edinburgh postnatal depression score,13 questions about behaviour problems, sleeping problems, maternal smoking, and visits to the general practitioner in the previous two weeks, or to the hospital in the previous two months. The second questionnaire also included adapted questions on general health, common illnesses, behaviour, accidents, and hospitalisation from the Warwick child health and morbidity profile.14 From the general practice notes we extracted information on consultations, coded according to type of problem along lines developed by McKinney et al.15 Theoretically, data derived from the second questionnaire and the general practice records might show a spuriously high intracluster correlation because they are subject to the effect of the intervention; however, in practice, this will have had a minimal effect for reasons explained in the discussion.
The trial was conducted as a pilot for a projected larger definitive trial of the effects on maternal and child health of the provision of advice services. The objectives of this pilot were to provide data to calculate sample sizes, to identify the practical and logistic difficulties posed by such a trial, and to measure in detail the financial and material benefits obtained by mothers of young children who have access to a Citizen's Advice Bureau service within their doctors' surgeries.
STATISTICAL METHODS
Intracluster correlation coefficients for each of the outcome measures of interest were calculated according to the formula derived by Fleiss,16 which uses mean square values from a one way analysis of variance:

where MS values are the mean squares from the ANOVA table and m is the average size of the clusters. This method is equally applicable to both dichotomous variables and to continuous variables.12
16Because the size of each cluster varied, we substituted a term m0 instead of m in the above equation17:

where k is the total number of clusters, mi is the number of cases in the “ith” cluster, with i ranging from 1 to k, and n is the total number of individuals in the sample.
The inflation factor (IF) is calculated using the formula given by Donner et al.9
IF = 1 +(m−1)ρ (3)
To calculate sample sizes, the number required in an individually randomised study is multiplied by the inflation factor. Sample sizes for individually randomised studies were calculated using conventional formulae.18
Results
Table 1 shows data from the families who were eligible for our trial. Although the families of 919 children were eligible, only 290 families were recruited, 261 of whom returned the initial questionnaire, and 219 the second questionnaire. General practitioner notes were reviewed for 196 of the mothers and 200 of the children from the recruited families, the rest were unobtainable because they had moved or the notes were otherwise unavailable at the practice.
Numbers of subjects with data from each practice and some socioeconomic data
Table 2 shows the overall values of the health measures we collected for the total sample, the intracluster correlation coefficients calculated using equation 1 above, and a suggested minimum effect size, which would correspond to a clinically important outcome of a community based social intervention.
Outcome measures, intracluster correlations, and suggested minimum effect sizes
Table 3 shows the effect of increasing the number of subjects in each cluster on the total number of clusters required. As an example, we include an intervention to reduce the population mean Edinburgh postnatal depression core from 8.5 to 7.5. A conventional individually randomised trial with 80% power to detect this difference with a two tailed significance of 95% would require 882 subjects (441 in each arm) using the population data from the first questionnaire in our study.18 If, instead, we conducted a trial where practices were randomised to provide the intervention, the table shows the total number of practices required when different sized samples from each practice are chosen. As the size in each cluster increases, the overall number of clusters reduces. However, there are diminishing returns, in that there comes a point at which very large increases in cluster size are required to reduce the total number of clusters further. This is best seen graphically in fig 1.
Sample size requirements for a cluster randomised trial to reduce the average Edinburgh postnatal depression score from 8.5 to 7.5
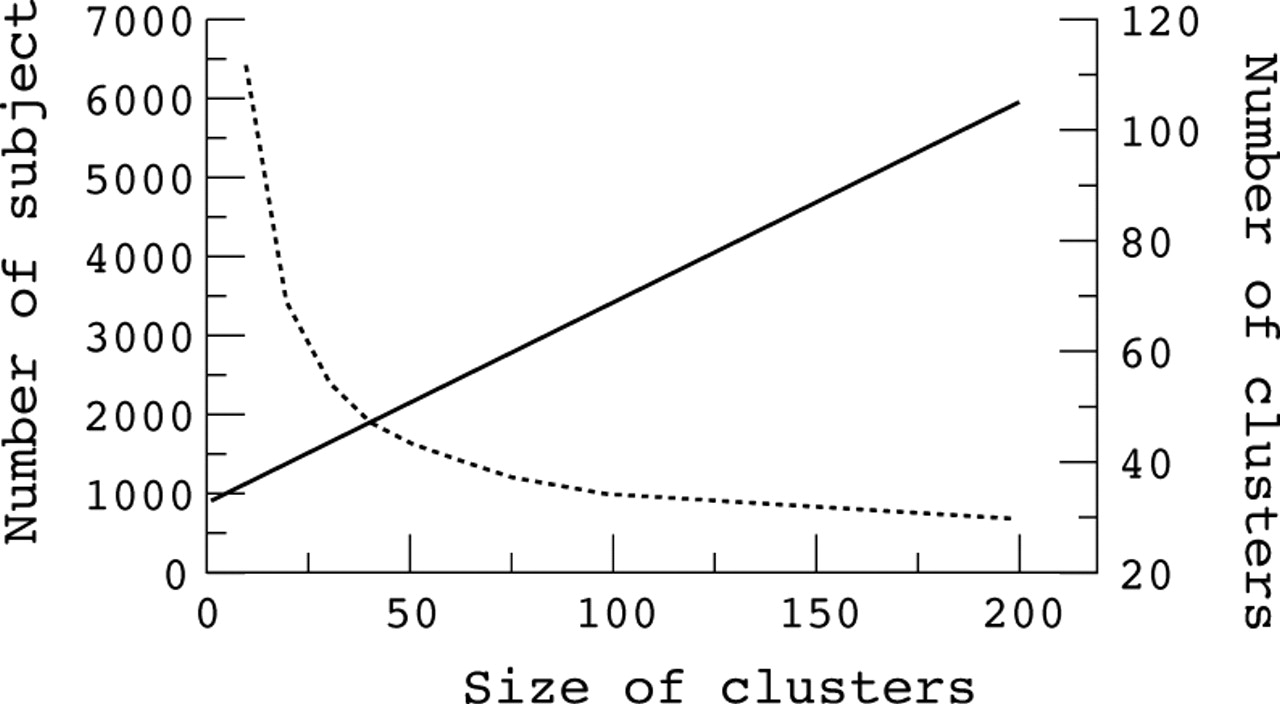
{kind=link}
The effect of different cluster sizes on the number of subjects and number of clusters required for a cluster randomised trial. Solid line, number of subjects required; broken line, number of clusters required. The data illustrate a trial to reduce the average Edinburgh postnatal depression score from a mean value of 8.5 (SD, 5.3) to a mean of 7.5, with 80% power to detect the difference at a two tailed significance of 95%, assuming an intracluster correlation coefficient of 0.029.
We found that it would be possible to recruit 50 to 80 families with infants over a one year period from an average urban practice (table1). Table 4 uses data from table 2 to show the number of practices that would be required for a cluster randomised trial to test the effects of a primary care based intervention on the outcome measures we have illustrated if 50 cases were recruited for each practice.
Number of practices required for cluster randomised trial (CRT) of interventions for typical mother and child health outcomes, assuming 50 cases/practice
Discussion
We have shown that for a range of health outcomes in mothers and infants, the number of practices needed for a cluster randomised trial is large, and for some of these outcomes the number is too large to make such a trial feasible. The reasons that such large numbers are required are twofold. In some cases—for example, maternal smoking, breast feeding, and postnatal depression, there are relatively high intracluster correlation coefficients. This translates into a large inflation factor. It is not surprising that the intracluster correlations are high, because a range of social, cultural, and neighbourhood factors influence the characteristics of a practice population, and the approach of general practitioners, health visitors, and other primary care staff can potentially influence the health outcome measures.
In other cases—for example, sleeping problems and accidents, the intracluster correlations are low or non-existent. Here, large sample sizes are required because the underlying rate in the population is low, or the postulated effect of an intervention is small. This is not a problem for cluster based designs only: the same sample size difficulty would occur with an individually randomised design.
There are several drawbacks to our study. The small number of practices reduces the precision of our estimates of intracluster correlations. This has a potentially important impact. Small differences in the value of the intracluster correlation coefficient can translate into large differences in the calculated inflation factor. Second, the results apply to urban general practices covering a mixed population. It would be inappropriate to apply our results to sample size calculations that included rural practices or practices covering highly affluent or highly deprived populations. Another potential weakness is that we included both control and intervention practices in our study. If the intervention had a large effect, this would increase the apparent intracluster correlation. However, the intervention was poorly taken up and did not have a large demonstrable effect, and comparing intracluster correlation coefficients from both questionnaires shows no systematic increase over time (table 2). Despite the limitations of our results, they enable an informed approach to sample size calculations for cluster randomised trials in maternal and child health.
What then are the implications of our results? Cluster randomised trials based in primary care are feasible for some of the outcomes we have measured. Even where the inflation factor is two to three times for cluster sizes of 50, trial sizes are manageable. A good example would be a study of the provision of advice services to reduce postnatal depression. The real challenge is not to find outcomes with low intracluster correlation, but to find outcomes with a sufficiently high prevalence, and interventions with sufficiently large effect sizes. For example, sleeping and behavioural problems had a low prevalence in our study population, most of whom were under 1 year of age. If we had studied an older group of toddlers we might have expected a prevalence of disorders of around 30%. A trial of an intervention to reduce this prevalence to 20%, even assuming an inflation factor of 2.5, would not require more than 40 practices. The very low intracluster correlation we found in the younger age group might not be applicable to older children, but our results suggest that inflation factors are unlikely to exceed 2 to 3.
The publication of intracluster correlations within general practice populations of common child and maternal health problems is essential. Our results need to be seen in that context. We have presented the data in a way that enables different baseline assumptions about effect sizes and cluster sizes to be substituted in sample size calculations.
The more general implications of our results relate to the initial choice of study design. Where there is a choice between a cluster randomised design and a conventional individually randomised trial, the superficial attraction of having to deal with only a few clusters rather than many individuals might be outweighed by the increased overall size of the trial. From our experience on this pilot, there are many hidden difficulties in managing such studies. Where there is no choice, and a cluster randomised design is the only practical way of evaluating an intervention that maintains the benefits of randomisation, our results provide justification for the large size that might be necessary.
Acknowledgments
The Citizen's Advice Bureau and family health study team are R Reading (paediatrician) M Mclean (health psychologist), J Appleby (health economist), S Reynolds (clinical psychologist), all from the school of health policy and practice, University of East Anglia; S Kember and J Watts, health visitor team leaders from the Norwich Community Health Partnership NHS Trust; and M Wright (assistant director) and J Wheatley (adviser) from the Norwich Citizen's Advice Bureau. The study was funded by the NHS Anglia and Oxford regional research and development directorate under grant number HSR/UEA/1196/87. We are grateful to all the families and health visitors, general practitioners, and practice managers for their involvement in the study. We also thank K Branson, M Busuttil, B Coupland, S Jarvis, S Mugford, T Peters, N Shinh, S Steele, and J Tanner for advice, support, and data collection. The study received ethical approval from the Norwich local research ethics committee. Copies of the questionnaires are available from the authors on request.
Appendix
The formula for ρ, the intracluster correlation coefficient, given in the text is the most convenient one for data that is available at the level of individuals. The value of ρ can also be calculated from data only available as rates or prevalences at the level of the cluster (that is, by general practice). Assume there are k clusters, xi is the number of positive cases, and mi the number of all cases in the “ith” cluster, with i ranging from 1 to k.

In this equation, p is the overall proportion of positive cases and m̄ is the mean cluster size. The results obtained in our study differ slightly if this equation is used, because the degrees of freedom for the mean square between clusters in this equation is taken as k rather than (k − 1) in our study. We considered (k − 1) to be the appropriate value because k was rather small in our study, whereas Fleiss assumes k > 20 for his derivation.16