
Abstract
Background
In matched-pair cohort studies with censored events, the hazard ratio (HR) may be of main interest. However, it is lesser known in epidemiologic literature that the partial maximum likelihood estimator of a common HR conditional on matched pairs is written in a simple form, namely, the ratio of the numbers of two pair-types. Moreover, because HR is a noncollapsible measure and its constancy across matched pairs is a restrictive assumption, marginal HR as “average” HR may be targeted more than conditional HR in analysis.
Methods
Based on its simple expression, we provided an alternative interpretation of the common HR estimator as the odds of the matched-pair analog of C-statistic for censored time-to-event data. Through simulations assuming proportional hazards within matched pairs, the influence of various censoring patterns on the marginal and common HR estimators of unstratified and stratified proportional hazards models, respectively, was evaluated. The methods were applied to a real propensity-score matched dataset from the Rotterdam tumor bank of primary breast cancer.
Results
We showed that stratified models unbiasedly estimated a common HR under the proportional hazards within matched pairs. However, the marginal HR estimator with robust variance estimator lacks interpretation as an “average” marginal HR even if censoring is unconditionally independent to event, unless no censoring occurs or no exposure effect is present. Furthermore, the exposure-dependent censoring biased the marginal HR estimator away from both conditional HR and an “average” marginal HR irrespective of whether exposure effect is present. From the matched Rotterdam dataset, we estimated HR for relapse-free survival of absence versus presence of chemotherapy; estimates (95% confidence interval) were 1.47 (1.18–1.83) for common HR and 1.33 (1.13–1.57) for marginal HR.
Conclusion
The simple expression of the common HR estimator would be a useful summary of exposure effect, which is less sensitive to censoring patterns than the marginal HR estimator. The common and the marginal HR estimators, both relying on distinct assumptions and interpretations, are complementary alternatives for each other.
Similar content being viewed by others

Background
Matching is a useful sampling method employed in cohort studies, in which the control of confounders is indispensable [1]. The simplest matching design is a 1:1 matched (matched-pair) cohort study, in which each matched pair comprising an exposed and an unexposed member is followed up through the study period. The standard choices of effect measures are common odds ratio (OR) and risk ratio (RR) conditional on matched pairs. As the number of pairs increases, asymptotically unbiased estimate of common OR across matched pairs is the ratio of the number of “discordant” pairs [2, 3]; using the numbers of pairs shown in Table 1, the conditional maximum likelihood estimator (CMLE) of common OR is B/C [2]. This estimator coincides with the Mantel–Haenszel OR estimator [4] and the unconditional maximum likelihood estimator using multinomial distribution of (A, B, C, D) parameterized under common OR [5]. Common RR may be estimated by the Mantel–Haenszel RR estimator, which simplifies to the crude RR (A + B)/(A + C) [3, 6], by estimating equations for parameters in conditional multiplicative risk models [7], or by conditional Poisson regression models, which are mimicked by stratified Cox model-fitting with Breslow or Efron-type tie breaking [8, 9].
One of the concerns in cohort studies is censoring owing to unequal follow-up period or loss to follow-up before the end of the study. In the presence of censoring, common hazard ratio (HR) is a viable alternative. Common HR can be estimated by the Mantel–Haenszel rate ratio [6] or partial maximum likelihood estimators (PMLE) of Cox proportional hazards models stratified on matched pairs [10,11,12]. However, perhaps because of the ease of Cox model-fitting by modern computer software, it is lesser known that the PMLE of common HR can also be transcribed in a simple formula as in the case of CMLE of common OR [10]. The formula motivates us to focus on the relationship of the PMLE to the matched-pair analog of C-statistics for time-to-event, which has been recently discussed in the literature for evaluating discriminatory ability in prediction [13,14,15].
This representation would be useful because HR (like OR) is known to be a noncollapsible measure: even under homogeneity of conditional HR across strata and in the absence of confounding, marginal (unadjusted) HR is not necessarily equal to the conditional one [16, 17]. Moreover, the assumption of homogenous (common) HR across strata may be too restrictive. To circumvent interpretational difficulties, marginal HR estimated by unstratified Cox models with robust variance estimator is often of primary interest than common HR [18]. Even when HR is not constant over time, it may be interpreted as the “average” HR of time-varying HR [19]. However, we argue that the uncritical “average” view of marginal HR may have limited value because the estimator depends on censoring distribution that is nuisance to inference for exposure effect on outcome [20, 21].
In this paper, we showed the simple expression of the common HR estimator and its alternative interpretation as the odds of the matched-pair analog of C-statistic for censored time-to-event data. Through simulation studies, assuming proportional hazards within the matched pairs, we evaluated the influence of various censoring patterns on the marginal and common HR estimators of unstratified and stratified proportional hazards models, respectively. For illustration, several estimators were compared in a propensity score-matched dataset of primary breast cancer from the Rotterdam tumor bank.
Methods
In this section, we provide the simple formula for the common HR estimator under a stratified proportional hazards model in matched-pair cohort studies. The common HR is linked to overall C-index with matched-pair analog to improve its interpretation. By simulation studies under the stratified proportional hazards models, we compare the performance in competing estimators as well as statistical tests used in matched-pair cohort studies in various censoring distributions. Finally, we illustrate the methods in a real dataset.
Stratified PMLE of common HR in matched-pair cohorts
Consider matched-pair cohort studies comparing time-to-event outcome T, in which each pair k (k = 1,…, n) is comprised of an exposed (e = 1) and an unexposed member (e = 0). Because outcome T ke of member e in pair k may be censored by drop-out time U ke , or the end of follow-up τ, we observe follow-up time as \(X_{ke} = \hbox{min} (T_{ke} ,U_{ke} ,\tau )\). Define Y ke as an indicator of event (Y ke = 1 if X ke = T ke , 0 otherwise). Suppose all risk factors have the same distribution within each pair.
If we are interested in common HR across all matched pairs throughout the follow-up period, an appropriate model is the Cox proportional hazards model stratified on the matched-pair k:
where λ ke (t) and β are a hazard function of T ke and logarithm of common HR, respectively.
Partial likelihood of (1) is given by the product of the contribution at each event time from each stratum k, expressed as follows [10,11,12]:
To express the contribution L k (β) from each stratum, we classify each pair observable in matched-pair data into eight types (Table 2). For clarity, the only tie we additionally consider is caused by the end of follow-up, i.e., X k1 = X k0 = τ (type 9). Let n 1,…, n 9 denote the number of pairs of types 1–9. Partial likelihood in the presence of other types of ties are shown in “Appendix 1”.
Pairs of types 1 and 3 contribute to partial likelihood by \(\frac{\exp (\beta )}{1 + \exp (\beta )}\), pairs 2 and 4 contribute by \(\frac{1}{1 + \exp (\beta )}\), and pairs of types 5–9 do not contribute to it. Eventually, the only contributors for the PMLE are those who are in the pairs in which the pair-member with shorter observed time experienced an event; this is the necessary and sufficient condition for “comparable” pairs in C-statistic for time-to-event, which we revisit later [13,14,15]. The resulting partial likelihood (2) is
where G = n 1 + n 3 denotes the number of pairs where the exposed member has shorter observed time and experienced an event (types 1 and 3) and H = n 2 + n 4 denotes the number of pairs where the unexposed member has shorter observed time and experienced an event (types 2 and 4). Therefore, all information regarding matched-pair data for common HR is concentrated on the number of only two types of pairs.
By maximizing partial likelihood, we can write the PMLE of common HR as G/H. Substituting G/H into the observed Fisher information [11], the approximate variance estimator of log(G/H) can be obtained by 1/G + 1/H. These are of the same form as the logarithm of the CMLE log(B/C) and its variance estimator 1/B + 1/C [2, 3].
Tests of null association
To test the null hypothesis of common OR in matched-pair data, McNemar’s test is often recommended [22,23,24]. The test statistic is \(\frac{{(B - C)^{2} }}{B + C}\), which is also a function of B and C. Similarly, by using the definitions of G and H from above Klein and Moeschberger [12] have developed a stratified log-rank test statistic \(\frac{{(G - H)^{2} }}{G + H}\) as a weighted rank statistic. As the number of pairs grows, \(\frac{{(G - H)^{2} }}{G + H}\) has an asymptotic Chi-squared distribution with one degree of freedom under β = 0. Similar to McNemar’s test that can be considered as the score test of OR = 1 in a conditional logistic model [3], the stratified log-rank test can be considered as the score test for β = 0 in a stratified Cox model (1). Note that Wald and score tests for the hypothesis of conditional HR (or OR) = 1 can be shown to be asymptotically equivalent to test statistics for marginal HR (or OR) = 1 [25]. Therefore, tests for both conditional and marginal null hypotheses in different models may be used interchangeably, although OR and HR are both noncollapsible measures.
Stratified PMLE as overall C-statistic for matched pairs
For binary exposure E (1 if exposed, 0 if unexposed) and time-to-event outcome T, overall C-index (C-index for time-to-event) is defined as
where τ is the time of the end of follow-up or an arbitrary time interval set by analysts [13, 14]. Assuming the absence of censoring except at the end of follow-up, Pencina and D’Agostino proposed to estimate C τ by restricting all possible pairs in the sample to “comparable” pairs, in which the member with a shorter observed time experienced an event, i.e., “\(X_{i} < X_{j} ,Y_{i} = 1,X_{i} < \tau\)” [14].
We can consider the matched-pair analog of C τ :
where (e 1, e 2) is either (0, 1) or (1, 0), and sampling is made for matched pairs k = 1,…, n. Let S ke (t) and f ke (t) denote survival and density functions of T ke , respectively. Given the matched-pair design considered here, \(\Pr (e_{1} = 1,\quad e_{2} = 0\,{\text{in}}\,{\text{pair}}\,k\left| {T_{{ke_{1} }} < T_{{ke_{2} }} ,\quad T_{{ke_{1} }} < \tau } \right.)\) is expressed as \(\Pr (T_{k1} < T_{k0} \left| {T_{k1} < \tau \,{\text{or}}\,T_{k0} < \tau } \right.) = \frac{{\Pr (T_{k1} < T_{k0} ,T_{k1} < \tau )}}{{1 - S_{k0} (\tau )S_{k1} (\tau )}}\). Taking the odds of this probability yields the following under the stratified Cox model (1):
Therefore, the common HR exp(β) equals C τ,pair/(1 − C τ,pair) if common HR > 1, and (1 − C τ,pair)/C τ,pair if common HR < 1. In fact, this relationship has been derived by Holt and Prentice over 40 years ago for τ = ∞, in which case \({\text{C}}_{{\tau , {\text{pair}}}} = \Pr (T_{k1} < T_{k0} )\) if common HR > 1 and \({\text{C}}_{{\tau , {\text{pair}}}} = \Pr (T_{k1} > T_{k0} )\) otherwise [10].
Due to censoring by U ke , event times T k1 and T k0 are not always observable. As shown in the “Appendix 2”, G/(G + H) converges in probability (as pair number n grows) to
Note that (3) is not equal to \(\Pr (T_{k1} < T_{k0} \left| {T_{k1} < \tau {\text{ or }}T_{k0} < \tau } \right.)\) in general. Thus, C τ,pair cannot be apparently calculated by the observed data if censoring before τ occurs. “Appendix 2” shows, however, that under the model (1), the odds of (3) equal exp(β) even if T ke is censored by U ke that is independent to T ke conditional on matched pairs and exposure. Thus, we can estimate C τ,pair as well as β based on only “comparable” matched pairs introduced by design even if censoring depends on both matched pairs and exposure.
Simulation studies
To examine the performance of the stratified PMLE under the assumption (1) compared to competitive PMLEs used in matched-pair cohort studies, we simulated 2000 cohorts with size 2n = 100, 500 (n = 50, 250 exposed–unexposed pairs). SAS code for generating data will be provided in the Additional file 1.
We simulated each pair’s “effect” γ k as a standard normal variate, assuming that matching eliminates all confounding, though the assumption is at best expected to approximately hold in practice. Time-to-event was then generated from the random-intercept (frailty) model [11, 12] \(\lambda_{ke} (t) = \lambda_{0} \exp (\gamma_{k} )\exp (\beta \cdot e)\) with λ 0 = 1 and common log-HR β = log(2.0), log(1.0), and log(0.5). The time was censored by exponential variate according to the following censorship patterns:
-
1.
Independent censoring with the rate parameter of 1, 2, and 4, or
-
2.
Conditionally independent censoring given strata and exposure, where the rate parameter equals γ k + αe, α = log(0.25), log(1.0), and log(4.0).
We also employed Weibull time-to-event variables in additional scenarios to emulate the situations in which (1) baseline hazards increase or decrease instead of the time-constant hazard λ 0, or (2) the shape parameter varied between the strata while keeping stratum-specific HR fixed as a constant across strata. As the results from these additional scenarios were similar to those from the above exponential-normal frailty model, the parameter settings and the results are provided in the Additional file 1.
We fitted pair-stratified Cox models, unstratified Cox models with or without robust sandwich variance estimator [26], as well as true frailty Cox models as a reference. Note that stratified and frailty models assume that the conditional parameter is constant across matched pairs, while unstratified models only model a marginal parameter and do not assume such constancy across pairs.
With the frailty Cox models used in the data generation, the marginal distributions of time do not follow proportional hazards except for the positive-stable distributed frailty [12]. Thus, the unstratified Cox model is known to be misspecified. One way around this problem is to define the model parameters as the asymptotic means of the maximum-likelihood estimators that are free from censoring, which is always well-defined and interpretable (even if the models are not correct) [20, 27, 28]. Therefore, the targeted marginal HR in this study is defined as a mean of the estimate of unstratified Cox models calculated in a large (n = 5,000,000) dataset where no member is censored.
The performance of the above estimators was evaluated by mean bias (the average of 2000 log-HR estimates—true log HR), empirical standard error (standard deviation of 2000 estimates), mean estimated standard error, root mean squared error (RMSE; the square root of the sum of the squared bias and the empirical variance of the estimator), and coverage proportion of 95% confidence intervals. The empirical power (or type I error when HR = 1) tested by Wald statistics (log-HR estimates divided by their estimated standard errors) of the above was also compared, accompanied by a stratified log-rank test statistic. We used PHREG procedure in SAS version 9.4 (Cary, NC).
Application: propensity-matched cohort data from the Rotterdam tumor bank
To illustrate the methods in a real dataset, we used the records from the Rotterdam tumor bank, which includes follow-up data on 2982 women with primary breast cancer. The dataset is available in the R package AF developed by Dahlqwist and Sjölander [29] and the details of the dataset have been described elsewhere [30]. The outcome T is relapse-free survival, which is defined as time to developing relapse of breast cancer or death from any cause before the end of the follow-up period. Women remained in the dataset until they experienced relapse or death, were lost to follow-up or were at the end of the follow-up period, whichever came first. The exposure of interest is the absence of chemotherapy (1 if treated without chemotherapy, n = 2402; 0 if treated with chemotherapy, n = 580).
One notable feature in this dataset is that the amount of confounding is very strong—adjusting for the possible confounders reverses the sign of the association [30]. Thus, we turned the dataset into a matched cohort based on propensity score (the conditional probability of exposure given possible confounders). Propensity score is conditional on the following prognostic variables: age at surgery (years), menopausal status (0 if premenopausal, 1 if postmenopausal), tumor size (≤20 mm, >20–50 mm, and >50 mm), tumor grade (2 or 3), progesterone receptors, (fmol/l), oestrogen receptors (fmol/l), and the number of positive lymph nodes [ranging between 0 and 34; transformed into exp(–0.12 * the number of nodes)]. We estimated the propensity score for each woman by fitting a logistic model, and then matched women on the estimated propensity scores by caliper-based pair-matching algorithm without replacement (allowable caliper width was 20% of the standard deviation of estimated propensity scores in a chemotherapy group). The resulting matched cohort is comprised of n = 446 exposed–unexposed pairs. The SAS code for forming the propensity-matched cohort from the Rotterdam dataset is provided in the Additional file 1.
Results
Simulation results
Table 3 shows the results in independently censored data (similar results were obtained for n = 50, provided in online supplementary material). The marginal HR defined in the unstratified models is towards null from conditional HR, similar to the well-known result that the marginal OR is closer to null than common stratum-specific OR [16]. In fact, marginal HR always lies between the conditional HR and 1 under the exponential survival model [17]. Null exposure effect in conditional HR implies that marginal HR is also null. In this case, no estimator has a bias. Coverage of confidence intervals maintains almost nominal level except for the unstratified model without robust variance that overestimates the true variability.
For non-null HR (β ≠ 0), PMLE for unstratified models have “bias” from conditional HR that partly reflects the noncollapsible property of HR [17] and the dependency on censoring distribution. The latter also impedes its interpretation as “average” marginal HR that is independent of censoring. Frailty to disease structurally changes hazard among the remaining risk-set over the follow-up period [19, 31]: under our simulation model, HR constancy during the follow-up period only holds conditionally on frailty but does not hold marginally with non-null exposure effect. Estimates for unstratified models are indeed valid as marginal effect-measures in pair-matched data if there are no other covariates that need to be controlled and if no censoring occurs [20, 32]. If no observation is censored, estimates from unstratified models are unbiased for the marginal HR parameter (data not shown). As censoring increases, the bias in unstratified PMLE from the marginal HR parameter becomes larger and the coverage probability decreases.
Table 4 shows the results for censorship dependent on matched pair and exposure. The pair effect on censoring alone (from the rows “Censoring rate ratio = 1”) does not invalidate any estimate for null exposure effect but biases unstratified PMLE from both conditional and marginal HRs under non-null exposure effect, as expected from Table 3. Exposure effect on censoring also affects the distribution of unstratified PMLE for both null and non-null exposure effects. This censoring mechanism also makes bias in PMLE for frailty Cox models despite that it models true hazard. Only stratified PMLE, G/H, has no bias in this censoring pattern, which is guaranteed with the assumption (1), as shown in “Appendix 2”.
The shortcomings of stratified and frailty PMLEs are their variability. Even if conditional HR is of primary interest, their RMSE can be greater than that from unstratified models. However, in the moderate sized samples (e.g., n > 250), the variability around conditional HR by stratified and frailty PMLEs can be outweighed by the bias in unstratified models: the “bias” from conditional and marginal HRs. Frailty models also failed to converge a few times in 2000 repetitions.
Matched analysis of the Rotterdam cohort
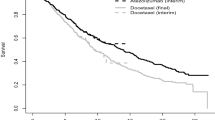
The Kaplan–Meier estimates of relapse-free survival from the original (2982 women) and the propensity-matched (2n = 892 women) Rotterdam cohorts were depicted in Fig. 1. While the unadjusted curves in the original cohorts favored the absence of chemotherapy, the propensity-matched curves adjusting possible confounders reversed the association of exposure and outcome.

The Kaplan–Meier estimates of relapse-free survival from a the original and b the propensity-matched cohorts from the Rotterdam tumor bank dataset
Censoring before the end of the follow-up period was not negligible in the matched cohort, but censoring distribution is similar across exposure groups (Fig. 2): the situation would resemble the simulation pattern 1 (independent censoring). Among 446 pairs in the matched cohort, the number of pairs where the exposed member has shorter observed time and experienced an event (G) was 198 and the number of pairs where the unexposed member has shorter observed time and experienced an event (H) was 135. The PMLE of common HR is G/H = 1.47 with 95% confidence limits exp(log(1.47) ± 1.96 × √(1/198 + 1/135)) = 1.18 and 1.83; these estimates coincide with the result from the stratified Cox model fitting program in SAS/PHREG procedure. On the contrary, marginal HR estimated from the unstratified Cox model with robust sandwich variance estimator in the same matched cohort is 1.33 (95% CI 1.13–1.57). As seen from simulation, the common HR estimate was further from null than marginal HR estimate in this dataset.

The Kaplan–Meier estimates of censoring distribution from the propensity-matched Rotterdam dataset
These results were compared to other marginal or conditional HR estimates adjusting for the seven prognostic variables: Table 5 shows the estimates from inverse-probability weighted Cox model with robust variance estimator, multivariable-adjusted Cox model, and multivariable-adjusted Cox model with inverse-probability weighting and robust variance estimator. Although the target populations were not the same between propensity-matched and inverse-probability weighted analyses [18, 33], the PMLE of stratified and unstratified Cox models from the matched cohort approximate the conditional and marginal estimates from the original cohort, respectively.
Discussion
The PMLE for common HR in matched-pair cohort studies can be expressed by a simple formula based on only two numbers: the number of pairs in which the exposed has a shorter observed time and experienced an event (G) and the number of pairs in which the unexposed has a shorter observed time and experienced an event (H). Such a simple form of HR estimators is unique to PMLE. Corresponding Poisson rate regression may be a stratified Poisson model with common HR, with the likelihood conditional on the total number of events in each stratum (0, 1, or 2), which reduces to binomial likelihood [34]. The CMLE for common HR is the solution of \(\sum\nolimits_{k} {\frac{{Y_{k1} X_{k0} - {\text{HR}} \cdot Y_{k0} X_{k1} }}{{X_{k0} + {\text{HR}} \cdot X_{k1} }}} = 0\), which is dependent on observed time X. It is slightly different from the Mantel–Haenszel rate ratio estimator, \(\frac{{\sum\nolimits_{k} {{{Y_{k1} X_{k0} } \mathord{\left/ {\vphantom {{Y_{k1} X_{k0} } {(X_{k0} + X_{k1} )}}} \right. \kern-0pt} {(X_{k0} + X_{k1} )}}} }}{{\sum\nolimits_{k} {{{Y_{k0} X_{k1} } \mathord{\left/ {\vphantom {{Y_{k0} X_{k1} } {(X_{k0} + X_{k1} )}}} \right. \kern-0pt} {(X_{k0} + X_{k1} )}}} }}\), which approximates the Poisson CMLE around HR = 1.
The current simple expression of stratified PMLE and its relationship with Cτ,pair is also unique to a binary exposure. We could not find any simple expression of estimators of multiple effect-parameters for more than 2 exposure levels, or even a single parameter in the stratified Cox model (i.e., linear effect on log-hazard) for continuous exposure, say, V. In the latter case, an adequate definition of matched-pair overall C-index may be Cτ,pair = Pr(V k1 > V k2| T k1 < T k2, T k1 < τ) (if log-HR β > 0). This may be estimated by redefining a “binary” exposure E, such that E k1 = I(V k1 > V k2) and E k2 = I(V k1 < V k2), and calculating G/(G + H) as if the dataset comes from a pair-matched cohort. However, the limiting value of this statistic is now dependent on the censoring distribution irrespective of the underlying model form. Instead, the stratified PMLE obtained by iterative maximization (e.g., by Newton–Raphson algorithm) of partial likelihood may be used to estimate overall-C; following the similar discussion of Gönen and Heller [35], the average of \(\frac{{\exp (\hat{\beta } \cdot \left| {V_{k1} - V_{k2} } \right|)}}{{1 + \exp (\hat{\beta } \cdot \left| {V_{k1} - V_{k2} } \right|)}}\) across n matched pairs converges to Pr(V k1 > V k2| T k1 < T k2, T k1 < τ) if the assumed linear-effect Cox model is correct and if no tie-event occurs [36]. Although the simple expression of PMLE is not applicable to continuous/multiple-level exposures, the stratified PMLE is still relevant to interpretation of a matched-pair C-index for time-to-event outcomes.
It is well recognized that whenever matching variables in case–control studies are associated with either exposure or disease in an original cohort, unless exposure effect on disease is absent, they must be adjusted in analysis irrespective of whether they are confounders [1, 37]. Unlike case–control studies, ignoring matching in cohort studies generally produce valid point estimates when the matching ratio is constant across strata and no censoring occurs [32, 37]. This phenomenon is due to the design that completely balances the matched variables between exposed and unexposed groups. In the theory of causal diagrams, design unfaithfulness occurs, i.e., exposure and matching variable are independent in the matched subpopulation despite being connected in the causal diagram [37,38,39]. However, when additional confounders are adjusted in the analyses, such cancellation breaks down and ignoring matching variables results in biased estimates [32]. Moreover, as shown in our simulation, if the proportionality of hazards holds given matching variables and if censoring is present, the estimated HR under marginal models would be biased away from both conditional HR and an “average” of time-varying HR [19]. The bias depends on the censoring rate even if events are independently censored. Similar to this phenomenon, if the matching variable is a risk factor for outcome and competing risks or losses to follow-up are associated with both exposure and the matching variable, estimates not adjusting for the matching variables are no longer unbiased even in the null exposure effect [1, 37]. Our simulation also showed that censorship dependent on the exposure and the matched pair invalidates the marginal estimate and statistical test.
Matching is often conducted in analysis stage, especially with estimated propensity scores in order to reduce confounding, as in our real data example. Contrary to actually matched data, analytical subtleties in propensity-matching have been discussed in recent literature. First, whether propensity-matching should adjust for as sampling variation remains controversial [18, 40]. Second, conditional effect parameters are usually not targeted in propensity-matching because conditioning on propensity-matched pairs has little interpretability. Third, at the cost of balancing between exposure groups, propensity-matching discards some proportion of available data. If one is interested in the effect on the exposed (the marginal effect-measure if 1 unexposed is matched on 1 exposed), one can expect more efficient estimates are obtained by differential propensity-weighting for exposed and unexposed groups [41] than marginal modeling with robust variance estimator after propensity-matching. While weighting directly uses the estimated propensity scores from fitted models [42, 43], matching only uses the ranks of estimated propensity scores within an allowable caliper width. As ranks are less sensitive to misspecification of the model form, one may argue the propensity-matching analyses are more robust than estimates using propensity-weighting or outcome-regression, or both [44]. Detailed investigation of this bias–variance trade-off between propensity-matching and weighting for marginal estimates is interesting future work. From these viewpoints, however, a PML estimator of common HR may be of little use along with propensity-matching.
Conclusion
Although common HR itself may have limited value in public health literature because of its noncollapsibility and built-in selection bias [19], the simple and intuitive representation of its estimator would be a useful summary of the exposure effect. The common HR estimator may be a good alternative to the marginal HR estimators if loss-to-follow-up is not negligible and/or depends on exposure and matching variables. Otherwise, survival time or risk comparisons should be used to overcome the problems with causal interpretation of HR [17, 19].
Abbreviations
- CMLE:
-
Conditional maximum likelihood estimator
- HR:
-
Hazard ratio
- OR:
-
Odds ratio
- PMLE:
-
Partial maximum likelihood estimator
References
Rothman KJ, Greenland S, Lash TL. Design strategies to improve study accuracy. In: Greenland S, Rothman KJ, Lash TL, editors. Modern epidemiology. 3rd ed. Philadelphia: Lippincott Williams and Wilkins; 2008. p. 168–82.
Breslow NE, Day NE. Statistical methods in cancer research: the analysis of case–control studies. I ed. Lyon: IARC Science Publishing; 1980.
Greenland S. Applications of stratified analysis methods. In: Greenland S, Rothman KJ, Lash TL, editors. Modern epidemiology. 3rd ed. Philadelphia: Lippincott Williams and Wilkins; 2008. p. 283–302.
Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J Natl Cancer Inst. 1959;22:719–48.
Ejigou A, McHugh R. Estimation of relative risk from matched pairs in epidemiologic research. Biometrics. 1977;33:552–6.
Greenland S, Robins JM. Estimation of a common effect parameter from sparse follow-up data. Biometrics. 1985;41:55–68.
Greenland S. Modeling risk ratios from matched-cohort data: an estimating equation approach. Appl Stat. 1994;43:223–32.
Cummings P, McKnight B, Greenland S. Matched cohort methods for injury research. Epidemiol Rev. 2003;25:43–50.
Cummings P, McKnight B, Weiss NS. Matched-pair cohort methods in traffic crash research. Accid Anal Prev. 2003;35:131–41.
Holt JD, Prentice RL. Survival analyses in twin studies and matched pair experiments. Biometrika. 1974;61:17–30.
Kalbfleish JD, Prentice RL. The statistical analysis of failure time data. 2nd ed. New York: Wiley; 2002.
Klein JP, Moeschberger ML. Survival analysis: techniques for censored and truncated data. 2nd ed. New York: Springer; 2003.
Harrell FE, Lee KL, Mark DB. Tutorial in Biostatistics. Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med. 1996;15:361–87.
Pencina MJ, D’Agostino RB. Overall C as a measure of discrimination in survival analysis: model specific population value and confidence interval estimation. Stat Med. 2004;23:2109–23.
Uno H, Cai T, Pencina MJ, et al. On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat Med. 2011;30:1105–17.
Greenland S, Robins JM, Pearl J. Confounding and collapsibility in causal inference. Stat Sci. 1999;14:29–46.
Greenland S. Absence of confounding does not correspond to collapsibility of the rate ratio or rate difference. Epidemiology. 1996;7:498–501.
Austin PC. The use of propensity score methods with survival or time-to-event outcomes: reporting measures of effect similar to those used in randomized experiments. Stat Med. 2014;33:1242–58.
Hernán MA. The hazards of hazard ratios. Epidemiology. 2010;21:13–5.
Xu R, O’Quigley J. Estimating average regression effect under non-proportional hazards. Biostatistics. 2000;1:423–39.
Schemper M, Wakounig S, Heinze G. The estimation of average hazard ratios by weighted Cox regression. Stat Med. 2009;28:2473–89.
McNemar Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika. 1947;12:153–7.
Agresti A. Categorical data analysis. 2nd ed. New York: Wiley; 2002.
Agresti A, Min Y. Effects and non-effects of paired identical observations in comparing proportions with binary matched-pairs data. Stat Med. 2004;23:65–75.
Sjölander A, Johansson ALV, Lundholm C, et al. Analysis of 1:1 matched cohort studies and twin studies, with binary exposures and binary outcomes. Stat Sci. 2012;27:395–411.
Lin DY, Wei LJ. The robust inference for the proportional hazards model. J Am Stat Assoc. 1989;84:1074–8.
Maldonado G, Greenland S. Interpreting model coefficients when the true model form is unknown. Epidemiology. 1993;4:310–8.
Hjort N. On inference in parametric survival data models. Int Stat Rev. 1992;60:355–87.
Dahlqwist E, Zetterqvist J, Pawitan Y, Sjölander A. Model-based estimation of the attributable fraction for cross-sectional, case-control and cohort studies using the R package AF. Eur J Epidemiol. 2016;31:575–82.
Royston P, Lambert PC. Flexible parametric survival analysis using data: beyond the Cox model. College Station: Stata Press; 2011.
Hernán MA, Hernandez-Diaz S, Robins JM. A structural approach to selection bias. Epidemiology. 2004;15:615–25.
Sjölander A, Greenland S. Ignoring the matching variables in cohort studies: when is it valid and why? Stat Med. 2013;32:4696–708.
Austin PC, Stuart EA. Optimal full matching for survival outcomes: a method that merits more widespread use. Stat Med. 2015;34:3949–67.
Greenland S. Introduction to categorical statistics. In: Greenland S, Rothman KJ, Lash TL, editors. Modern epidemiology. 3rd ed. Philadelphia: Lippincott Williams and Wilkins; 2008. p. 238–58.
Gönen M, Heller G. Concordance probability and discriminatory power in proportional hazards regression. Biometrika. 2005;92:965–70.
White IR, Rapsomaniki E. Covariate-adjusted measures of discrimination for survival data. Biom J. 2015;57:592–613.
Mansournia MA, Hernán MA, Greenland S. Matched designs and causal diagrams. Int J Epidemiol. 2013;42:860–9.
Greenland S, Mansournia MA. Limitations of individual causal models, causal graphs, and ignorability assumptions, as illustrated by random confounding and design unfaithfulness. Eur J Epidemiol. 2015;30:1101–10.
Mansournia MA, Greenland S. The relation of collapsibility and confounding to faithfulness and stability. Epidemiology. 2015;26:466–72.
Stuart EA. Matching methods for causal inference: a review and a look forward. Stat Sci. 2010;25:1–21.
Sato T, Matsuyama Y. Marginal structural models as a tool for standardization. Epidemiology. 2003;14:680–6.
Mansournia MA, Danaei G, Forouzanfar MH, Mahmoudi M, Jamali M, Mansournia N, Mohammad K. Effect of physical activity on functional performance and knee pain in patients with osteoarthritis: analysis with marginal structural models. Epidemiology. 2012;23:631–40.
Mansournia MA, Altman DG. Inverse probability weighting. BMJ. 2016;15(352):i189.
Waernbaum I. Model misspecification and robustness in causal inference: comparing matching with doubly robust estimation. Stat Med. 2012;31:1572–81.
Authors’ contributions
TS conducted simulations and analysis, and prepared the manuscript. TS and MAM jointly contributed to drafting the article. YM helped to interpret the results. All authors read and approved the final manuscript.
Acknowledgements
We thank Dr. Arvid Sjölander for providing helpful suggestion on real data analysis and the reviewers of the manuscript for valuable comments.
Competing interests
The authors declare that they have no competing interests.
Availability of data and materials
The Rotterdam dataset is publicly available from CRAN website. The SAS code corresponding to the data-generating process used in this article can be obtained in Additional file 1.
Funding
This work was supported by Grant-in-Aid for Young Scientists B 16K16015 from the Japan Society for the Promotion of Science (TS) and by Japan Agency for Medical Research and Development (YM).
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Additional file
12982_2017_60_MOESM1_ESM.docx
Additional file 1. Additional simulation results and SAS codes for simulation and for matching women based on estimated propensity scores in the Rotterdam tumor database.
Appendices
Appendix 1: PMLE with tied-event pairs
Table 6 shows the additional types of pairs when tied events occur in the same pair. By convention, when censoring and event simultaneously occur in the data, that pair is treated as if censoring was measured after event: types 10 and 11 (Table 6) are treated as types 3 and 4 (Table 2), respectively. Then, we only have to consider how to treat tie-event (type 12) by each method: the exact, Breslow’s, or Efron’s methods are commonly used [11, 12].
If tie-events are treated by the exact method, the contribution of that type of pair is exp(β)/{1 + exp(β)} + 1/{1 + exp(β)} = 1, which means these pairs do not contribute the partial-likelihood. Thus, we only have to modify the matched-pair common HR estimator as G/H in which type 12-pairs are counted in neither G nor H: G = n 1 + n 3 + n 10 and H = n 2 + n 4 + n 11. On the contrary, if tie-events are treated by Breslow’s methods, the contribution of that pair type is exp(β)/{1 + exp(β)}2, or by Efron’s methods, 2 × exp(β)/{1 + exp(β)}2. This means that the partial likelihood counts type 12-pairs in both G and H: a modified matched-pair common HR estimator corresponding Breslow’s or Efron’s methods is G/H in which type 12-pairs are counted in both G and H (i.e., G = n 1 + n 3 + n 10 + n 12 and H = n 2 + n 4 + n 11 + n 12).
We provide in Table 7 a typical dataset (50 pairs) generated with true HR = 2 with independent censoring (rate = 1) in the main text. To view the impact of tied event data, we rounded the observed time to one decimal place. Among the comparable pairs, n 1 + n 3 + n 10 = 18, n 2 + n 4 + n 11 = 7 and n 12 = 1 (pair 30). Using exact tie-breaking method, G = 18 and H = 7; PMLE of common HR is G/H = 2.57 with 95% confidence limits exp{log(2.57) ± 1.96 × √(1/18 + 1/7)} = 1.07 and 6.16. Using Breslow’s and Efron’s tie-breaking method, G = 19 and H = 8 and the estimate (95% confidence limits) is 2.38 (1.04, 5.43). These data are in perfect accordance with the results obtained by fitting a Cox model stratified on matched-pairs via the PHREG procedure with options “ties = exact” and “ties = Breslow” (default in current version of SAS; “ties = Efron” provide the same result), respectively.
Appendix 2: Equivalence between the limiting value of G/H and C τ with censoring under stratified proportional hazards model
Following the main text, the Cτ estimator G/(G + H) is expressed as
where I(A) is the indicator function (1 if A is true, 0 otherwise). Because Y ke = I{T k1 < min(U ke , τ)}, it is rewritten as
Note that as the pair-number n increases, the denominator and the numerator divided by n 2 converges to \(\Pr \{ T_{{ke_{1} }} < T_{{ke_{2} }} ,T_{{ke_{1} }} < \hbox{min} (U_{{ke_{1} }} ,U_{{ke_{2} }} ,\tau )\}\) and \(\Pr \{ T_{{ke_{1} }} < T_{{ke_{2} }} ,T_{{ke_{1} }} < \hbox{min} (U_{{ke_{1} }} ,U_{{ke_{2} }} ,\tau ),e_{1} = 1,\quad e_{2} = 0\}\), respectively [15]. Therefore, with drop-out before the end of follow-up τ, G/(G + H) converges to conditional probability (3),\(\Pr \{ e_{1} = 1,e_{2} = 0{\text{ in pair }}k\left| {T_{{ke_{1} }} < T_{{ke_{2} }} ,T_{{ke_{1} }} < \hbox{min} (U_{{ke_{1} }} ,U_{{ke_{2} }} ),T_{{ke_{1} }} < \tau } \right.\}\).The limiting value of G/(G + H) is
If U k0 and U k1 are independent of each other and are independent of both T k1 and T k0 within all matched-pair k, Pr{T k1 < T k0, T k1 < min(U k0, U k1, τ)} is
where S Uke (t) is a survival function of U ke . Similarly, the limiting value of H/(G + H) is Pr{T k1 > T k0 | T k1 < min(U k0, U k1, τ) or T k0 < min(U k0, U k1, τ)} = Pr{T k1 > T k0, T k0 < min(U k0, U k1, τ)}/Pr{T k1 < min(U k0, U k1, τ) or T k0 < min(U k0, U k1, τ)} in which the numerator is \(\int_{0}^{\tau } {f_{k0} (t)S_{k1} (t)S_{{U_{k1} }} (t)S_{{U_{k0} }} (t)dt}\). Suppose stratified proportional hazards assumption (1) holds. The limit of ratio of G/(G + H) and H/(G + H), or G/H, is then
which is equal to C τ,pair/(1 − C τ,pair) by following the argument in the main text.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Shinozaki, T., Mansournia, M.A. & Matsuyama, Y. On hazard ratio estimators by proportional hazards models in matched-pair cohort studies. Emerg Themes Epidemiol 14, 6 (2017). https://doi.org/10.1186/s12982-017-0060-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12982-017-0060-8