Article Text

Abstract
Objectives Traditional methods for creating food composition tables struggle to cope with the large number of products and the rapid pace of change in the food and drink marketplace. This paper introduces foodDB, a big data approach to the analysis of this marketplace, and presents analyses illustrating its research potential.
Design foodDB has been used to collect data weekly on all foods and drinks available on six major UK supermarket websites since November 2017. As of June 2018, foodDB has 3 193 171 observations of 128 283 distinct food and drink products measured at multiple timepoints.
Methods Weekly extraction of nutrition and availability data of products was extracted from the webpages of the supermarket websites. This process was automated with a codebase written in Python.
Results Analyses using a single weekly timepoint of 97 368 total products in March 2018 identified 2699 ready meals and pizzas, and showed that lower price ready meals had significantly lower levels of fat, saturates, sugar and salt (p<0.001). Longitudinal analyses of 903 pizzas revealed that 10.8% changed their nutritional formulation over 6 months, and 29.9% were either discontinued or new market entries.
Conclusions foodDB is a powerful new tool for monitoring the food and drink marketplace, the comprehensive sampling and granularity of collection provides power for revealing analyses of the relationship between nutritional quality and marketing of branded foods, timely observation of product reformulation and other changes to the food marketplace.
- big data
- supermarkets
- web scraping
- databases
- front of pack food labelling
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
foodDB is a new database with greater temporal granularity than any other food composition database in the UK.
foodDB collects information on over 100 000 products per week.
Price and promotional information is collected alongside nutritional composition.
foodDB does not account for geographical availability of foods within the UK.
foodDB only collects information on products sold on the websites of the UK’s major supermarkets.
Introduction
Much of nutritional epidemiology is dependent on the conversion of questionnaire-based data on food consumption into nutrient consumption by the use of food composition tables.1 Such methods are often used to estimate the association between nutrient consumption and health outcomes in observational studies2 and to monitor the nutritional quality of food consumed by a population.3 However, food composition tables are expensive to construct and maintain, only cover a small sample of the foods available for consumption and are frequently based on old data, which is problematic for processed foods where formulations change regularly.4 Such limitations can potentially lead to misclassification bias in the observational studies that rely on food composition tables.
A potential way to increase the number of foods included in food composition tables is to include nutritional data taken from food packaging on a large sample of foods.4 Such a method could collate up-to-date nutritional data on a comprehensive set of foods that are purchased within a specific setting, although limited to only the nutritional data that are provided on food packaging. There have been various attempts to collate such databases: by crowdsourcing food label data using mobile phones (eg, FoodSwitch5) or web applications (eg, Open Food Facts6); by collecting data through contact with food manufacturers,7 industry or by periodic audits of foods on the market8; and by public–private partnerships aimed at extending national food composition tables.9–13 However, these databases are limited for research purposes as they do not regularly update nutritional data on products5 6 9–12; do not achieve comprehensive coverage of targeted foods5 6 10–13; require high levels of resources to maintain and update5; do not have transparent methods or adequate audit trails8; or rely on ongoing contributions from the food industry.9–13
This paper introduces foodDB, a terabyte-scale, weekly updated database that collects data on a comprehensive sample of food and drink products available for purchases in all major UK supermarkets, using big data techniques for collection, processing, storage and analysis. Now commonplace in many fields across the business, public, non-profit and scientific sectors, big data refers to any data exhibiting unusual features of any of five dimensions: volume, variety, velocity, volatility and veracity.14 foodDB uses big data techniques to address limitations of other food composition tables and allow for a number of types of research including in-depth investigations of correlations between nutritional and commercial variables (eg, price, promotions) at a single point in time, as well as monitoring the food and drink marketplace longitudinally. Such a database could be used to identify important levers for promoting healthy diets, evaluate the impact of population-level public health policies such as the Soft Drink Industry Levy15 and support monitoring of the nutritional quality of the UK diet by dietary survey, so that changes in nutrient intake can be measured that are due to both change in behaviour and change in the food supply.
The three objectives of this paper are to describe the foodDB database and data collection method; to provide an example of the potential use of foodDB in cross-sectional analyses by analysing the nutritional content of all ready meals and pizzas that were available for purchase in March 2018 in the six major UK supermarkets; and to provide an example of the potential use in longitudinal analyses by analysing the change in availability and healthiness of pizzas over the course of the first 6 months of full data collection.
Methods
Data collection, processing and storage
foodDB consists of a relational database populated by custom-built software to collect, process and store data on food and drink products available to buy online in the UK, including alcoholic beverages, and not including supplements. A full list of the main categories from which data are collected is provided in the online supplementary material. Data are collected weekly by the foodDB software on all products available in the online offering of UK supermarkets, and are stored in the foodDB database. Each instance of data collection from each supermarket is referred to as a ‘snapshot’; for each snapshot, foodDB collects data in a staged way, as illustrated in figure 1. Starting at the supermarket’s main webpage, category trees are built, generating and storing a list of category hierarchies. Category hierarchies in all supermarkets can be grouped into four levels of classification, which approximate to ‘department’, ‘section’, ‘aisle’ and sometimes ‘shelf’. For example, in Sainsbury’s, chilled pizzas are all found under the ‘Pizza’ aisle: Chilled (department) -> Pizzas and Garlic Bread (section) -> Pizza (aisle). All chilled ready meals in Asda are found under the ‘Ready Meals’ aisle, although this aisle additionally has a number of shelves to distinguish between different ready meal types: Chilled Food (department) -> Ready Meals & Soup (section) -> Ready Meals (aisle) -> Indian/Italian & Mediterranean/Traditional/Vegetarian etc. (shelf). For each snapshot, foodDB collects detailed category information; each category’s product pages are then used to create a list of all product names and URLs (website addresses) for that category; the lists of product–category pairs, and unique product names and product URLs are collected and stored; the URL for each unique product is then used to load each product page, and product data are extracted, processed and stored. The data collected for each product include the following, where available: product name; price; serving size; product size; promotion details; supermarket’s own product code (a numeric identifier for that product, different to the barcode and embedded within the webpage); product image; front-of-pack nutrition labelling data (% reference intake and nutrition traffic light labels); nutrient declaration data (referred to as a nutrition table on each website); ingredients; dietary information (eg, ‘suitable for vegetarians’); allergen information; storage information; brand; manufacturer; and the date and time of data collection. Each product’s supermarket ‘product code’ is used for identification of and tracking unique products over time, supplemented by product name, URL and image where necessary. Within foodDB, internal unique identifiers are used to identify individual instances of each product, combinations of the product code for a particular snapshot. In addition to these data, the full HTML text of each product page with date and time of data collection is stored separately for audit and data verification purposes, and to provide a mechanism for re-extracting data in the event of errors at the time of data collection, for example, in the case of an unexpected change to the supermarket web page structure.
Supplemental material

Dataflow of snapshot data generation in foodDB.
All collection and processing code is written in Python V.2.716 and the foodDB software is object-oriented and modular. A set of core classes and a helper library provide the main functionality for data collection, processing and storage. Subclassing17 (class inheritance) allows for the same core code to be used for different supermarkets that have different structures and page loading mechanisms, with only small unique sections of code required to handle the specific requirements of each supermarket, rather than an entire custom codebase being required for each. The object-oriented design means that foodDB can easily adapt to and handle changes in individual supermarket websites as they are updated over time, and also allows new data sources (eg, other supermarkets or food suppliers) to be added as required. The well-established open source Python libraries requests18 and selenium19 allow foodDB to make large numbers of sequential calls to website servers, each receiving HTML text for processing and data extraction: requests is used for websites that return plain HTML from a call to a server, while selenium facilitates this process for dynamically generated supermarket webpages, simulating the in-browser page-generation. Errors, for example, caused by pages failing to load, scheduled supermarket website maintenance or individual products not being available to purchase at the time of loading, are caught and reruns are carried out to try to fill in these data gaps. Data collection has inbuilt pauses to stop any excess load on the website servers, which has the added benefit of reducing errors. To reduce errors from occurring, and to allow for efficient maintenance of the foodDB software, a comprehensive testing suite has been created using pytest20 which identifies errors caused by changes to the website structures, and ensures that new features and fixes perform as required, and do not have any unintended consequences. The foodDB database uses the open source relational database management system MySQL V.5.721 with the InnoDB storage engine22 to allow transactions, row-level locking, foreign key relationships and increased data integrity.
Data analysis
For cross-sectional analysis of ready meals and pizzas, a single weekly snapshot of the six major UK supermarkets (Tesco, Asda, Sainsbury’s, Morrisons, Waitrose, Ocado) taken in March 2018 was used. These six supermarkets account for over 75% of the grocery market in the UK.23 All products available within supermarket categories of ready meals and pizzas were manually curated to exclude products that would not be eaten as a standalone meal (eg, pasta sauces, burgers without buns, garlic bread and so on). In order to define product groups for the example analyses, we first examined the existing supermarket hierarchies to select all potential ready meal and pizza products, and then filtered these using regular expressions to include/exclude specific subcategories and products. The ready-meal product categories selected required particular care due to the fact that they contain a diverse range of products, including whole meals (eg, vegetable masala and rice), components of such meals (eg, a portion of precooked rice) and supplementary items (often within meal deals, eg, small pots of chutney, soft drinks and so on). Duplicate products (ready meals or pizzas of a particular brand and type that appear in more than one supermarket) were removed. Using data extracted from the websites, a traffic light ‘healthiness’ score was generated for all ready meals and pizzas. This score ranks the perceived healthiness of foods based only on the front-of-pack traffic light colours for total fat, saturated fat, total sugar and salt, based on the results of a choice experiment conducted with supermarket shoppers.24 We assessed the distribution of each traffic light nutrient and the traffic light healthiness score across the products.
To test the relationship between price and levels of fat, saturated fat, sugar and salt, the full dataset without removal of duplicates was used (since the same product in different supermarkets can have different prices). We categorised the dataset into the lowest 50% and highest 50% of products by price (£ per 100 g) and looked at differences in traffic light healthiness scores between the two categories using Mann-Whitney tests.
For the longitudinal analyses, we used data on all pizzas appearing in the six supermarkets between 30 November 2017 and 1 June 2018, which included 27 weekly snapshots (NB: the Tesco dataset contained only 26 snapshots in this time period, due to errors in data collection on the week of 30 December 2018). To evaluate the stability of the pizza market over this time period, all products were categorised into four groups depending on their availability: products present in every collected snapshot; products usually present (defined as being available in all snapshots except gaps of 1 or 2 weeks); products with line change (defined either as products entering the market—first time available after the initial snapshot—or leaving the market—last time available before the final snapshot); and products with any other pattern of availability.
To evaluate the degree of product reformulation over this time period, the percentage of pizzas that changed their content of at least one of the four traffic light nutrients (total fat, saturated fat, total sugars and salt) were calculated, as well as the percentage where the change in nutritional content was enough to prompt a change in a traffic light colour for the front-of-pack label.
Analyses were carried out using MySQL and Python V.2.7 using the Python libraries numpy V.1.1425 and Pandas V.0.22,26 and visualisations created using Matplotlib V.2.2.27
Patient and public involvement
There was no patient or public involvement in this analysis.
Results
Descriptive statistics
Between 30 November 2017 and 5 June 2018, foodDB collected full snapshots for 27 weeks of full data collection for six UK supermarkets, consisting of 3 193 171 food or drink records. In one single time point (all snapshots starting on 2 March 2018) foodDB obtained 97 368 product records (table 1). Across the course of data collection, we have collected 128 283 distinct products measured at multiple time points (in this paper, a ‘distinct product’ is defined as a unique combination of product and supermarket). Product page data were collected for over 99.5% of products identified from the supermarkets at the single timepoint. Five of the six online supermarkets contained 13 000–16 000 food and drink products. The exception was Ocado (an online only retailer) that held just under 24 000 products. Data on ingredients were captured for >80% of the food and drinks, and nutrient declaration tables28 were captured in over 85% of products. Data for energy, protein, carbohydrate, fat, sugar, salt and saturates were present in over 90% of these tables, data for fibre in 70%, while data for other nutrients were present in fewer than 7% of tables. A full list of nutrients reported and stored in the foodDB snapshot at this single timepoint can be found in the online supplementary material.
Summary of data collected in a single foodDB snapshot
A total of 140 aisle categories across both fresh and frozen sections of the six supermarkets were identified as either ‘Ready Meal’ or Pizza in foodDB for the 2 March 2018 snapshots, which contained 2699 ready meals and pizzas, comprising between 1.9% and 3.7% of each supermarket’s product range. Excluding products without complete nutrition and price data, and clustering to remove duplicate resulted in a dataset of 2139 unique ready meals and pizzas. One thousand five hundred and eighty-four (74.1%) of these clustered products were supermarket own-brand, and 555 (25.9%) were branded products. All products had unique supermarket product codes, while 7% of products had minor name changes, and 9% had URL changes. A dataflow with the numbers of products at each stage of filtering and classification is available the online supplementary material.
Nutritional analyses
Figure 2 shows the distribution of total fat, saturated fat, total sugars and salt per 100 g across all ready meals and all pizzas. Boundaries for classification of traffic light levels29 are illustrated with vertical green and red lines superimposed on the graphs, with the proviso that a product may also have a ‘red’ classification for a particular nutrient due to the per-serving value.

Distribution of nutrients across all ready meals and pizzas at a single timepoint. Distribution of grams of (A) fat, (B) saturated fat, (C) total sugars, (D) salt per 100 g across all ready meals and pizzas in a single week of foodDB snapshots. Vertical lines illustrate the 100 g value limits for calculation of green and red traffic light labels.
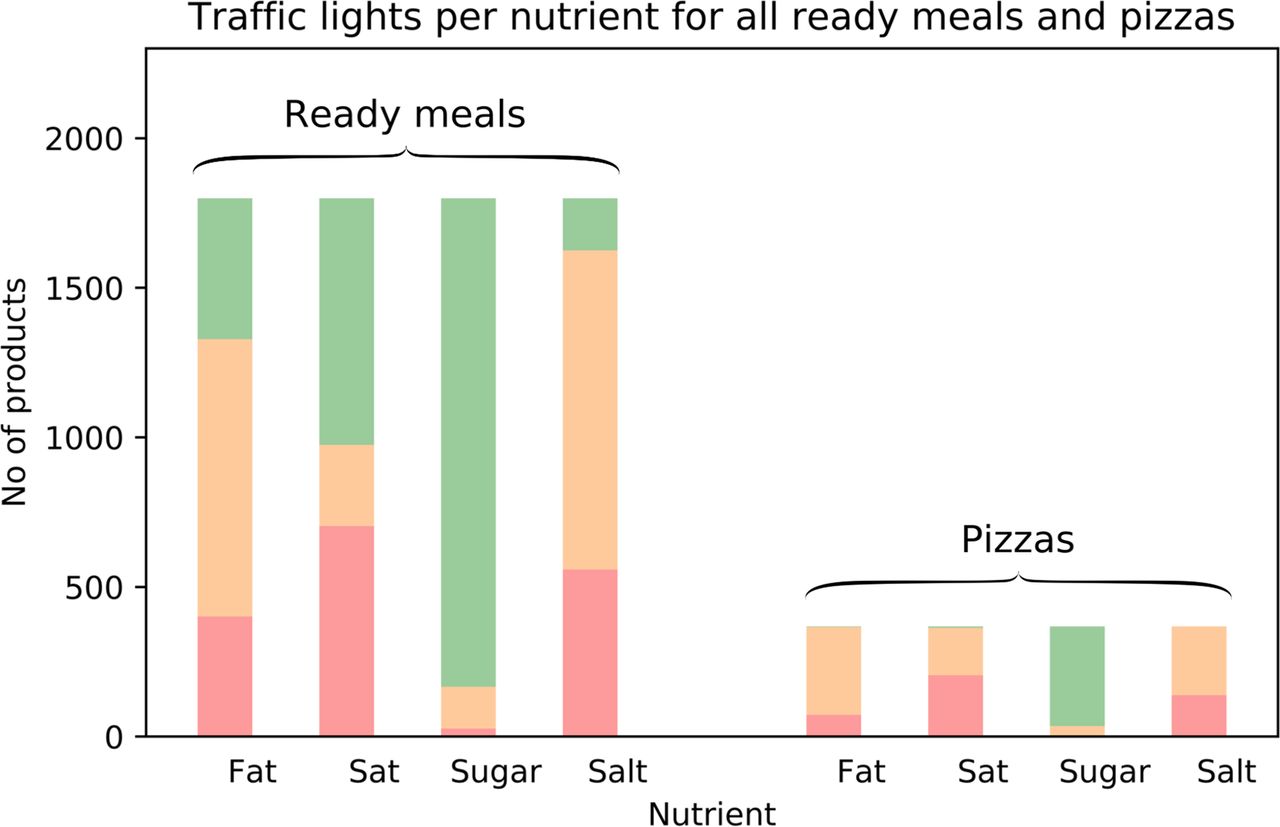
Figure 3 shows the calculated traffic light colours associated with ready meals and pizzas and quantifies what might be expected of those products: for example, that most ready meals and pizzas are low in sugar (91.6% (90.5%–92.7%) of these products have sugar levels that would qualify for a green traffic light). The derived traffic light healthiness scores are scaled from 0 (least healthy, for a product with four red lights) to 1 (most healthy, for a product with four green lights)—ready meals and pizzas showed a reasonably uniform distribution over this score (see online supplementary material) indicating that there is substantial choice available to purchasers in this food category.

Distribution of traffic light colours across all ready meals and pizzas at a single timepoint. Distribution of traffic light colours across all ready meals and pizzas in a single week of foodDB snapshots.
Correlations between price and levels of fat, saturated fat, sugar and salt
The median price for ready meals was 75p per 100 g and for pizzas was 65p per 100 g. These values were used to classify products into two groups, lower cost and higher cost. The distribution of price is shown in the online supplementary material. Table 2 compares the levels of fat, saturated fat, sugar and salt between low-cost and high-cost ready meals and pizzas, using all 2033 ready meals and 534 pizzas that had both nutrition and price data (2567 products in total, including duplicate products from different supermarkets). For ready meals, the lower price products had significantly lower quantities of all four traffic light nutrients (p<0.001). For pizzas, there was no difference in fat, saturated fat and sugar levels, but lower price pizzas tended to have lower salt levels (p<0.001).
Relationship between price (£ per 100 g) and levels of fat, saturated fat, sugar and salt for 2567 ready meals and pizzas
Longitudinal analysis of healthiness of all pizzas
The dataset contained 903 distinct pizzas over all six supermarkets, of which 43.3% (40.1%–46.5%) were found to be available in every week over the 6 months. There was considerable churn in the pizza marketplace, shown in table 3, with 3 in 10 (29.9% (26.9%–32.9%)) pizzas over the 6 months either being discontinued or introduced as a new (or returning) product. Figure 4 illustrates changes in product availability over time using heatmaps for each supermarket, with rows representing products and columns representing weekly snapshots; each square represents either presence (sand-coloured) or absence (black) of a product in a snapshot.
Changes in pizza ranges for each supermarket between 30 November 2017 and 1 June 2018

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Heatmap of availability of pizza products for six supermarkets over 6 months. Heatmap illustrating changes in pizza product range for six supermarkets over 6 months (27 weeks) of foodDB data collection. Columns represent weekly snapshots, and rows represent a product’s availability in that snapshot. Each sand-coloured square shows that the product is available, while each black-coloured square means that product is not available in that snapshot.
As shown in table 4, changes to the nutritional composition of 10.8% (8.6%–13.0%) of pizzas were observed over 6 months. Over a third of the changes resulted in a change to the (calculated) front-of-pack label traffic light colours for the product.
Changes to nutritional composition of pizzas between 30 November 2017 and 1 June 2018
Discussion
Using automated techniques to collect data from online supermarkets can result in food composition tables with far greater coverage and temporality than have been achieved in the past, allowing for more detailed evaluation of the grocery marketplace. Such granularity can reveal insights about the constantly changing set of products available in the UK marketplace (our example case of pizzas showed that 3 in 10 products were either discontinued or introduced to product ranges over just 6 months), and the rapid rate of reformulation within the marketplace (over 1 in 10 pizzas changing nutritional content within the space of 6 months). The greater coverage allows for a clearer description of the nutritional quality of foods available in the marketplace, and an assessment of the association between nutritional quality and key variables that affect purchasing behaviour, such as price. Analyses of this large and dynamic dataset can reveal insights such as the differences in level fat, saturated fat, sugar and salt between lower-priced and higher-priced ready meals, and of the variability of available products, and changes in their composition over time, as illustrated here.
The automated data collection process and the regularity of data capture provides foodDB with distinct analytical advantages compared with other large food composition databases of branded foods. The two FoodSwitch databases, which were initially primed by a commercial database and then supplemented with data collected from crowdsourcing currently contain ~100 000 and 60 000 food and drink items for the UK and Australia, respectively.5 Also using crowdsourcing, Open Food Facts, is a free-to-use web application that contains data on over 700 000 products worldwide since 2012, including over 300 000 from France and 150 000 from the USA.6 foodDB collects data on over 90 000 food and drink items every week, collating >125 000 distinct food and drink items available at some point over the 6-month data collection period (and over three million observations of food or drink items in total). A significant advantage of foodDB over crowdsourcing is that foodDB is updated systematically and consistently. This ensures that new products, discontinued products or product changes (eg, to formulation, price or promotion) are captured.
Another way to compile branded food datasets is to build partnerships with the food industry: such datasets are available in the USA9–12 and Belgium13 and rely on co-operation from the food industry to update data occasionally (eg, the USDA Branded Food Dataset is updated annually9). The granularity of such datasets is not sufficient to capture the dynamic food market, where products are discontinued, new products emerge and old products are reformulated frequently, for example, in the USA it has been estimated that 20 000 new food products emerge each year, of which only 10% are still available after 3 years4 and we show that 30% of pizzas available at some point in a 6-month period are new or discontinued products. This churn in pizza ranges is also reflected in the numbers of total distinct products collected; while we have collected 128 283 distinct products over 6 months, each single weekly snapshot contains only ~95 000 products. A further advantage of foodDB over such datasets is that it is capable of capturing data on other variables that define the food purchasing environment, such as price, promotion and labelling.
foodDB is not the first project automatically to collect and store data from UK online supermarkets. This approach is also used by price comparison websites (eg, MySupermarket30), market research companies (eg, BrandView31) and by Internet Archive32—a non-profit organisation that collects and stores webpages, currently holding over 279 billion pages including many from online supermarkets between 2011 and the present day. The datasets built by price comparison websites are not available to researchers, and while market research databases are made available commercially, datasets may be incomplete, contain inconsistent data, lack audit trails and details on their compilation are unclear. The Internet Archive has a substantial archive of supermarket webpages from 2011 to present; however, it is far from comprehensive, with HTML pages for many products only collected once, if at all. As a proof of concept, the foodDB codebase has been adapted to collect data on all soft drinks from UK online supermarkets collected in the Internet Archive, using foodDB functionality to process, clean and store individual product details. The usage of such data from commercial websites for research purposes, such as in foodDB, is covered by a document published by the UK Government’s Intellectual Property Office in October 2014 entitled ‘Exceptions to copyright’,33 which contains a section on ‘Text and data mining for non-commercial research’. This section of the document states ‘ An exception to copyright exists which allows researchers to make copies of any copyright material for the purpose of computational analysis if they already have the right to read the work (that is, they have ‘lawful access’ to the work)’.
A core strength of foodDB is its flexibility to respond to an ever-changing online supermarket environment. The foodDB software is object-oriented and modular. A core set of classes provides the mechanisms for collection, processing and storage of all data, while subclasses allow for the same code to be easily adapted and modified using inheritance to deal with individual differences between supermarket websites. This allows for minimal interruption to data collection when individual supermarket websites change, and also allows for new data sources/online providers to be added as required. While only the full datasets for six supermarkets over 6 months are reported here, full or partial data have also been collected for four other online supermarkets/suppliers Iceland, Marks and Spencer, Tesco Ireland and Cook—using this same core codebase and work is in progress to incorporate these and others into foodDB. In addition to intracountry analyses, this expansion of foodDB will allow for in-depth analyses of food and drink marketplaces between countries.34 foodDB is able to extract ingredient and nutrient data for a high percentage of products, although we currently make the assumption that data provided online is correct. This assumption is supported by the requirement in the Consumer Rights Act 201535 36 which requires companies in the UK ensure that goods ordered online must be as described, fit for purpose, and of satisfactory quality. Further, European Union (EU) legislation requires that labelling is consistent between online purchases and buying in-store.37 While the European Union legislation also requires reporting of certain nutrients, this is, not an exhaustive list, and is reflected by the fact that the foodDB snapshots reported are able to report data extraction of major macronutrients for over 90% of products, but under 10% for other nutrients. In addition to monitoring and analysis of the food and drink marketplace, rather than replacing databases currently used for dietary surveys, we believe foodDB is an important data source for providing up-to-date macronutrient data. We are also investigating the potential for appending averaged or estimated micronutrients in order to enhance foodDB for such research purposes.
Capturing local geographical variability of food and drink availability within individual online supermarkets is a current limitation of foodDB. Initial analyses have shown that some products are only available for purchase in specific regions of the UK, as well as showing regional differences in price and promotions of some products. foodDB currently collects data on the core set of products only, and future work will address these regional variations.
At present, the size of foodDB means that conceptually straightforward tasks (eg, linking products sold in different sizes, or different brands of the same product) require considerable resources to be completed manually, which restricts the scope of possible analyses. For example, while it was possible to classify and verify a single snapshot of ready meals in foodDB for the cross-sectional analyses reported here through a combination of computational and manual methods, the resources required to process a large number of snapshots for the longitudinal study was prohibitive. The pizza categories, like others such as cereals and soft drinks, are well defined, and require little manual processing, which allowed us to conduct longitudinal analyses on this category. Work is ongoing to applying machine learning techniques to the processing stage of foodDB, which would allow for automatic mapping of categories and subcategories in a validated foodDB hierarchy, allowing for easier comparison across ranges and time. This work will also allow for the automatic identification of duplicate products across supermarkets, for example, the same branded soft drink available for purchase in multiple stores. Including these features will require a degree of manual classification in order to train a classification model, but will then run automatically, removing the need for human involvement in all but edge cases. Further improvements to foodDB also includes increasing the number of derived variables such as the Food Standards Agency (FSA)/Ofcom nutrient profiling score used to distinguish between foods that can and cannot be marketed to children.38 Creating scores with the FSA model requires data from the nutrient composition table, and a measure for the fruit, nut and vegetable (FNV) content for each product, extracted from the ingredient list. The formatting of ingredient lists is highly inconsistent, and often the FNV data are not included, thus making calculation of the FSA score problematic. Current work on foodDB will improve the ingredient parsing to extract FNV data wherever possible, and where there are missing data, use an appropriate measure, for example, the k-nearest neighbour algorithm, to estimate the FNV value and thus calculate the product’s FSA score. Incorporating a method for systematically calculating these scores will allow us to more accurately assess nutritional quality, across and between large numbers of products over time. foodDB is a methodological step forward for food composition databases, which are the bedrock of nutritional epidemiology. The first 6 months of data collection have demonstrated that automatically scraping data from online supermarkets can produce food composition databases with sufficient accuracy, transparency, granularity, flexibility and regularity to monitor a highly dynamic food and drink marketplace, to reveal important relationships between food marketing and nutrition and to support measurements of dietary quality over time that incorporate changes in both food consumption and the nutritional composition of commonly consumed branded foods.
Acknowledgments
Tesco data were sourced from the Tesco supermarket website at https://www.tesco.com/groceries/. Sainsbury’s data were sourced from the Sainsbury’s supermarket website at https://www.sainsburys.co.uk/shop/gb/groceries. Asda data were sourced from the Asda supermarket website at https://groceries.asda.com/. Waitrose data were sourced from the Waitrose supermarket website at https://www.waitrose.com/ecom/shop/browse/groceries. Morrisons data were sourced from the Morrisons supermarket website at https://groceries.morrisons.com/. Ocado data were sourced from the Ocado online supermarket website at https://www.ocado.com/.
Footnotes
Contributors RAH contributed to conception and design of the project and research questions, architecture and development of the software and database, statistical analysis and interpretation of data, drafting the manuscript, obtaining funding. PS contributed to design of the project and research questions, statistical analysis and interpretation of data, drafting of the manuscript, obtaining funding. VA contributed to data processing and analysis, interpretation of data, critical revision of the manuscript. MR contributed to interpretation of data, critical revision of the manuscript, obtaining funding, supervision. All authors have approved the submitted manuscript.
Funding This work was supported by a pump priming research grant from the Nuffield Department of Population Health at the University of Oxford, and is currently supported by the NIHR Biomedical Research Centre at Oxford. PS is supported by a British Heart Foundation fellowship (FS/15/34/31656). MR is supported by the British Heart Foundation (006/PSS/CORE/2016/OXFORD).
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Data sharing statement Anonymised datasets used in the analyses are available upon request. If you believe foodDB data would be of value to your research, please get in touch with the authors via email. Use of foodDB data is only possible for non-commercial purposes.
Patient consent for publication Not required.