Article Text

Abstract
Objectives Administrative databases with dedicated coding systems in healthcare systems where providers are funded based on services recorded have been shown to be useful for clinical research, although their reliability is still questioned. We devised a custom classification of procedures and algorithms based on OPCS, enabling us to identify open heart surgeries from the English administrative database, Hospital Episode Statistics, with the objective of comparing the incidence of cardiac procedures in administrative and clinical databases.
Design A comparative study of the incidence of cardiac procedures in administrative and clinical databases.
Setting Data from all National Health Service Trusts in England, performing cardiac surgery.
Participants Patients classified as having cardiac surgery across England between 2004 and 2015, using a combination of procedure codes, age >18 and consultant specialty, where the classification was validated against internal and external benchmarks.
Results We identified a total of 296 426 cardiac surgery procedures, of which majority of the procedures were coronary artery bypass grafting (CABG), aortic valve replacement (AVR), mitral repair and aortic surgery. The matching at local level was 100% for CABG and transplant, >90% for aortic valve and major aortic procedures and >80% for mitral. At national level, results were similar for CABG (IQR 98.6%–104%), AVR (IQR 105%–118%) and mitral valve replacement (IQR 86.2%–111%).
Conclusions We set up a process which can identify cardiac surgeries in England from administrative data. This will lead to the development of a risk model to predict early and late postoperative mortality, useful for risk stratification, risk prediction, benchmarking and real-time monitoring. Once appropriately adjusted, the system can be applied to other specialties, proving especially useful in those areas where clinical databases are not fully established.
- clinical audit
- quality in health care
- cardiac surgery
- risk management
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
We produced a detailed classification of OPCS codes relevant to cardiac surgery.
We used the classification to identify cardiac surgery operations performed in England over a long period from an administrative database.
Compared with previous studies, we achieved a higher level of detail in our classification, with the aim of analysing specific subgroups of operations.
The comparison with clinical data provided several layers of control over the quality of our work.
Information in administrative databases largely depends on the quality of the source, the clinical notes.
Introduction
Administrative data are collected by organisations involved in healthcare for the purposes of registration, transaction and record keeping during the delivery of a service. Importantly, such information is also used to provide reimbursement for hospitals under the payment by results (PbR) system. This is achieved through the translation of information about patients’ diagnoses and any interventions they received into codes in a standardised format by formally trained clinical coders. In the UK, OPCS Classification of Interventions and Procedures version 4.7 is the system used to code interventions, and ICD-10 the system for diagnoses. Each admission may contain several episodes, corresponding to the care provided under a specific consultant, and within each episode, the aforementioned codes are recorded.
Employing administrative data for clinical research has been proposed on numerous occasions; however, not being intended as a primary source for such purposes, their use remains controversial. Many of the issues raised by Aylin et al regarding the reliability of the data, whether clinical records can be coded accurately and used in clinical research prior to the full introduction of PbR in 2009/10 have been addressed via audit.1 2
Despite these criticisms, administrative databases are increasingly used in the quality improvement cycle in several countries. In England, administrative data contained in Hospital Episode Statistics (HES) are used quarterly to monitor mortality across trusts by means of the Summary Hospital-level Mortality Indicator, which is the ratio between the actual number of patients who die following hospitalisation and the number that would be expected to die on the basis of average England figures, given the characteristics of the patients treated there.3
More recently, the Get It Right First Time (GIRFT) programme has been commissioned by UK’s National Health Service (NHS) Improvement with the aim of improving the quality of the service through the reduction of variation between providers. GIRFT used HES among other data sources to benchmark performance. The workflow for cardiothoracic surgery starts from the identification of operations, using Healthcare Resource Groups, a grouping of healthcare services based on the use of a similar amount of resources.4
At a more local level, University Hospital Birmingham Quality and Outcome Research Unit has developed a number of Specialty Quality Indicators, reviewing monthly variations in performance across several specialties, with the purpose to enable the quality of care delivery to be measured and improved.5
In a paper published recently, we demonstrated that HES data can be used to generate accurate risk prediction models assessing early and late mortality after cardiac surgery.6 The benefit of using administrative data is that they collect information on powerful prognostic factors which are not usually included in disease-specific registries, such as previous emergency admission to hospital, the presence of medical comorbidities and level of social deprivation. Furthermore, these data are inexpensive, promptly and widely available, and represents real-world treatment settings in unselected populations. Finally, long-term follow-up can easily be obtained through linkage to other central databases.
In order to obtain information with a sufficient level of detail, the codes must first be retranslated into a separate catalogue of clinically useful categories. We therefore set out to devise a custom classification of procedures and algorithms based on OPCS, enabling us to identify open heart surgeries from the English administrative database, HES.
Methods
Custom classification of OPCS codes
Most codes relevant to cardiac surgery belong to OPCS chapters K (Heart) and L (Arteries and Veins), with some additional codes from chapters Y and Z (Methods and Site of Operation, respectively).
We grouped together the codes describing coronary artery bypass grafting (CABG), procedures on heart valves—differentiating between target valve and replacement or repair—major aortic surgery, transplant, ventricular assist devices and other less commonly performed operations. Transcatheter aortic valve implants/replacements (TAVI/TAVR) were identified by a combination of OPCS codes for aortic valve replacement (AVR), and additional Y codes (tables 1 and 2).
Classification of OPCS codes by group of procedures
Classification of OPCS codes relative to heart valve surgery
Data extraction and validation with local data
Data were extracted from the local administrative database (ie, Patient Administrative System [PAS]) using OPCS, ICD-10 and relevant consultant treatment specialty codes. Clinical data were collected from the local cardiac database (ie, Patient Administrative and Tracking System [PATS], provided by Dendrite) using clinically named procedures. Only admissions containing episodes under a consultant in cardiac surgery were included, while congenital surgery was excluded using both list of OPCS and ICD-10 codes (Q2).
The Jaccard Similarity Index was applied to compare the data selected from these two data sets which included all cardiac patients, and the following subgroups: patient groups as described in the Society of Cardio-Thoracic Surgery (SCTS) bluebook7 and patients having other named operations with substantive numbers. The Jaccard Similarity Index is the size of the intersection of two sets divided by the size of the union of two data sets and treats each data set in the comparison equally. In this instance for comparing data selected from the PATS and PAS data sets, the Jaccard Similarity Index was deemed the most natural similarity index to use as the objective was to measure data set overlap (figure 1).
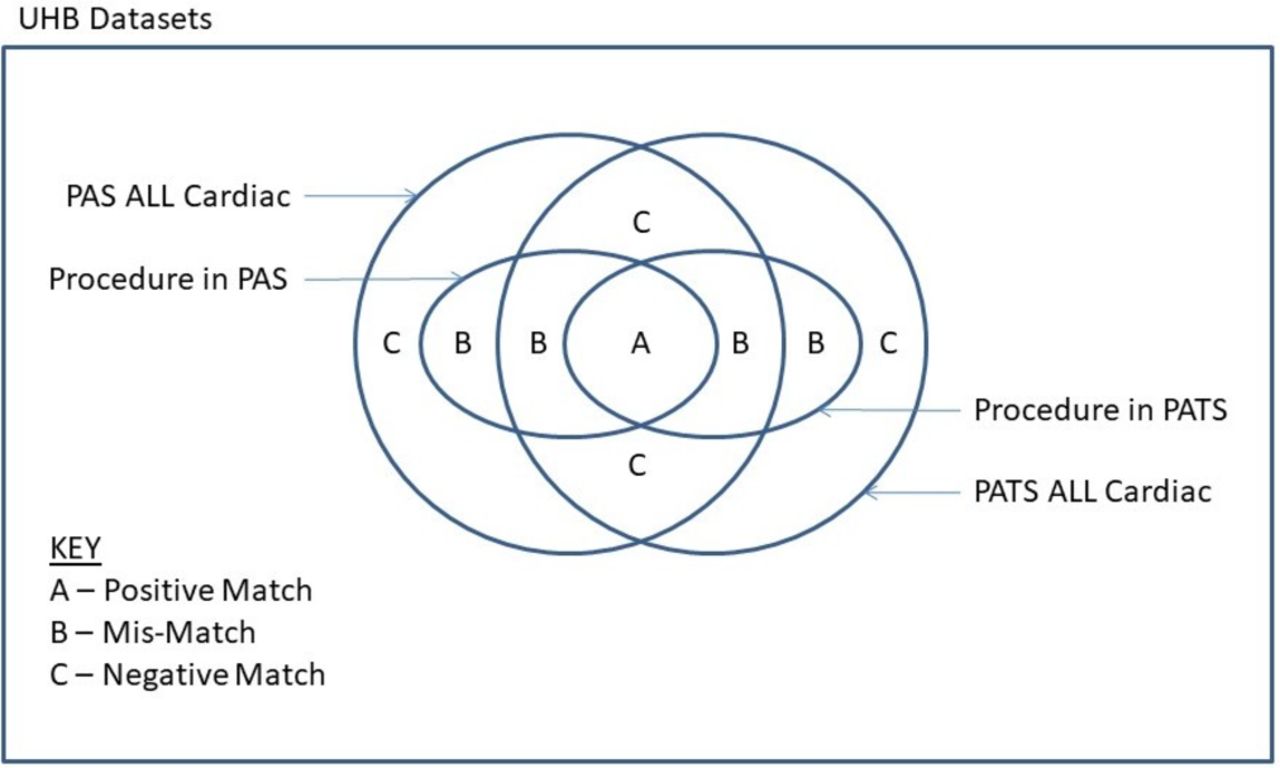
{kind=link}
Venn diagram illustrating the matching at local level between PAS (the administrative data set) and PATS (the clinical database). PAS, Patient Administrative System; PATS, Patient Administrative and Tracking System; UHB, University Hospital Birmingham.
The sensitivity of the data sets alignment was explored under clinical and coding guidance by modifying the set of codes in the PAS data set. The final code selection was validated by a senior cardiac surgeon.
Validation with national clinical data
To check the validity of the selected codes, we cross-referenced national numbers extracted from HES against country-wide figures publicly made available by the SCTS.
Data protection
This study was registered as an Audit with the Clinical Audit Team on the University Hospital Birmingham Clinical Audit and Registration Management System.
For information governance reasons, all figures related to frequencies≤5 were substituted with the symbol *, to avoid potential patient identification.
Patient and public involvement
Patients or public were not involved, as we worked with data already collected by trusts for reimbursement purposes.
Results
Patients having cardiac surgery were identified using a combination of procedure codes (having at least one principal code as listed in table 1), age over 18 and consultant treatment specialty included cardiothoracic surgery, cardiac surgery and thoracic surgery. Sensitivity analysis using ICD-10 diagnostic codes in addition to OPCS codes did not improve alignment between PAS and PATS datasets. Applying the custom classification to HES, we identified a total of 296 426 cardiac surgery procedures performed in England over a 11-year period (April 2004–March 2015). Unsurprisingly, the majority were CABG, AVR, mitral valve repair and aortic surgery (table 3).
Number of procedures identified in HES in the financial years 2004–2015
Operations selected from PAS data set over the more recent period (ie, April 2012—March 2015) largely matched against PATS; the correspondence was especially high for CABG, valve, major aortic surgery, transplant and ventricular assist devices (table 4, figure 1).
Comparison between PATS (clinical) and PAS (administrative) data at University Hospital Birmingham in the financial years 2012–2015
In the analysis of coding accuracy at individual trusts level over the years, we report the number of surgeries in the SCTS bluebook divided by counts derived from HES (tables 5–8). In table 5, the ratio of SCTS to HES counts before the full introduction of PbR in 2009 is higher than after 2009. The effect of coding practice is particularly noticeable for trust 1. In 2009, trust 1 had a ratio of 1.48 and in 2010, the ratio fell to 1.08. Other anomalies include the ratio spiking during 2013 for trusts 7 and 20. Overall, results across all years are summarised in table 9. There is a good overall match particularly for CABG (IQR 98.6%–104%), AVR (IQR 105%–118%) and mitral valve replacement (IQR 86.2%–111%).
Matching in individual trusts, for CABG, AVR, mitral procedures and combinations of these, expressed as ratio of number in HES over number in SCTS bluebook
Matching in individual trusts for CABG, expressed as ratio of number in HES over number in SCTS bluebook
Matching in individual trusts for aortic valve replacement, expressed as ratio of number in HES over number in SCTS bluebook
Matching in individual trusts for mitral procedures, expressed as ratio of number in HES over number in SCTS bluebook
Distribution of matching across all trusts in England, divided by procedure groups
Furthermore, the data extracted from HES using the procedure classification (tables 1 and 2) accurately identified the trusts that are known to provide cardiac surgery in England also including a small number of operations by private providers.
Discussion
There is increasing evidence assessing the use of administrative data in clinical research. Although there are concerns that this data lack reliability, we set out to identify cardiac operations in the major administrative database in use in England and validated this against clinical data. It is our hope that this work will lay the foundations for basis of a risk-prediction model that can be applied to all clinical specialities.
Principal findings
With our classification of procedures from OPCS codes, we were able to identify the most commonly performed adult cardiac surgery operations in an administrative database with over 90% precision. The addition of ICD-10 codes was deemed unhelpful possibly due to only loose alignment between diagnoses and procedures. AVR, for example, may be indicated in patients with valve stenosis, valve regurgitation or endocarditis, while heart failure may be treated by CABG, mitral repair, transplant and more.
Strengths and weaknesses of the study
Using OPCS codes only, procedure classification was still high for the most common procedures (ie, CABG, AVR and mitral replacement). Significant over counting in AVR was possibly due to TAVI being classified as regular AVR. A larger degree of imprecision was found when distinguishing between mitral repair and replacement; likely due to miscoding of prosthetic rings as valve implant (table 9).
The main concern when using administrative data sets for research focus is the accuracy of the data, as they are conceived for different purposes. An independent survey of 40 trusts was commissioned by NHS to look into the coding errors that may lead to changes in payment. This survey found an average error rate of 7% (ranging between 1% and 45%), although the financial impact was minimal, and errors were higher in diagnoses than in procedures.2 The same study identified several critical areas: patient notes, which are often in poor condition; clinicians not differentiating important from less relevant diagnoses, thus leaving the choice to coders lacking medical training; and slow and uneven adoption of new guidelines by coding departments. However, it appears that HES quality has progressively improved in the recent years, likely driven by financial incentives to keep more complete and accurate records after the introduction of the PbR system. This holds even more true for high-cost procedures, which is often the case in cardiac surgery.8 Moreover, the accuracy of data is ensured via audit of the payment by result system, with standards assessed by the Health and Social Care Information service.6
Strengths and weaknesses in relation to other studies
This is not the first study aiming at extrapolating information from administrative databases and comparing them with clinical registries. On the contrary, several reports have been generated in the past decades in various countries, each adopting different techniques to select patients to include.1 6 9 10 A study from Massachusetts, USA, investigating isolated CABG in a clinical and an administrative database found significant difficulties identifying two corresponding cohorts, because of the way the database and the algorithm was designed (using the ICD-9-CM codes corresponding to CABG lead to the inclusion of cases combined with valvular or other surgery).9 In other work, Aylin and colleagues analysed mortality after isolated CABG in England, comparing data from the recently established HES and those published by the SCTS. In this case, numbers were not directly compared, only the models derived from each data set were.1 A similar study conducted in the Netherlands individually identified patients from the clinical registry in the administrative data, using personal information such as date of birth or post code. This led to an only partial matching (77%) due to incompleteness of the data and partial inaccessibility for information governance issues.10 Finally, last year our group compared a model derived from HES data with EuroScore. The matching was very good (around 98%) although it was only conducted at local hospital level, where data were more readily available and precise.6
The contrasting findings among studies can be explained by the inherent differences between each national administrative database, and changes over the years, but also by the study approach. Compared with these previous studies, we achieved a higher level of detail in our classification, with the aim of analysing specific subgroups of operations. In addition, the comparison with the available clinical data, obtained from different sources, provided several layers of control over the quality of our work. It is worth noting that Jaccard similarity could not be used beyond local level, as it would require data linkage by patient rather than linkage of aggregate numbers by hospital and year. Although it was easy to match procedures such as CABG, valve, transplant and VAD, others were difficult to identify and required greater iteration. In context with statistical discrimination procedures, the allocation of OPCS codes to surgical procedures may be regarded as a training phase and hence the degree of matching in tables 5 and 6 is likely to be optimistic, more so for harder to identify procedures.
Meaning of the study
The process we presented here will be replicated for a classification of diagnoses relevant to cardiac surgery, and then applied to the development of a risk model to predict early and late postoperative mortality. Specifically, HES can be linked to the Office for National Statistics mortality data, enabling to track long term, out of hospital follow-up. Possible uses range from risk stratification, to risk prediction, benchmarking and real-time monitoring. Naturally, the better administrative databases become with regard to quality, the more up-to-date, reliable and cheap instruments will be available.
Unanswered questions and future research
An issue which remains largely to be evaluated and hence subject of future study, is the concordance of recorded diagnoses between centres. In the present study, we did not specifically investigate this, although the fact that we were able to correctly identify the trusts providing cardiac surgery services across England is comforting. This system, once appropriately adjusted, can likely be applied to other medical specialties, proving especially useful in those areas where clinical databases are not fully established.
Conclusions
We described a system to identify the majority of cardiac surgery operations from administrative data, with an improved level of detail compared with the past. In the era of ‘big data’, administrative data sets make no exception, and given their already widespread use, we believe the best approach is to validate open and transparent standards for their interpretation, addressing the known challenges recently identified by Hand, rather than negating their usefulness with anecdotal or authoritative arguments.11
Acknowledgments
We would like to thank Mrs V Barnett for data collection and data management, and Mrs C Cottrell and Mr A Price from the coding department for their precious advice on the coding practices and suggestions on the classification.
Footnotes
Contributors This paper is the fruit of a long-standing project, carried by researchers with experience on outcome analysis using clinical and administrative databases. GB, DMN, NF and DP designed the study; GB, DMN, HW, JAM collected the data; all authors participated to the interpretation of the data and revision of the manuscript. GB is the guarantor of the article.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Data sharing statement Data essential for conclusion are included in this manuscript.
Patient consent for publication Not required.