Article Text

Abstract
Introduction Tailoring health information to the needs of individuals has become an important part of modern health communications. Tailoring has been addressed by researchers from different disciplines leading to the emergence of a wide range of approaches, making the newcomers confused. In order to address this, a comprehensive overview of the field with the indications of research gaps, tendencies and trends will be helpful. As a result, a systematic protocol was outlined to conduct a scoping review within the field of computer-based health information tailoring.
Methods and analysis This protocol is based on the York’s five-stage framework outlined by Arksey and O’Malley. A field-specific structure was defined as a basis for undertaking each stage. The structure comprised three main aspects: system design, information communication and evaluation. Five leading databases were searched: PubMed, Scopus, Science Direct, EBSCO and IEEE and a broad search strategy was used with less strict inclusion criteria to cover the breadth of evidence. Theoretical frameworks were used to develop the data extraction form and a rigorous approach was introduced to identify the categories from data. Several explanatory-descriptive methods were considered to analyse the data, from which some were proposed to be employed for the first time in scoping studies.
Ethics and dissemination This study investigates the breadth and depth of existing literature on computer-tailoring and as a secondary analysis, does not require ethics approval. We anticipate that the results will identify research gaps and novel ideas for future studies and provide direction to combine methods from different disciplines. The research findings will be submitted for publication to relevant peer-reviewed journals and conferences targeting health promotion and patient education.
- health informatics
- information technology
This is an Open Access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/
Statistics from Altmetric.com
Strengths and limitations of this study
This will be the first scoping review to identify and map out the methodological approaches in the field of computer-based health information tailoring.
A field-specific structure has been defined as the basis to undertake each stage of the Arksey and O’Malley framework.
Applying credible frameworks to determine data extraction variables strengthened the theoretical foundation of the study.
The development of a classification scheme makes the data categorisation process systematic and the results more reliable.
The review will not include any quality assessment and grading of evidence since this is not part of the methodology used.
Introduction
Tailoring health information to the needs and wants of individuals has become an important part of modern health communications.1 Tailored communication is defined as an adaptation of content and style of health promotion materials to each individual’s specific characteristics.2 Recent improvements in the fields of computer science and information communication technology have made it possible to computerise such an adaptation process. Studies have shown that computer-based information tailoring is more effective at improving individual’s health-related knowledge and persuading people to follow self-care activities, as compared with the conventional approaches.3 4
A generic computer-based tailoring system is made up of five components: (1) a user profile that contains an individual’s specific characteristics, (2) a library of selected content materials, (3) a set of rules that helps the system match the user profile to appropriate content from that library, (4) a delivery channel for communicating tailored information to users and (5) a tailoring engine which does the entire processing.5 An interdisciplinary approach is required to develop such a system. Developers and researchers from domains of health promotion, health informatics, computer science and communication with wide range of perspectives and diverse definitions, strategies and approaches should sit together for a consistent teamwork throughout the development, implementation and evaluation of information tailoring systems.6
To help researchers better understand common approaches, gaps, challenges and trends within the world of computer-based health information tailoring, there is need for a comprehensive systematic review. A limited number of systematic reviews have been conducted in the field of computer-tailoring4 7; however, most of these reviews have primarily investigated the effectiveness of tailored content within a limited set of homogeneous studies. Thus, the literature lacks a holistic view of the entire domain. To achieve this, a comprehensive review of the literature has been planned by using a systematic scoping approach. Scoping reviews offer a feasible means for collecting and synthesising a wide range of evidences8 and are particularly useful for bringing together evidence from different or heterogeneous sources.
This study was conducted to cover all aspects of tailoring interventions (ie, system design, information delivery and evaluation) and define less strict inclusion criteria aiming to include different types of research studies (eg, developmental and experimental) to ensure the comprehensiveness of the review. With these descriptions, scoping review is the best for the present study.
The primary objective of this scoping review is to classify the main approaches in the field of computer-based health information tailoring and to summarise available evidences. Scoping reviews are complex to undertake; so, an a priori protocol can help in the process of preparing for such a review to avoid problems occurring during the process. In this paper, a detailed protocol of our study was described.
Methods
The protocol of this study is based on the York framework outlined by Arksey and O’Malley,9 which includes five stages: (1) the identification of a research question, (2) the identification of studies relevant to the research question, (3) a selection of studies for inclusion in its review, (4) the charting of information and data within the included studies and (5) the collection, summarisation and reporting of its results.
To increase the clarity, recommendations suggested by Levac et al 10 and the Joanna Briggs Institute (JBI)11 were applied as complimentary to enhance the original stages of Arksey and O’Malley. The JBI recommendations concentrate on the necessity of congruence between the title, review objective(s), question(s) and inclusion criteria. Thus, a field-specific structure has been defined in this study as a basis for the consistent implementation of each stage throughout the study. This structure is based on an initial exploration of studies and it includes three main aspects: system design, information communication and evaluation. This tripartite structure and the York framework in combination, guide our scoping review. The procedures involved in each stage are discussed in depth below.
Stage 1: identifying the research question
Unlike systematic reviews that address precise research questions, in scoping studies, questions are broad in nature since the focus is on summarising breadth of evidence. Research questions provide the roadmap for subsequent stages, so the main aspects to hold our research questions are defined first: (1) study’s general characteristics, (2) the design issues of tailoring systems, (3) the delivery of tailored information and (4) the evaluation approaches in computer-based tailoring systems. In consulting our health informatics experts, a set of questions was developed for each aspect as presented in table 1. It is worth mentioning that the research questions in this study are not limited to those presented in table 1 and further questions might be discussed based on the data analyses, at the time of conducting the protocol.
Research questions
The JBI suggests that the ’PCC' can be used to construct scoping reviews questions, as a less restrictive alternative to the PICO. The PCC stands for the Population, Concept and Context. In the present study, the target ’population' was left open to basically include different groups of people regardless of their age, gender or health condition (ie, from healthy people to both chronic and acute patients). The ’concept' of computer-tailoring was also defined to be broad, covering any system that automatically provides tailored information for health consumers, regardless of its developmental approach. The tailored information refers to any kind of knowledge, feedbacks and recommendations that help people to manage their health. The ‘context’ has also been left open, to cover any situation that people might need health information (ie, from health promotion to self-management programmes for chronic patients).
Stage 2: identifying relevant studies
This stage involves the development of a search strategy plan, which includes decisions on search resources, search terms, publication period and language. Since the most outstanding characteristic of scoping studies is their comprehensive coverage of evidence within a given field, our search strategy has been adapted to be as broad as possible. For this stage, the search strategy involves the following two sections: search resources and search strings.
Search resources
To be comprehensive, the York framework recommends searching through several sources of literature, including electronic databases, reference lists of relevant literature, hand searching through key journals and varying sources of conference proceedings. Our scoping review was approached in multiple steps as follows:
First, comprehensive searches of PubMed, Scopus, Science Direct, EBSCO and IEEE databases were conducted. These sources include certain highly important journals, in which our research area is widely dealt with, such as: health and medicine, information science and technology and computer science. Numerous keywords were used in combination to formulate the search strings (table 2).
Second, the reference lists of all included papers will be manually checked to find additional relevant studies.
In addition, at least three scholars whose names often come up in searches for computer-tailoring will be hand-searched to ensure all articles conducted by these research groups are included.
Finally, based on our preliminary data analysis, the top three journals that contain the highest numbers of published papers will be identified and hand-searched through issues spanning from 1990 to present.
Main concepts and related keywords
Search strings
Our multidisciplinary team devised a list of terms pertinent to the main concepts of computer-tailoring, as shown in table 2. All searches were restricted to the English language, with publishing dates ranging from 1990 onwards; since that is when computer-tailoring first appeared in the literature.12 Our plan is to conduct a sensitive rather than specific search of the literature. Thus, search terms are kept broad, resulting in many irrelevant studies having to be eliminated in the study selection stage. The search strategy for each of the databases was defined in consultation with a senior medical librarian (see online supplementary appendix 1). Further manual searches will be performed later on.
Supplementary file 1
Stage 3: study selection
In scoping reviews, the eligibility criteria are not defined in advance but are revised instead in an iterative process as researchers eventually become more familiar with the variety of materials throughout the process. In general, the selection criteria were formulated in such a way that it only includes studies in which the tailored content has been generated for health consumers through a computerised process. The inclusion criteria in this study are as follows:
Tailoring should be done on the content of the information (not the process, services, tools, user interfaces, etc).
The process of generating tailored information should be computer-based (rather than manual tailoring of the information by human experts). Studies that used ICT only as a communications medium for delivering tailored messages were not included.
Patients or health consumers should be the target addressees of the information (rather than the medical staff or students).
Since the purpose of this study is to investigate the development and evaluation approaches used in tailoring interventions, original researches with sufficient extent of description about their methods will be included (ie, qualitative and quantitative). The only exclusion criterion, in this study, is the article type, excluding non-original research materials like review studies, studies describing theoretical concepts or proposing frameworks, specialist’s commentaries and editorials.
Screening process
Prior to commencing the screening process, two members of the research team have piloted the inclusion and exclusion criteria within a random sample of 10% of the retrieved cases. Once the final set of criteria was agreed on, paper titles and abstracts were simultaneously examined to find the relevant papers. To achieve this aim, two authors (AK and EN) have independently applied the inclusion criteria on all the retrieved citations. Articles that were included by both researchers have then entered our second phase, in which their full texts will be reviewed for final inclusion decision. Disagreements, if any, will be resolved by consensus with the third reviewer (MT). The first phase of screening has been completed and the second phase is underway.
According to the guideline proposed by the JBI,11 the screening process will be reported in form of a graphical diagram similar to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses chart (adapted for scoping reviews). The flow chart will clearly detail the review decision processes including duplicate removal and the number of excluded articles along with their reason for exclusion.
Stage 4: data extraction
The process of data extraction in scoping reviews is termed ‘charting’ in which a descriptive summary of the results will be generated. In this stage, a data charting form was developed by identifying variables that correspond with the research questions. The variables are at different levels of generality and specificity, with each belonging to one of the three aspects of the study (ie, system design, information delivery and evaluation). The process is organised in two phases: first, determining a set of variables for extraction and second, determining a list of valid values for each variable. These phases are explained below.
Phase 1: determining variables
In order to systematically determine variables that are consistent with the preceding stages of our protocol, we first looked for existing conceptual frameworks related to each of the three main aspects of tailoring (eg, system design, information delivery and evaluation). Components of the identified frameworks were used to determine an initial set of variables that shall be updated as articles are being reviewed. A description of frameworks along with their components is provided below and summarised in table 3.
List of variables to be studied for each aspect
General information
In accordance with the metadata that has been used in previous scoping review protocols,13–16 decision has been made for the following set of items to be extracted in our study: publication year, the geographical location in which the research was conducted, corresponding author’s discipline and the health domain that has been studied.
Framework for system design
A variety of models and frameworks have been suggested for health information tailoring systems,1 6 12 17 among which the one proposed by De Vries18 was chosen with the following three components:
User profile comprises characteristics, preferences and information needs of the user, which serves as the basis for tailoring the message. It may include a wide range of personal data from demographic to more complex features such as user’s health and cognitive state, learning style, background knowledge, etc.
Content library consists of predefined chunks of information and snippets of fill-in-the-blank templates.
Tailoring algorithm consists of rules that match user information to appropriate content from the library.
Framework for delivery
In order to investigate issues related to the delivery of tailored information, the Berlo’s Model of Sender-Message-Channel-Receiver was used as a guide.19 It consists of four components: sender, receiver, message and channel, from which the focus has been on the last two (ie, channel and message) in this study.
Framework for evaluation
To investigate the evaluation approaches used in computer-tailoring literature, a framework proposed by the Centers for Disease Control and Prevention has been chosen for the evaluation of public health programme.20 The framework consists of six connected elements, from which two have been focused on (ie, evaluation outcome/indicator and data sources/data collection method) based on our research questions. From the initial review of papers, a great variety was found for evaluation indicators. To address this, the HOT-fit evaluation framework was employed as the basis to classify indicators into one of the three dimensions: human, organisation and technology.21
Phase 2: identifying data categories
In this phase, a list of values will be defined for each of the variables specified in previous phase. The values will be derived from categorising the extracted data. Data categorisation narrows our focus on data and provides an abstract view which is critical for further analysis. Despite the fundamental role of categorisation, it has been less addressed in guidelines and previous scoping reviews. Here, our two-step strategy is presented concerning this issue in more detail.
Step 1: developing a classification scheme
In previous studies, data categorisation was performed simultaneously with data extraction, so the decisions were based on partial information and categories were refined several times throughout the process. In this protocol study, a complementary step that would be performed on complete set of data was considered. Once the data extraction is over, a frequency table will be created according to the total count of data in each category, based on which, the initial set of categories will be revised by merging smaller categories and splitting larger ones. This may lead to the removal of an existing category or emergent of a new one, providing more robust categories.
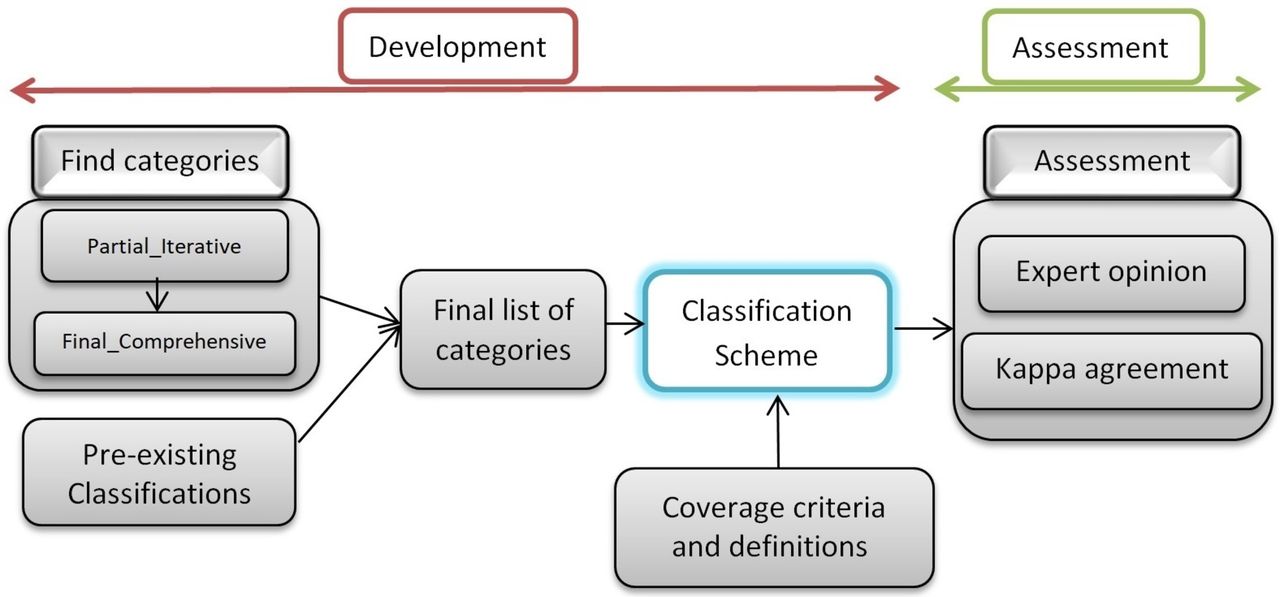
When the final list of categories is obtained, then they would be organised into hierarchical structure. To do this, available classification systems such as Medical Subject Headings will be used as a guide to understand the relationships between categories. For further clarification, a precise description would be provided for each category to represent its scope of coverage. Putting all these together will create a classification scheme which will help reviewers to perform consistently in assigning categories to extracted data. The process of development and evaluation of the classification scheme is shown in figure 1.

The design and evaluation process of the classification scheme.
Step 2: assessing validity and reliability
To ensure that the developed classification scheme is appropriate and consistent, its validity and reliability will be checked by using the following two steps:
First, for the validity evaluation, the classification scheme will be given to three domain experts and their comments regarding the clarity and correctness of each category definition, coverage and hierarchy would be asked or requested.
Then, the reliability will be assessed by asking two researchers to carry out classifications on a sample set of data to check the level of consistency between them. To do this, Kappa statistic will be used with 80% agreement as the minimum acceptable inter-rater to ensure that reviewers would have the same interpretation of data and categories.
Once the data extraction form is developed, two independent reviewers (AK and EN) will first perform a calibration exercise with a random sample of articles. Once the agreement reached the desired level, they will proceed to the full set of articles and extract data from all included studies. A third reviewer (MT) will be consulted, if necessary, to reach consensus. Results from this stage will be presented as a concept map which provides a hierarchical overview of the identified categories and approaches.
Phase I (determining extraction variables) has been completed and an initial version of the extraction form was developed. The rest of the tasks will be performed later (ie, identifying the categories and performing the extraction process).
Stage 5: collection, abstraction and reporting of findings
The extracted data will be collected in a table in which rows will represent the included articles, columns will represent variables and cells contain the strategies that the articles have taken in relation to the relevant variables. To analyse this data set, the following three explanatory approaches will be used: frequency analysis, trend analysis, and co-occurrence analysis.
Frequency analysis
In frequency analysis, the counts and percentages of articles in each cluster will be calculated. Studies that share a similar approach towards a specific variable will be clustered together and those following different approaches will be assigned to different groups. Clustering can be carried out based on values of a single variable on the entire data set or on a subset of articles which already belongs to a cluster on a higher level.
In this study, a multilayered clustering will be followed in an iterative process. To do so, an initial single-level clustering should be performed on the entire data set and only then, articles within each cluster will be once again clustered in accordance with more detailed categories. Depending on the number of articles within each cluster, the act of clustering may recur for more levels and/or more variables, leading to a set of nested clusters. The result of this analysis will be a map of articles represented in bubble plot, graph or tabular form.
Trend analysis
Trend analysis will be used to present the research evolution, based on several selected variables.
Association analysis
Most of the previous scoping reviews used frequency analysis as the only method to describe the data. In this study, attempt was made to find interesting correlations between variables for the first time. Considering the three-layered data structure in this study (eg, aspect, variable and category), association analysis can be done within or between these layers. The variables in this study may take one value or more, on the basis of which, they are categorised into two classes of single-valued and multi-valued variables. When the association is explored between two variables from different aspects, between-aspects analysis is performed. If the variables belong to the same aspect, we will have within-aspects analysis. In multi-valued variables, the relationships between different values of the same variable, which formed the within-variable analysis can be investigated.
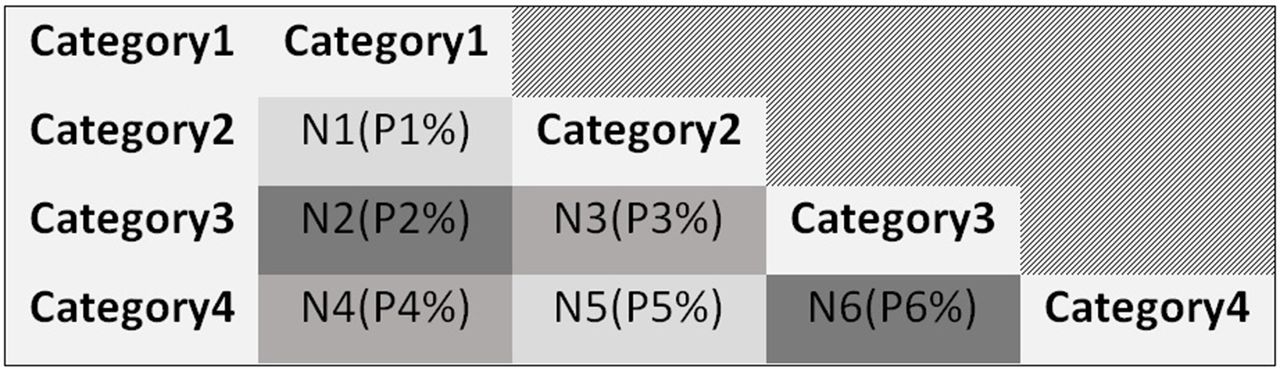
To do these analyses, a co-occurrence matrix can be used to identify two-by-two relations. Figure 2 shows a 4×4 co-occurrence matrix as an example, in which rows and columns represent values from two variables and each cell represents the count and percentage of articles that have used value ’X' from variable 1 along with value of ’Y' from variable 2. In other words, if an article uses value ’X' from variable 1, it is more likely to evaluate value of ’Y' from variable 2 as well. The intensity of the colours in the table is proportional to the number of articles in each cell. This table reveals the gaps and tendencies in tailoring literature where further primary or review researches are needed, respectively.

{kind=link}
{kind=link}
Sample co-occurrence matrix.
To illustrate the relationship between the data analysis approaches and the study research questions, the questions were classified into two classes of qualitative (eg, what-based) and quantitative (eg, distribution-based). The first group will be answered based on the categories identified from the data and the second group will be answered using the frequency analysis.
On the other hand, association analysis explores the relationships between the variables and provides new ideas for future studies. Since the number of possible combinations of variables will be relatively large, it is preferable not to define research questions regarding this analysis, at this stage. Important relationships will be reported when the results have been published.
Discussion
To the best of our knowledge, no comprehensive scoping review exists within the field of computer-based tailoring, both in general and in specific (on health information domain). In this study, a detailed systematic protocol has been developed to conduct a scoping review within the field of health information tailoring, using the framework proposed by Arksey and O’Malley. Several enhancements were applied to the adopted framework to make it specifically usable to the field of computer-tailoring and produce more reliable and usable results.
Although data extraction and data analysis are two critical tasks in review studies, previous scoping reviews13 14 16 have thus far neglected to describe the techniques used in-depth. A review article that synthesised scoping guidelines discussed the lack of standards on how to analyse the data and report the results.22 This may produce inconsistency, ambiguity and bias, which we tried to prevent by providing a systematic detailed description for each stage and every strategy used in the present study.
For data extraction, a two-phase strategy that used a combination of data-driven and model-based approaches was developed, not seen in previous studies. The use of available models (frameworks) provides a theoretically defensible synthesis of data which leads to more generalisable results.
Both numerical summary and thematic analysis were employed to extract background information from the selected studies. A numerical overview of the amount, type and distribution of the included studies will be obtained using frequency analysis and a thematic summary of the findings will be available through data categorisation. The idea of conducting multidimensional analyses (eg, multilevel clustering and association mining) has been proposed for the first time in this study, which can be employed in future scoping studies as well. Frequency distribution analysis maps out the evidence by providing a summary of the counts of articles regarding a particular variable, helping researchers to identify gaps where primary studies are lacking.
Another issue that strengthens this protocol is that two reviewers were used with the calibration exercise to ensure reliability prior to the main screening or extraction for every decision-based process like citation selection, full-text screening, data charting and data categorising.
We foresee some potential challenges related to our scoping review. First, formal appraisal will not be given to the methodological quality of the included studies, as the aim of a scoping review is generally known to be a provision of an overview of the existing evidence regardless of its quality. It was assumed that the quality of the included papers had been ensured by the evaluation process followed by deciding what papers to publish.
Second, the yield of the literature search might be more extensive than anticipated; hence, the team will work closely with our information specialist to ensure that the scope is manageable. Due to practical issues related to time, funding and access to resources, there will be need for a trade-off between breadth, comprehensiveness and feasibility.
Future scoping review practitioners can use our protocol as an enhanced version of previous frameworks with more details on extraction, categorisation and analysis techniques. Any discrepancies or deviation needed in real usage of this protocol will be clearly detailed and justified in the ‘Methods’ section of the scoping review report paper, if and when they occur.
Ethics and dissemination
This scoping review will identify the fundamental approaches used to implement and evaluate computer-based information tailoring systems from the perspectives of multiple disciplines, where each has emphasised on some aspects with the use of more advanced methods. Results from this review provide a comprehensive overview of the field and will help researchers to combine effective methods from across the disciplines in future research. All data will be obtained from publicly available materials and therefore this study will not require ethics approval. The results will be published in journals with multidisciplinary approach, to enhance linkages necessary for dissemination of our results.
References
Footnotes
Contributors All authors have made substantive intellectual contributions to the development of this protocol. MT, MGA and HT conceptualised the review approach and provided general guidance to the research team. All authors were involved in developing the review questions and the review design. AK and MGA identified the framework from which EN and AK developed and tested search terms. AK and MGA initially developed the data extraction framework, which was then further developed by input from team members. AK initiated the first draft of the manuscript, which was then followed by numerous iterations with substantial input and appraisal from all of the authors. MT supervised the entire process, performed the final touch and approved the final version of the manuscript.
Funding This work was supported by Mashhad University of Medical Sciences Research Council grant number (#950392).
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.