Article Text

Abstract
Introduction Early identification of Parkinson’s disease (PD) in its prodromal stage has fundamental implications for the future development of neuroprotective therapies. However, no sufficiently accurate biomarkers of prodromal PD are currently available to facilitate early identification. The vocal assessment of patients with isolated rapid eye movement sleep behaviour disorder (iRBD) and PD appears to have intriguing potential as a diagnostic and progressive biomarker of PD and related synucleinopathies.
Methods and analysis Speech patterns in the spontaneous speech of iRBD, early PD and control participants’ voice calls will be collected from data acquired via a developed smartphone application over a period of 2 years. A significant increase in several aspects of PD-related speech disorders is expected, and is anticipated to reflect the underlying neurodegeneration processes.
Ethics and dissemination The study has been approved by the Ethics Committee of the General University Hospital in Prague, Czech Republic and all the participants will provide written, informed consent prior to their inclusion in the research. The application satisfies the General Data Protection Regulation law requirements of the European Union. The study findings will be published in peer-reviewed journals and presented at international scientific conferences.
- Parkinson-s disease
- Speech pathology
- Audiology
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
This study aims to employ the remote longitudinal speech monitoring of prodromal and early-stage patients with Parkinson’s disease via smartphone calls.
An additional set of active speech and motor tasks will be captured.
The results of this study will be based solely on the Czech language.
This study will be implemented in one type of smartphone, and the impact of different devices on speech outcomes is yet to be determined.
Introduction
Parkinson’s disease (PD) is a neurodegenerative disorder characterised by the loss of dopaminergic neurons in the substantia nigra.1 The incidence of PD is approximately 1.8% in persons older than 65 years.2 There is no treatment that halts or slows the progression of PD, and the pharmacotherapy and neurosurgical interventions that are available only mitigate specific symptoms. A PD diagnosis is typically made when cardinal motor manifestations appear; by this point, up to 50% of the neurons in the substantia nigra may already be irrecoverably damaged.3 Unfortunately, no sufficiently accurate biomarkers of PD are currently available, although the existence of such biomarkers would allow for the measurement of the effectiveness of experimental treatments in slowing the progression of the disease. Furthermore, no reliable method for identifying people who are at high risk of developing PD exists at present. Thus, establishing a suitable biomarker would be a crucial breakthrough that would impact on diagnoses and future PD treatments, and is one of the most important topics in PD-related research.4 In particular, motor-related dysfunctions are strong predictors of conversion to synucleinopathy, and have one of the most significant hazard ratios of 3.16 among the available predictive markers to date.5
Isolated rapid eye movement sleep behaviour disorder (iRBD) is a parasomnia characterised by dream-enactment behaviours associated with REM sleep without muscle atonia,6 and represents a prodromal marker of neurodegenerative synucleinopathies, mainly PD and dementia with Lewy bodies.7 The risk of developing a neurodegenerative disease is exceptionally high (>80%) in subjects with iRBD.8 9 Since symptoms of iRBD precede Parkinsonism, research focused on iRBD is essential for the development of a neuroprotective therapy to counter synucleinopathy,10 as no other preclinical marker has a predictive value that is comparable to iRBD.11
As the most complex acquired human motor skill, and involving over 100 muscles, speech is a sensitive marker of damage to neural structures engaged in the brain’s motor system control.12 Up to 90% of PD patients develop distinctive speech and voice abnormalities, collectively termed hypokinetic dysarthria, which are mainly characterised by a decrease in the quality of the voice, hypokinetic articulation, hypophonia, monopitch, monoloudness and deficits in timing and phrasing.13 Based on the recent findings of a multilanguage, multicentric study using an objective acoustical analysis of 150 patients with iRBD, it is clear that speech disorders are one of the earliest motor signs of PD.14 Thus, vocal assessment appears to have intriguing potential as a preclinical diagnostic and progressive biomarker of PD and related neurodegenerations; it is also inexpensive, non-invasive, easy to administer and has the potential to being conducted remotely from the patient’s home (eg, by using a smartphone15).
In current practice, measures of PD are primarily subjective, rater-dependent and require in-clinic assessments.16 The trials using these measures are lengthy and expensive and, as they are usually based on a once-off assessment, might produce false results. Given the technical and accessibility advancements in smartphone technologies, evaluating motor symptoms of PD via mobile devices continues to be an increasing focus among the research community.17–19 The potential of smartphones has already been demonstrated in quantifying the severity of PD based on the remote assessment of five tasks (voice, finger tapping, gait, balance and reaction time) using an application that was developed for this purpose.20–22 However, such an assessment requires the patients (or research subjects) to repeatedly perform a set of predefined activities. It is thus reasonable to expect that most patients will not be willing to perform such artificially constructed activities on a daily basis for several years.
By contrast, the extraction of speech patterns from smartphone calls would provide a natural, passive biomarker that does not require additional effort on the part of the subjects. Moreover, such a speech-based application could easily be scaled to a larger population, thus allowing for high-throughput screening, followed by a more detailed analysis if the screen is abnormal. However, the reliability of smartphones in detecting prodromal PD (ie, iRBD) via smartphone calls in realistic scenarios with ambient noise level environments has not yet been investigated.
Therefore, the aim of this study is to develop a fully automated and noise-resistant smartphone-based system that is able to monitor the distinctive speech patterns of neurodegeneration on a daily basis using acoustic data obtained in various environments (SMARTSPEECH). Such a system would have tremendous potential to revolutionise the diagnostic process of PD and could provide a robust biomarker of the progression of the disease. To fully exploit the possibilities of smartphones, a set of active speech and motor tasks is included for sensitivity analysis and for comparison.
Methods
Objectives
The main objective of the study is to demonstrate that, using the SMARTSPEECH system, speech performance elicited during regular phone calls through a smartphone can provide principal biomarkers for diagnosis and monitoring the progression of prodromal PD.
The specific objectives are to:
Develop a smartphone application that will be able to capture the subjects’ data,
Collect up to 2-year longitudinal speech data from subjects with iRBD, patients with early-stage PD and healthy control subjects of comparable age.
Collate existing approaches and develop novel methods allowing assessment speech markers of neurodegeneration in PD, including tests of their robustness against noise and recording conditions and selecting the most appropriate parameters for smartphone-based monitoring.
Build the concept of a complex system (SMARTSPEECH) for detection of speech abnormalities in PD and other synucleinopathies, including its statistical power evaluation in differentiation between PD, iRBD and control groups and identify its relationship to essential clinical markers reflecting disease progression such as the Movement Disorder Society-Unified Parkinson’s Disease Rating Scale.
Analyse the sensitivity of a set of active speech and motor tasks and compare the outcomes to data acquired through SMARTSPEECH passive calls monitoring.
Collection of speech data
To avoid potential conflicts due to different microphone characteristics across various manufacturers, the speech data will be collected using the same smartphone device, HONOR 9X Lite (Shenzhen Zhixin New Information Technology), operating on the Android V.9 system. The application will record the subject’s telephone speech with a high degree of quality using a sampling frequency of 44.1 kHz and 16-bit quantification.
The distant-speaker filtering algorithm
Due to ethical reasons and the General Data Protection Regulation law, the subjects’ speech partners will need to be removed entirely from the recordings, which will be accomplished by employing real-time adaptive filtering of the input audio. The audio will be collected via two different microphones, representing two channels in the stereo mix (see figure 1). The primary microphone (MIC 1) is the closest to the speaker’s mouth and thus captures the subject’s speech with absolute power dominance. However, the distant speaker’s talk might still be present, such as in segments in which the subject is silent or speaks quietly, or when the distant speaker is speaking very loudly. The secondary microphone (MIC 2) mainly captures the speech of the subject, but also captures the distant speaker (coming from a call speaker nearby, hence at a greater power than via MIC1) and surrounding noise. However, these settings are valid only if the loudspeaker is not activated. In this case, the power of both speakers is more or less equal in the channels. Since the algorithm is not guaranteed of functioning properly in such scenario, the recording process will be cancelled immediately when the user activates the loudspeaker.

Schematics of the HONOR 9X smartphone audio inputs and outputs.
In order to remove the distant speaker from the final mix completely, a real-time adaptive algorithm was designed based on the hardware and software settings of the smartphone. Specifically, the computational complexity needed to be optimised because intensive background processes tend to eventually be suppressed by the phone’s operating system. The principle, which is cross-channel thresholding using smoothed energy estimates from a specific spectral band, is based on the Neumann-Pearson Criterion. The algorithm’s illustrative schema is displayed in figure 2, and the procedure is as follows:
The input is a stereo call recording  consisting of channel 1 (from MIC 1),
consisting of channel 1 (from MIC 1),  , and channel 2 (from MIC 2),
, and channel 2 (from MIC 2),  . Both are processed in subsequent windows of a given length of L seconds. In the current frame, the signals are decimated by two, thus reducing the computational burden of the entire procedure while maintaining adequate resolution. The signals are then processed through a Butterworth band-pass filter with a range of 300–8000 Hz, as this is the range in which the fundamental speech information is expected to be found. A power estimate is computed from the filtered channels using the L-1 norm, which is simply the sum of the absolute values of the samples in a given segment with a length of w. The estimated power trajectory is then smoothed using a normalised integrator with a forgetting factor λ, producing
. Both are processed in subsequent windows of a given length of L seconds. In the current frame, the signals are decimated by two, thus reducing the computational burden of the entire procedure while maintaining adequate resolution. The signals are then processed through a Butterworth band-pass filter with a range of 300–8000 Hz, as this is the range in which the fundamental speech information is expected to be found. A power estimate is computed from the filtered channels using the L-1 norm, which is simply the sum of the absolute values of the samples in a given segment with a length of w. The estimated power trajectory is then smoothed using a normalised integrator with a forgetting factor λ, producing  and
and  . The segments containing the subject’s speech are then detected when the following condition is met:
. The segments containing the subject’s speech are then detected when the following condition is met:
 (1)
(1)
where k represents the extent of the channels’ power difference as a ratio of the  and
and  SD, calculated as
SD, calculated as  . The SD and the mean in equation (1) are both computed per window. At the end of the window processing section, the timestamps are shifted to compensate for the delay introduced by the normalised integrator. The segments that are not considered to consist of the subject’s speech are masked by zeros, and only the output from the first channel is subject to further processing.
. The SD and the mean in equation (1) are both computed per window. At the end of the window processing section, the timestamps are shifted to compensate for the delay introduced by the normalised integrator. The segments that are not considered to consist of the subject’s speech are masked by zeros, and only the output from the first channel is subject to further processing.

An illustrative schema of the distant-speaker filtering algorithm.
A final check is made to ensure that the end of the window does not conflict with the subject’s speech segment, which might produce disruptive artefacts. If the result is positive, the output from the current window is discarded, and the process is rerun with an adjusted, shorter L to avoid the conflict. The final output is a mono audio recording containing only the subject’s speech.
After the trial testing was conducted, the default value for L was set to 30 s as the optimal value for reduced computational power, more precise results and lower possibilities of conflicts at the end of the window. The segment length for the L-1 norm was set to  samples with an overlap of 50%, which resulted in fast processing with sufficient precision. The forgetting factor was set to
samples with an overlap of 50%, which resulted in fast processing with sufficient precision. The forgetting factor was set to  producing the optimal smoothing effect for the given scenario.
producing the optimal smoothing effect for the given scenario.
SMARTSPEECH application for monitoring passive speech via regular smartphone calls
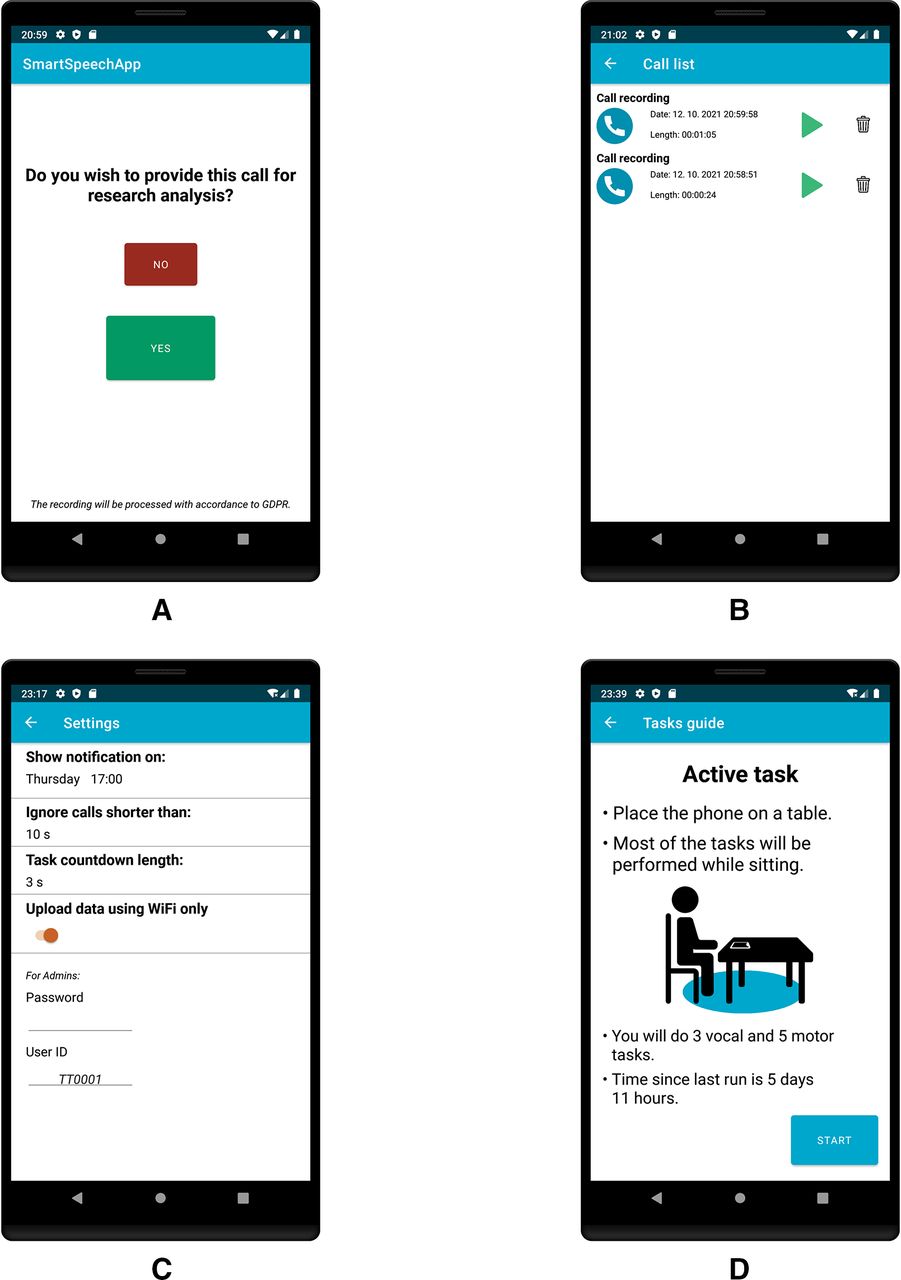
After either an incoming or outgoing call is concluded, the user will be presented with a screen containing an option to delete or save the call (figure 3A). If the second option is selected, the recording will be filtered immediately using a distant-speaker filtering algorithm, and will be saved to the private application folder on the device. It will be possible to replay or delete each recording from the recent calls list (figure 3B) in the application within the following 24 hours. After 24 hours, the recording will be compressed and sent to a secured server using SSH and REST API. The original call will then be deleted from the device. The aim is to record at least four 5 min recordings per month from each participant. A setting section on which the user can configure the application to suit their needs will be included (figure 3C).

(A) Option screen to delete or save the recently completed call for speech analysis. (B) List of calls from the previous 24 hours with details and the options of replaying and deletion. (C) The setting screen of the app. (D) the active task introduction screen, which shows a guide to performing the active tasks and the time elapsed since the last active task run.
Active tasks
The application has a module that invites participants to record three active functional vocal tasks once every 14 days; the participants are instructed to capture the data in everyday environments with a low ambient noise level. In addition, the participants are asked to perform five motor tasks that are commonly used in PD research.20–23 These tasks will be used to compare the sensitivity of the active and the passive data. On launching the active tasks protocol the users are presented with the guidelines and elapsed time since last run (figure 3D). Before each task, the user will be presented with short, written instructions, including an option to replay an audio or video example of the given task. In the voice section, the recordings can be replayed after being recorded. If the user is dissatisfied with the result, an option to repeat the task is available.
The entire set of active tasks consists of prolonged phonation (figure 4A), /pa/-/ta/-/ka/ syllable repetition (figure 4B), reading a passage (figure 4C,D), a tapping game (figure 5A,B), alternated tapping (figure 5C,D), a writing task (figure 5E,F), resting hand tremor (figure 6A,B) and a gait with turnaround (figure 6C,D). Each task will be executed twice, and the motor tasks are to be executed first using the right hand and then the left hand.

(A) Prolonged phonation task instruction screen (task duration ~15 s). (B) Sequential motion rates instruction screen (task duration 7 s). (C) Reading passage instruction screen. (D) Reading passage sample text that is chosen randomly from six samples and contains approximately 80 words (task duration ~40 s).

(A) A tapping game introduction screen. (B) A tapping game task. The delay between spawning the circle and a successful tap is measured. The action takes place 20 times (task duration ~20 s). (C) An alternated tapping introduction screen. (D) An alternated tapping task. The timestamps of the individual taps are measured (task duration 15 s). (E) Writing task instruction screen. (F) A writing task. The time spent rewriting each word is measured. The patient is shown five words in each run. Eight different datasets that are assembled in the same manner are chosen randomly in each run. Examples include the Czech words ‘SESTRICKA’, ‘NEJLEPSI’, ‘LECENI’, ‘ZABAVA’ and ‘PREDSTAVA’. The task can be skipped after 80 s have elapsed (task duration ~40 s).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(A) Rest tremor instruction screen. (B) A rest tremor task (task duration 15 s). The patient’s hand tremor is measured using an accelerometer in all three axes. The z-axis is live plotted for user feedback. (C) A gait task instruction screen. (D) A gait task (task duration ~30 s). The z-axis rotation is measured and plotted on the screen for user feedback via an internal gyroscope.
Data validation and monitoring
Once the call and task data arrive on our server, they are saved on a database and the basic information becomes visible on the web interface to allow the data parameters to be reviewed for the quality, frequency and recording duration. In the event that the participant does not make any calls or perform passive tasks within the required period, the participant will be notified via a push notification sent to their email address.
A gateway validation of the incoming data needs to be performed before the data are stored securely on the database to minimise the possibility of corrupted, irrelevant data entering the system, which would produce misleading results.
First, recordings that are shorter than two seconds will be discarded because they do not contain much information that is relevant and often contain errors. Subsequently, the speaker-detection algorithm will be employed to prevent data contamination when the user hands the smartphone to someone else for the call. The Kaldi toolkit24 was used to construct the procedure. We employed a high-order Gaussian mixture model trained on the Czech section of the GLOBALPHONE database25 using a set of mel-frequency cepstral coefficients. New subjects in the study will be enrolled in the model once a sufficient amount of data has been collected. I-vectors are extracted on detection, and are used to compute the probabilistic linear discriminant analysis score. Using this score, a classificator decides whether the recording belongs to the correct subject. The data that will be assessed as not originating from the given subject will be moved to a specific folder and are not included in the data analysis.
Note that the purpose of the algorithm is also a form of quality control, as it excludes recordings that are of poor quality, such as utterances that are significantly affected by disruptive noise at a low signal-to-noise ratio (SNR). In these cases, the subject’s speech is so corrupted that the computed features have little similarity to the subject’s model. In addition, an SNR estimator based on minimum statistics26 is employed in the last validation phase. Segments with an instantaneous SNR lower than the preselected threshold will be excluded from the analysis because the methods for extracting speech features cease to be reliable at certain very low SNR levels (such as pitch detection algorithms at SNR less than 6 dB27).
A voice activity detector is applied to the samples that have passed the validation procedure. The output indicates long calls during which the subject only speaks for a tiny fraction of the overall duration. This allows to have a better grasp of the amount of speech data gathered via the system and to notify the subject if the amount of data is insufficient.
Extraction of acoustic speech and motor features
Hypokinetic dysarthria is due to dysfunction in the basal ganglia motor circuit, leading to impairments in the regulation of the initiation, the amplitude and the velocity of movements.12 28 Therefore, this project aims to collect, develop and extract different acoustic features describing motor aspects of speech that have well-defined PD pathophysiology17 and correspond to the perceptual description of hypokinetic dysarthria defined by Darley et al.29
The following features represent the most anticipated candidates for the final analysis:
Disruptions in phonation caused by dysfunctions in the vocal folds can be captured using the acoustic measure of Cepstral Peak Prominence, which correlates with the auditory perception of decreased voice quality/breathiness.30
Articulation deficits, which are perceived as a decrease in intelligibility, can be described using metrics such as the vowel space area.31
Dysprosody is captured by the reduced amplitude of vocal cord movements, which correlates with the impression of monopitch, and can be assessed using the acoustic measure of pitch variability.14
Decreased ability to maintain the speech motor sequence or to alternate quickly between responses can be reflected by the acoustic measures of the net speech rate and duration of pause intervals, which reflect the perceived auditory timing of speech and may describe deficits such as a slow articulation rate and a reduced ability to intermit and initiate speech.32
Linguistic deficits, including limited vocabulary and a decrease in its range, which might indicate potential underlying mild cognitive impairment, can be assessed using a set of lexical features such as content density.33
To assess the overall degree of speech impairment, powerful deep neural networks could be employed, including spectrogram analysis to evaluate specific features when traditional methods might be insufficient. Insight into the detailed method behaviour would be supportive, and would reveal critical physiological details.34
Several methods for the automatic analysis of key dimensions of speech in patients with PD have already been developed.32 35 36 However, all the methods need to undergo experimental and theoretical testing for noise robustness and reliability to validate their usefulness.27 A set of features commonly used in the existing literature will be extracted from the active motor tasks20–22; the set includes tapping velocity, intratap duration variability, reaction time, tremor acceleration skewness and velocity.
Endpoints
The primary endpoint will be represented by composite dysarthria index, reflecting the severity of speech impairment, which will be based on a combination of several distinct acoustic speech features associated with hypokinetic dysarthria in PD. Secondary endpoints will be represented by individual acoustic speech features associated with hypokinetic dysarthria in PD and linguistic features associated with potential cognitive decline.
Study design and participants
During this project, each participant will be given a full explanation of the project’s purpose and aims, will be informed about the procedure, and will be given the opportunity to ask questions before deciding whether to sign the informed consent form. In total, we plan to recruit 25 iRBD subjects, 25 early-stage patients with PD and 25 healthy controls as part of this longitudinal study. As we expect a drop-out rate of about 20% per year,17 up to 50 patients with iRBD and the same number of early-stage patients with PD will be recruited at the baseline. These data might be used for a better-sampled cross-sectional study. All the iRBD subjects will fulfil the criteria listed in the International Classification of Sleep Disorders, third edition diagnostic criteria,37 including confirmation of REM sleep without atonia via polysomnography. The inclusion criteria for iRBD will be
Onset of iRBD after 50 years of age.
No history of major neurological disease (such as epilepsy or strokes) or other significant diseases that could affect study participation or voice analysis (eg, active cancer, drug abuse or diseased vocal cords).
No significant cognitive decline or severe depression.
No history of therapy with antiparkinsonian medication.
All the patients with PD will meet the Movement Disorders Society’s clinical diagnostic criteria for PD,38 and will be investigated during the on-medication state. The inclusion criteria for PD will be:
Onset of PD after 50 years of age.
Hoehn and Yahr stage 1–2 in the on-medication state.
Disease duration more than 5 years after diagnosis.
No history of a major neurological disease other than PD (such as epilepsy or strokes) or other significant diseases that could affect study participation or voice analysis (eg, active cancer, drug abuse, or diseased vocal cords).
No significant cognitive decline or severe depression.
No involvement in any speech therapy during the duration of the project.
The inclusion criterion for controls will be that the participants have no history of neurological or communication disorders, and no history of parasomnias or other sleep disorders. PD and healthy control subjects will be age-matched and gender-matched to the iRBD group.
Each participant will be required to perform passive speech recordings and active tasks using the provided smartphone for 2 years. In addition, each of the subjects will undergo three examinations at the clinic: at the baseline, after 1 year and after 2 years (at the end of the project). The clinical examinations will consist of taking a structured personal history, quantitative testing of motor and non-motor symptoms of PD based on the Movement Disorder Society-Unified Parkinson’s Disease Rating Scale,16 cognitive testing using the Montreal Cognitive Assessment,39 autonomic testing using the Scales for Outcomes in Parkinson’s Disease-Autonomic Dysfunction,40 the evaluation of depressive symptoms using the Beck Depression Inventory II,41 and speech examinations according to the dysarthria research guidelines for acoustic analyses.23 Recruitment of the participants will begin in October 2021.
Patient and public involvement statement
Most of the patients have been involved in previous studies and are familiar with the team, the research topic and the methods. The SMARTSPEECH protocol was designed with the aid of a short questionnaire that was completed by a selected representative group of 33 patients with iRBD or PD, which provided insight into their requirements (eg, a dual-SIM phone and monetary compensation for mobile phone tariffs), doubts and motivations (such as understanding how to operate the phone and data security) and the expected frequency of phone usage and calls.
Sample size estimation
For the primary endpoint of the project, an ad hoc power analysis for a given large effect size (Cohen’s d of 0.8), with the type I error probability (α) set at 0.05 and power of 80%, based on a three-group analysis of variance with one covariate (group), determined a minimum sample size of 66 subjects with at least 22 subjects in each subgroup (ie, 22 patients with iRBD, 22 patients with PD and 22 controls).
Statistical analysis
A one-way analysis of variance with a group (PD vs iRBD vs controls) as a between-subject factor will be used to calculate the differences for each parameter of interest. The Pearson correlation coefficient will be applied to search for correlations among the variables. The minimum level of significance will be set at p<0.05 with an appropriate Bonferroni adjustment. In addition, a binary logistic regression followed by a leave-one-subject-out cross-validation will be used to assess the sensitivity/specificity of the proposed features to differentiate the iRBD subjects from controls, patients with PD from controls and patients with PD from iRBD subjects.
Ethics and dissemination
The study has been approved by the Ethics Committee of the General University Hospital in Prague, Czech Republic (no. 30/19 Grant AZV VES 2020 VFN), and will be performed in accordance with the ethical standards laid down in the 1964 Declaration of Helsinki and its later amendments. All the participants will provide written, informed consent prior to their inclusion.
The following steps will be taken to mitigate potential ethical concerns: The researchers performing the analyses will have no known relationship with the research subjects, and the recordings will be deidentified to the extent possible. The analyses of audiorecordings will be automated to avoid the recordings being listened to by a human; furthermore, the audiorecordings will be encrypted, will only be available to the authorised researchers, and will be deleted at the request of any participant without the need for justification. All the steps will be conducted according to the directive on personal data protection legislation in the Czech Republic and the approval of the Ethics Committee. Any amendments will be agreed on by the research steering committee and submitted for ethics committee approval prior to implementation.
This project may provide a natural digital biomarker of disease progression based on longitudinal data acquired without any cost or time burden on the patients and investigators. Observing disease progression over a short period using well-defined and disease-specific speech biomarkers may significantly aid in recruiting appropriate cases into large clinical trials for disease-modifying drugs and allows monitoring possible disease-modifying effects of treatment in prodromal PD.42 43 In the future, speech biomarkers may also bolster early presymptomatic diagnosis and enable rapid access to neuroprotective therapy once available. Results will be presented at national and international conferences, published in peer-reviewed journals, and disseminated to the researchers and Parkinson’s community.
Ethics statements
Patient consent for publication
References
Footnotes
TK and VI contributed equally.
Contributors JR conceived of the study and the study design. TK and VI drafted and revised the manuscript. TK and VI designed the application. TK, VI and JR approved the final manuscript.
Funding This study was supported by the Czech Ministry of Health (grant no. NU20-08-00445).
Competing interests None declared.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer reviewed.