





Abstract
Background Cluster randomized trials are increasingly popular. In many of these trials, cluster sizes are unequal. This can affect trial power, but standard sample size formulae for these trials ignore this. Previous studies addressing this issue have mostly focused on continuous outcomes or methods that are sometimes difficult to use in practice.
Methods We show how a simple formula can be used to judge the possible effect of unequal cluster sizes for various types of analyses and both continuous and binary outcomes. We explore the practical estimation of the coefficient of variation of cluster size required in this formula and demonstrate the formula's performance for a hypothetical but typical trial randomizing UK general practices.
Results The simple formula provides a good estimate of sample size requirements for trials analysed using cluster-level analyses weighting by cluster size and a conservative estimate for other types of analyses. For trials randomizing UK general practices the coefficient of variation of cluster size depends on variation in practice list size, variation in incidence or prevalence of the medical condition under examination, and practice and patient recruitment strategies, and for many trials is expected to be ∼0.65. Individual-level analyses can be noticeably more efficient than some cluster-level analyses in this context.
Conclusions When the coefficient of variation is <0.23, the effect of adjustment for variable cluster size on sample size is negligible. Most trials randomizing UK general practices and many other cluster randomized trials should account for variable cluster size in their sample size calculations.
Cluster randomized trials are trials in which groups or clusters of individuals, rather than individuals themselves, are randomized to intervention groups. This long-recognized trial design1 has gained popularity in recent years with the advent of health services research where it is particularly appropriate for investigating organizational change or change in practitioner behaviour.
Many authors have described the statistical consequences of adopting a clustered trial design,2–9 but most assume the same number of individual trial participants (cluster size) in each cluster7,8 or minimal variation in this number.9 Researchers calculating sample sizes for cluster randomized trials also generally ignore variability in cluster size, largely because there has been no appropriate, easily usable, sample size formula, in contrast to a simple formula for trials in which cluster sizes are identical.3 In practice, however, cluster sizes often vary. For example, in a recent review of 153 published and 47 unpublished trials the recruitment strategies in two-thirds of the trials led inevitably to unequal sized clusters.10 Imbalance in cluster size affects trial power.
The way in which cluster size imbalance affects trial power is intuitively obvious if we consider several trials with exactly the same number of clusters and exactly the same total number of trial participants. The most efficient design occurs when cluster sizes are all equal. If cluster sizes are slightly imbalanced then estimates from the smaller clusters will be less precise and estimates from the larger clusters more precise. There are, however, diminishing gains in precision from the addition of an extra individual as cluster sizes increase. This means that the addition of individuals to larger clusters does not compensate for the loss of precision in smaller clusters. Thus, as the cluster sizes become more unbalanced, power decreases.
Two recent studies report a simple formula for the sample size of a cluster randomized trial with variable cluster size and a continuous outcome,11,12 and a third study reports a similar result for binary outcomes.13 Kerry and Bland14 use a formula for binary and continuous outcomes, which requires more knowledge about individual cluster sizes in advance of a trial. These papers do not discuss the practical aspects of estimating the formulae in advance of a trial in detail. In addition, all the formulae strictly apply to analysis at the cluster level, whereas analysis options for cluster randomized trials have increased in recent years, including analysis at the level of the individual appropriately adjusted to account for clustering. In the present paper we (i) show how a simple formula can be used to judge the possible effect of variable cluster size for all types of analyses; (ii) explore the practical estimation of a key quantity required in this formula; and (iii) illustrate the performance of the formula in one particular context for individual-level and cluster-level analyses. We articulate our methods using cluster randomized trials from UK primary health care where these trials are particularly common.10
Method
Judging the possible effect of variable cluster size
Full formulae for sample size requirements for cluster randomized trials are given elsewhere.15 When all clusters are of equal size, m, sample size formulae for estimating the difference between means (or proportions) in intervention groups for a continuous (or binary) outcome differ from comparable formulae for individually randomized trials only by an inflation factor 1 + (m − 1)ρ, usually called the design effect (DE),3 or the variance inflation ratio, because it is the ratio of the variance of an estimate in a cluster trial to the variance in an equivalently sized individually randomized trial. The intra-cluster correlation coefficient (ICC), ρ, is usually defined as the proportion of variance accounted for by between cluster variation.16
More generally, the design effect represents the amount by which the sample size required for an individually randomized trial needs to be multiplied to obtain the sample size required for a trial with a more complex design such as a cluster randomized trial and depends on design and analysis. Here we assume unstratified designs and that clusters are assigned to each intervention group with equal probability. For continuous and binary outcomes common appropriate analyses are: (i) cluster-level analyses weighting by cluster size, (ii) individual-level analyses using a random effect to represent variation between clusters, and (iii) individual-level marginal modelling (population averaged model) using generalized estimating equations (GEEs).3 When cluster sizes vary, the usual design effect formulae for these analyses require knowledge of the actual cluster sizes in a trial, alongside the value of the ICC (Table 1). This information is often not known in advance of a trial.

Estimating coefficient of variation of cluster size
Thus for investigators planning trials with unequal cluster sizes, an idea of the likely value of cv is useful. Here we suggest various ways to estimate this coefficient.
Knowledge of coefficients of variation in similar previous studies (method 1)
We present actual cvs from six trials in which UK general practices were randomized.18–23 The trials were chosen because they vary in size and method of cluster (practice), and individual, recruitment (Table 2); these factors may affect cluster size variation. For example, in three trials (POST,18 ELECTRA,20 and HD21) all practices in a particular geographic area were invited to participate; in the other trials practice eligibility was further restricted. In the AD19 trial, patients were recruited in proportion to number of practice partners, whereas in the LTMI23 trial patients were recruited from practice disease registers of those already identified with long-term mental illness, and cluster size variation depended on variation in disease register size. In the DD22 and POST trials patients were recruited via an event precipitating health service contact; the number of eligible patients was subject to random variability as well as varying with practice list size and practice incidence rate.
Recruitment strategies in six illustration trials
| Trial | Intervention | Practice size (by design) | Method of identifying eligible patients | Newly recognized or patients with condition already known | Numbers of patients (design) | Patients required to consent |
|---|---|---|---|---|---|---|
| AD (Feder 1995)a | Clinical guidelines for asthma and diabetes | Non training practices | Disease register | Known asthmatics or diabetics | 10/GP | No |
| DD (Woodcock 1999)b | Training of GPs in patients centred care | 4 or more partners; list size >7000; diabetic register >1% practice population | New cases of diabetes identified by practice nurse | Incident cases of diabetes | All new cases in 12 months | Yes |
| LTMI (Burns 1997)c | Structured care of patients with long term mental illness | 3 or more partners, teaching practices | Disease register | Known patients with long term mental illness | All patients on register | Yes |
| HDP (Thompson 2000)b | Education package and guidelines to GPs to improve detection and management of depression | Not restricted | Detection—Consecutive adult attendees in General Practice | All attendees | All attendees | Yes |
| Management-positive score on Hospital Anxiety and Depression Scales (HADS) of those screened | All patients with depression whether already known or not | Screening took place until minimum of 30/GP or 40/GP in single handed practices | ||||
| POST (Feder 1999)a | Postal prompts to patients and GP about lowering CHD risk after angina or MI | Not restricted | Admission to hospital with angina or MI | Hospital admissions | All admission in specified period | Yes |
| ELECTRA (Griffiths 2004)a | Asthma liaison nurse and education to primary care clinicians | Not restricted | Patients consulting with asthma exacerbation or patients at high risk identified from GP notes | Consultations (incident cases) and from notes (already identified) | All patients with exacerbation either in study period or in previous 2 years | Yes |
| Trial | Intervention | Practice size (by design) | Method of identifying eligible patients | Newly recognized or patients with condition already known | Numbers of patients (design) | Patients required to consent |
|---|---|---|---|---|---|---|
| AD (Feder 1995)a | Clinical guidelines for asthma and diabetes | Non training practices | Disease register | Known asthmatics or diabetics | 10/GP | No |
| DD (Woodcock 1999)b | Training of GPs in patients centred care | 4 or more partners; list size >7000; diabetic register >1% practice population | New cases of diabetes identified by practice nurse | Incident cases of diabetes | All new cases in 12 months | Yes |
| LTMI (Burns 1997)c | Structured care of patients with long term mental illness | 3 or more partners, teaching practices | Disease register | Known patients with long term mental illness | All patients on register | Yes |
| HDP (Thompson 2000)b | Education package and guidelines to GPs to improve detection and management of depression | Not restricted | Detection—Consecutive adult attendees in General Practice | All attendees | All attendees | Yes |
| Management-positive score on Hospital Anxiety and Depression Scales (HADS) of those screened | All patients with depression whether already known or not | Screening took place until minimum of 30/GP or 40/GP in single handed practices | ||||
| POST (Feder 1999)a | Postal prompts to patients and GP about lowering CHD risk after angina or MI | Not restricted | Admission to hospital with angina or MI | Hospital admissions | All admission in specified period | Yes |
| ELECTRA (Griffiths 2004)a | Asthma liaison nurse and education to primary care clinicians | Not restricted | Patients consulting with asthma exacerbation or patients at high risk identified from GP notes | Consultations (incident cases) and from notes (already identified) | All patients with exacerbation either in study period or in previous 2 years | Yes |
Data held by SE.
Data available from trial authors.
Data held by SK.
Recruitment strategies in six illustration trials
| Trial | Intervention | Practice size (by design) | Method of identifying eligible patients | Newly recognized or patients with condition already known | Numbers of patients (design) | Patients required to consent |
|---|---|---|---|---|---|---|
| AD (Feder 1995)a | Clinical guidelines for asthma and diabetes | Non training practices | Disease register | Known asthmatics or diabetics | 10/GP | No |
| DD (Woodcock 1999)b | Training of GPs in patients centred care | 4 or more partners; list size >7000; diabetic register >1% practice population | New cases of diabetes identified by practice nurse | Incident cases of diabetes | All new cases in 12 months | Yes |
| LTMI (Burns 1997)c | Structured care of patients with long term mental illness | 3 or more partners, teaching practices | Disease register | Known patients with long term mental illness | All patients on register | Yes |
| HDP (Thompson 2000)b | Education package and guidelines to GPs to improve detection and management of depression | Not restricted | Detection—Consecutive adult attendees in General Practice | All attendees | All attendees | Yes |
| Management-positive score on Hospital Anxiety and Depression Scales (HADS) of those screened | All patients with depression whether already known or not | Screening took place until minimum of 30/GP or 40/GP in single handed practices | ||||
| POST (Feder 1999)a | Postal prompts to patients and GP about lowering CHD risk after angina or MI | Not restricted | Admission to hospital with angina or MI | Hospital admissions | All admission in specified period | Yes |
| ELECTRA (Griffiths 2004)a | Asthma liaison nurse and education to primary care clinicians | Not restricted | Patients consulting with asthma exacerbation or patients at high risk identified from GP notes | Consultations (incident cases) and from notes (already identified) | All patients with exacerbation either in study period or in previous 2 years | Yes |
| Trial | Intervention | Practice size (by design) | Method of identifying eligible patients | Newly recognized or patients with condition already known | Numbers of patients (design) | Patients required to consent |
|---|---|---|---|---|---|---|
| AD (Feder 1995)a | Clinical guidelines for asthma and diabetes | Non training practices | Disease register | Known asthmatics or diabetics | 10/GP | No |
| DD (Woodcock 1999)b | Training of GPs in patients centred care | 4 or more partners; list size >7000; diabetic register >1% practice population | New cases of diabetes identified by practice nurse | Incident cases of diabetes | All new cases in 12 months | Yes |
| LTMI (Burns 1997)c | Structured care of patients with long term mental illness | 3 or more partners, teaching practices | Disease register | Known patients with long term mental illness | All patients on register | Yes |
| HDP (Thompson 2000)b | Education package and guidelines to GPs to improve detection and management of depression | Not restricted | Detection—Consecutive adult attendees in General Practice | All attendees | All attendees | Yes |
| Management-positive score on Hospital Anxiety and Depression Scales (HADS) of those screened | All patients with depression whether already known or not | Screening took place until minimum of 30/GP or 40/GP in single handed practices | ||||
| POST (Feder 1999)a | Postal prompts to patients and GP about lowering CHD risk after angina or MI | Not restricted | Admission to hospital with angina or MI | Hospital admissions | All admission in specified period | Yes |
| ELECTRA (Griffiths 2004)a | Asthma liaison nurse and education to primary care clinicians | Not restricted | Patients consulting with asthma exacerbation or patients at high risk identified from GP notes | Consultations (incident cases) and from notes (already identified) | All patients with exacerbation either in study period or in previous 2 years | Yes |
Data held by SE.
Data available from trial authors.
Data held by SK.
Investigating and modelling sources of cluster size variation (method 2)
In discussing sources of cluster size variation we distinguish between the number of individual trial participants in each cluster—‘cluster size’, and the size of the wider pool of individuals from which participants are drawn—‘whole cluster size’. For example, when clusters are general practices the whole cluster size is the number of individuals registered at a practice and the cluster size is the number of trial participants from the practice. Possible sources of variation in cluster size are then: (i) the underlying distribution of whole cluster sizes in the population of clusters, (ii) the sampling strategy for recruiting clusters from this population, (iii) patterns of cluster response and drop-out, (iv) the distribution of eligible individuals within clusters (for example, trials may include just those in particular age and sex categories such as the elderly or children, or, in health care, those with particular conditions such as diabetics or asthmatics), (v) the sampling strategy for recruiting individual participants from clusters, and (vi) patterns of response and drop-out amongst individuals. The importance of each source will vary according to the context. We include in a model what we judge are the major sources for trials randomizing general practices: (i), (ii), and (v). Ignoring the other sources, we implicitly assume that levels of non-response and drop-out are unrelated to cluster size and that the distribution of eligible patients is identical in every cluster. Although limited, data from our illustration trials support some of these assumptions; practice response rates, ranging between 55% (AD) and 100% (ELECTRA), had no discernable relationship with cv and practice drop-out rates were minimal.
We base our modelling of cluster size variation on common characteristics of trials randomizing UK general practices, some of which are exhibited by our illustration trials. We assume that practices are randomly selected from a population with list size distributed according to the list sizes of UK practices. Most trials in the UK (including three illustration trials) select from all practices in one or more primary care trust (PCT),24 and the coefficient of variation of practice size in most PCTs is similar to that for all UK practices (median 0.56, IQR 0.49–0.64).25
We then assume that patients are recruited following an event resulting in health service contact (a strategy employed in three illustration trials). For practice, i, the expected number of trial participants is φi = π * γi where γi is the practice list size, and π the proportion of all patients experiencing this event in the trial period, generated from the assumed mean cluster size in the trial,
We estimate the expected cv from simulated mi values, for trials with mean cluster sizes ranging from 2 to 100. Over 80% of primary health care trials in a recent review had mean cluster sizes within this range.10 The expected value of cv increases with increasing number of clusters, but changes very little for trials with more than 10 clusters; we simulate trials with 1000 clusters; although unrealistic in practice this gives conservative estimates of cv for all trials with fewer clusters. For each mean cluster size we also estimate the expected proportion of empty clusters and adjust the cv because these clusters will be excluded from trial analyses. We use Markov chain Monte Carlo modelling in WinBUGS.26 Full details are in the online supplement.
When investigators are able to estimate likely minimum and maximum cluster sizes (method 3)
This method may be useful when other methods are not feasible, for example when individual trial participants come from subgroups of all individuals in clusters such as particular age or ethnic groups that exhibit a high degree of clustering. Coefficients of variation of cluster size may then be considerably larger than the coefficients of variation of the underlying units.27 If, however, the likely range of clusters sizes can be estimated, the standard deviation of cluster size can be approximated by: likely range/4 (based on the width of the 95% confidence interval of a normal distribution). This approximation, together with an estimate of mean cluster size will give an estimate of cv adequate for sample size calculations. A sensitivity analysis to the likely range may be appropriate.
When all individuals in each recruited cluster participate in a trial (method 4)
In this case, cv varies only according to the clusters sampled. As a ratio of two random quantities, its expectation can be expressed as a Taylor Series around σm/μm28 where μm and σm are the mean and variance of the whole cluster size for all clusters in the population. Simulations similar to those described above suggest that σm/μm is a very close, slightly anti-conservative, approximation to the expectation of cv as long as a trial includes >10 clusters. Even for a smaller number of clusters, using σm/μm may be adequate for sample size estimation, bearing in mind the usual uncertainty in sample size inputs.
When whole cluster sizes are identical (method 5)
This could be the case, when, for example, clinicians with a more or less identical workload and case-mix are randomized. If individual trial participants are recruited from clusters by some random process, the expected distribution of cluster size can be approximated by a Poisson distribution, and cv becomes 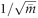 , which tends to zero as
, which tends to zero as
When cluster size follows a roughly normal distribution (method 6)
This could be the case, for example, where patient caseloads within health organizations have a roughly normal distribution and cluster size is heavily dependent on caseload. Since the minimum possible cluster size is always one, the normal approximation must lie almost entirely above zero. The mean must, therefore, be at least 2 SD from zero (approximately) and consequently cv is at most 0.5.
Here we present results based on the first three methods only. These methods are more general in application.
Estimating sample size requirements in practice
We consider four possible estimates of sample size for a hypothetical trial with mean cluster size 10, ICC 0.05, and 200 individuals required if there is no clustering. One estimate accounts for clustering but not variable cluster size [Equation (3)], and three account for variable cluster size using Equation (2) and the first three methods of estimating cv described above. To assess the methods, we compare the four estimated design effects with the sampling distributions of actual design effects assuming (i) cluster-level analyses weighting by cluster size and (ii) GEE analyses assuming an exchangeable correlation structure (applicable for both continuous and binary outcomes) and that variation in cv results from practice and patient recruitment strategies as described for method two above (for details see IJE online).
Results
Judging the possible effect of variable cluster size
The maximum possible increase in sample size due variable cluster size (MIS) increases with increasing cv, ICC, and mean cluster size (Table 3). For a given cv, MIS reaches a maximum of 1 + cv2 as
MIS values for a range of average cluster sizes, coefficients of variation of cluster size and intra-cluster correlation coefficients
| Coefficient of variation of cluster size | Average cluster size | Intra-cluster correlation coefficient | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.001 | 0.01 | 0.05 | 0.1 | 0.2 | 0.3 | |||||||
| 0.4 | 5 | 1.00 | 1.01 | 1.03 | 1.06 | 1.09 | 1.11 | |||||
| 10 | 1.00 | 1.01 | 1.06 | 1.08 | 1.11 | 1.13 | ||||||
| 50 | 1.01 | 1.05 | 1.12 | 1.14 | 1.15 | 1.15 | ||||||
| 100 | 1.01 | 1.08 | 1.13 | 1.15 | 1.15 | 1.16 | ||||||
| 500 | 1.05 | 1.13 | 1.15 | 1.16 | 1.16 | 1.16 | ||||||
| 1000 | 1.08 | 1.15 | 1.16 | 1.16 | 1.16 | 1.16 | ||||||
| 0.5 | 5 | 1.00 | 1.01 | 1.05 | 1.09 | 1.14 | 1.17 | |||||
| 10 | 1.00 | 1.02 | 1.09 | 1.13 | 1.18 | 1.20 | ||||||
| 50 | 1.01 | 1.08 | 1.18 | 1.21 | 1.23 | 1.24 | ||||||
| 100 | 1.02 | 1.13 | 1.21 | 1.23 | 1.24 | 1.24 | ||||||
| 500 | 1.08 | 1.21 | 1.24 | 1.25 | 1.25 | 1.25 | ||||||
| 1000 | 1.13 | 1.23 | 1.25 | 1.25 | 1.25 | 1.25 | ||||||
| 0.6 | 5 | 1.00 | 1.02 | 1.08 | 1.13 | 1.20 | 1.25 | |||||
| 10 | 1.00 | 1.03 | 1.12 | 1.19 | 1.26 | 1.29 | ||||||
| 50 | 1.02 | 1.12 | 1.26 | 1.31 | 1.33 | 1.34 | ||||||
| 100 | 1.03 | 1.18 | 1.30 | 1.33 | 1.35 | 1.35 | ||||||
| 500 | 1.12 | 1.30 | 1.35 | 1.35 | 1.36 | 1.36 | ||||||
| 1000 | 1.18 | 1.33 | 1.35 | 1.36 | 1.36 | 1.36 | ||||||
| 0.7 | 5 | 1.00 | 1.02 | 1.10 | 1.18 | 1.27 | 1.33 | |||||
| 10 | 1.00 | 1.04 | 1.17 | 1.26 | 1.35 | 1.40 | ||||||
| 50 | 1.02 | 1.16 | 1.36 | 1.42 | 1.45 | 1.47 | ||||||
| 100 | 1.04 | 1.25 | 1.41 | 1.45 | 1.47 | 1.48 | ||||||
| 500 | 1.16 | 1.41 | 1.47 | 1.48 | 1.49 | 1.49 | ||||||
| 1000 | 1.25 | 1.45 | 1.48 | 1.49 | 1.49 | 1.49 | ||||||
| 0.8 | 5 | 1.00 | 1.03 | 1.13 | 1.23 | 1.36 | 1.44 | |||||
| 10 | 1.01 | 1.06 | 1.22 | 1.34 | 1.46 | 1.52 | ||||||
| 50 | 1.03 | 1.21 | 1.46 | 1.54 | 1.59 | 1.61 | ||||||
| 100 | 1.06 | 1.32 | 1.54 | 1.59 | 1.62 | 1.63 | ||||||
| 500 | 1.21 | 1.53 | 1.62 | 1.63 | 1.63 | 1.64 | ||||||
| 1000 | 1.32 | 1.58 | 1.63 | 1.63 | 1.64 | 1.64 | ||||||
| 0.9 | 5 | 1.00 | 1.04 | 1.17 | 1.29 | 1.45 | 1.55 | |||||
| 10 | 1.01 | 1.07 | 1.28 | 1.43 | 1.58 | 1.66 | ||||||
| 50 | 1.04 | 1.27 | 1.59 | 1.69 | 1.75 | 1.77 | ||||||
| 100 | 1.07 | 1.41 | 1.68 | 1.74 | 1.78 | 1.79 | ||||||
| 500 | 1.27 | 1.68 | 1.78 | 1.80 | 1.80 | 1.81 | ||||||
| 1000 | 1.41 | 1.74 | 1.79 | 1.80 | 1.81 | 1.81 | ||||||
| 1 | 5 | 1.00 | 1.05 | 1.21 | 1.36 | 1.56 | 1.68 | |||||
| 10 | 1.01 | 1.09 | 1.34 | 1.53 | 1.71 | 1.81 | ||||||
| 50 | 1.05 | 1.34 | 1.72 | 1.85 | 1.93 | 1.96 | ||||||
| 100 | 1.09 | 1.50 | 1.84 | 1.92 | 1.96 | 1.98 | ||||||
| 500 | 1.33 | 1.83 | 1.96 | 1.98 | 1.99 | 2.00 | ||||||
| 1000 | 1.50 | 1.91 | 1.98 | 1.99 | 2.00 | 2.00 | ||||||
| Coefficient of variation of cluster size | Average cluster size | Intra-cluster correlation coefficient | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.001 | 0.01 | 0.05 | 0.1 | 0.2 | 0.3 | |||||||
| 0.4 | 5 | 1.00 | 1.01 | 1.03 | 1.06 | 1.09 | 1.11 | |||||
| 10 | 1.00 | 1.01 | 1.06 | 1.08 | 1.11 | 1.13 | ||||||
| 50 | 1.01 | 1.05 | 1.12 | 1.14 | 1.15 | 1.15 | ||||||
| 100 | 1.01 | 1.08 | 1.13 | 1.15 | 1.15 | 1.16 | ||||||
| 500 | 1.05 | 1.13 | 1.15 | 1.16 | 1.16 | 1.16 | ||||||
| 1000 | 1.08 | 1.15 | 1.16 | 1.16 | 1.16 | 1.16 | ||||||
| 0.5 | 5 | 1.00 | 1.01 | 1.05 | 1.09 | 1.14 | 1.17 | |||||
| 10 | 1.00 | 1.02 | 1.09 | 1.13 | 1.18 | 1.20 | ||||||
| 50 | 1.01 | 1.08 | 1.18 | 1.21 | 1.23 | 1.24 | ||||||
| 100 | 1.02 | 1.13 | 1.21 | 1.23 | 1.24 | 1.24 | ||||||
| 500 | 1.08 | 1.21 | 1.24 | 1.25 | 1.25 | 1.25 | ||||||
| 1000 | 1.13 | 1.23 | 1.25 | 1.25 | 1.25 | 1.25 | ||||||
| 0.6 | 5 | 1.00 | 1.02 | 1.08 | 1.13 | 1.20 | 1.25 | |||||
| 10 | 1.00 | 1.03 | 1.12 | 1.19 | 1.26 | 1.29 | ||||||
| 50 | 1.02 | 1.12 | 1.26 | 1.31 | 1.33 | 1.34 | ||||||
| 100 | 1.03 | 1.18 | 1.30 | 1.33 | 1.35 | 1.35 | ||||||
| 500 | 1.12 | 1.30 | 1.35 | 1.35 | 1.36 | 1.36 | ||||||
| 1000 | 1.18 | 1.33 | 1.35 | 1.36 | 1.36 | 1.36 | ||||||
| 0.7 | 5 | 1.00 | 1.02 | 1.10 | 1.18 | 1.27 | 1.33 | |||||
| 10 | 1.00 | 1.04 | 1.17 | 1.26 | 1.35 | 1.40 | ||||||
| 50 | 1.02 | 1.16 | 1.36 | 1.42 | 1.45 | 1.47 | ||||||
| 100 | 1.04 | 1.25 | 1.41 | 1.45 | 1.47 | 1.48 | ||||||
| 500 | 1.16 | 1.41 | 1.47 | 1.48 | 1.49 | 1.49 | ||||||
| 1000 | 1.25 | 1.45 | 1.48 | 1.49 | 1.49 | 1.49 | ||||||
| 0.8 | 5 | 1.00 | 1.03 | 1.13 | 1.23 | 1.36 | 1.44 | |||||
| 10 | 1.01 | 1.06 | 1.22 | 1.34 | 1.46 | 1.52 | ||||||
| 50 | 1.03 | 1.21 | 1.46 | 1.54 | 1.59 | 1.61 | ||||||
| 100 | 1.06 | 1.32 | 1.54 | 1.59 | 1.62 | 1.63 | ||||||
| 500 | 1.21 | 1.53 | 1.62 | 1.63 | 1.63 | 1.64 | ||||||
| 1000 | 1.32 | 1.58 | 1.63 | 1.63 | 1.64 | 1.64 | ||||||
| 0.9 | 5 | 1.00 | 1.04 | 1.17 | 1.29 | 1.45 | 1.55 | |||||
| 10 | 1.01 | 1.07 | 1.28 | 1.43 | 1.58 | 1.66 | ||||||
| 50 | 1.04 | 1.27 | 1.59 | 1.69 | 1.75 | 1.77 | ||||||
| 100 | 1.07 | 1.41 | 1.68 | 1.74 | 1.78 | 1.79 | ||||||
| 500 | 1.27 | 1.68 | 1.78 | 1.80 | 1.80 | 1.81 | ||||||
| 1000 | 1.41 | 1.74 | 1.79 | 1.80 | 1.81 | 1.81 | ||||||
| 1 | 5 | 1.00 | 1.05 | 1.21 | 1.36 | 1.56 | 1.68 | |||||
| 10 | 1.01 | 1.09 | 1.34 | 1.53 | 1.71 | 1.81 | ||||||
| 50 | 1.05 | 1.34 | 1.72 | 1.85 | 1.93 | 1.96 | ||||||
| 100 | 1.09 | 1.50 | 1.84 | 1.92 | 1.96 | 1.98 | ||||||
| 500 | 1.33 | 1.83 | 1.96 | 1.98 | 1.99 | 2.00 | ||||||
| 1000 | 1.50 | 1.91 | 1.98 | 1.99 | 2.00 | 2.00 | ||||||
MIS values for a range of average cluster sizes, coefficients of variation of cluster size and intra-cluster correlation coefficients
| Coefficient of variation of cluster size | Average cluster size | Intra-cluster correlation coefficient | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.001 | 0.01 | 0.05 | 0.1 | 0.2 | 0.3 | |||||||
| 0.4 | 5 | 1.00 | 1.01 | 1.03 | 1.06 | 1.09 | 1.11 | |||||
| 10 | 1.00 | 1.01 | 1.06 | 1.08 | 1.11 | 1.13 | ||||||
| 50 | 1.01 | 1.05 | 1.12 | 1.14 | 1.15 | 1.15 | ||||||
| 100 | 1.01 | 1.08 | 1.13 | 1.15 | 1.15 | 1.16 | ||||||
| 500 | 1.05 | 1.13 | 1.15 | 1.16 | 1.16 | 1.16 | ||||||
| 1000 | 1.08 | 1.15 | 1.16 | 1.16 | 1.16 | 1.16 | ||||||
| 0.5 | 5 | 1.00 | 1.01 | 1.05 | 1.09 | 1.14 | 1.17 | |||||
| 10 | 1.00 | 1.02 | 1.09 | 1.13 | 1.18 | 1.20 | ||||||
| 50 | 1.01 | 1.08 | 1.18 | 1.21 | 1.23 | 1.24 | ||||||
| 100 | 1.02 | 1.13 | 1.21 | 1.23 | 1.24 | 1.24 | ||||||
| 500 | 1.08 | 1.21 | 1.24 | 1.25 | 1.25 | 1.25 | ||||||
| 1000 | 1.13 | 1.23 | 1.25 | 1.25 | 1.25 | 1.25 | ||||||
| 0.6 | 5 | 1.00 | 1.02 | 1.08 | 1.13 | 1.20 | 1.25 | |||||
| 10 | 1.00 | 1.03 | 1.12 | 1.19 | 1.26 | 1.29 | ||||||
| 50 | 1.02 | 1.12 | 1.26 | 1.31 | 1.33 | 1.34 | ||||||
| 100 | 1.03 | 1.18 | 1.30 | 1.33 | 1.35 | 1.35 | ||||||
| 500 | 1.12 | 1.30 | 1.35 | 1.35 | 1.36 | 1.36 | ||||||
| 1000 | 1.18 | 1.33 | 1.35 | 1.36 | 1.36 | 1.36 | ||||||
| 0.7 | 5 | 1.00 | 1.02 | 1.10 | 1.18 | 1.27 | 1.33 | |||||
| 10 | 1.00 | 1.04 | 1.17 | 1.26 | 1.35 | 1.40 | ||||||
| 50 | 1.02 | 1.16 | 1.36 | 1.42 | 1.45 | 1.47 | ||||||
| 100 | 1.04 | 1.25 | 1.41 | 1.45 | 1.47 | 1.48 | ||||||
| 500 | 1.16 | 1.41 | 1.47 | 1.48 | 1.49 | 1.49 | ||||||
| 1000 | 1.25 | 1.45 | 1.48 | 1.49 | 1.49 | 1.49 | ||||||
| 0.8 | 5 | 1.00 | 1.03 | 1.13 | 1.23 | 1.36 | 1.44 | |||||
| 10 | 1.01 | 1.06 | 1.22 | 1.34 | 1.46 | 1.52 | ||||||
| 50 | 1.03 | 1.21 | 1.46 | 1.54 | 1.59 | 1.61 | ||||||
| 100 | 1.06 | 1.32 | 1.54 | 1.59 | 1.62 | 1.63 | ||||||
| 500 | 1.21 | 1.53 | 1.62 | 1.63 | 1.63 | 1.64 | ||||||
| 1000 | 1.32 | 1.58 | 1.63 | 1.63 | 1.64 | 1.64 | ||||||
| 0.9 | 5 | 1.00 | 1.04 | 1.17 | 1.29 | 1.45 | 1.55 | |||||
| 10 | 1.01 | 1.07 | 1.28 | 1.43 | 1.58 | 1.66 | ||||||
| 50 | 1.04 | 1.27 | 1.59 | 1.69 | 1.75 | 1.77 | ||||||
| 100 | 1.07 | 1.41 | 1.68 | 1.74 | 1.78 | 1.79 | ||||||
| 500 | 1.27 | 1.68 | 1.78 | 1.80 | 1.80 | 1.81 | ||||||
| 1000 | 1.41 | 1.74 | 1.79 | 1.80 | 1.81 | 1.81 | ||||||
| 1 | 5 | 1.00 | 1.05 | 1.21 | 1.36 | 1.56 | 1.68 | |||||
| 10 | 1.01 | 1.09 | 1.34 | 1.53 | 1.71 | 1.81 | ||||||
| 50 | 1.05 | 1.34 | 1.72 | 1.85 | 1.93 | 1.96 | ||||||
| 100 | 1.09 | 1.50 | 1.84 | 1.92 | 1.96 | 1.98 | ||||||
| 500 | 1.33 | 1.83 | 1.96 | 1.98 | 1.99 | 2.00 | ||||||
| 1000 | 1.50 | 1.91 | 1.98 | 1.99 | 2.00 | 2.00 | ||||||
| Coefficient of variation of cluster size | Average cluster size | Intra-cluster correlation coefficient | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.001 | 0.01 | 0.05 | 0.1 | 0.2 | 0.3 | |||||||
| 0.4 | 5 | 1.00 | 1.01 | 1.03 | 1.06 | 1.09 | 1.11 | |||||
| 10 | 1.00 | 1.01 | 1.06 | 1.08 | 1.11 | 1.13 | ||||||
| 50 | 1.01 | 1.05 | 1.12 | 1.14 | 1.15 | 1.15 | ||||||
| 100 | 1.01 | 1.08 | 1.13 | 1.15 | 1.15 | 1.16 | ||||||
| 500 | 1.05 | 1.13 | 1.15 | 1.16 | 1.16 | 1.16 | ||||||
| 1000 | 1.08 | 1.15 | 1.16 | 1.16 | 1.16 | 1.16 | ||||||
| 0.5 | 5 | 1.00 | 1.01 | 1.05 | 1.09 | 1.14 | 1.17 | |||||
| 10 | 1.00 | 1.02 | 1.09 | 1.13 | 1.18 | 1.20 | ||||||
| 50 | 1.01 | 1.08 | 1.18 | 1.21 | 1.23 | 1.24 | ||||||
| 100 | 1.02 | 1.13 | 1.21 | 1.23 | 1.24 | 1.24 | ||||||
| 500 | 1.08 | 1.21 | 1.24 | 1.25 | 1.25 | 1.25 | ||||||
| 1000 | 1.13 | 1.23 | 1.25 | 1.25 | 1.25 | 1.25 | ||||||
| 0.6 | 5 | 1.00 | 1.02 | 1.08 | 1.13 | 1.20 | 1.25 | |||||
| 10 | 1.00 | 1.03 | 1.12 | 1.19 | 1.26 | 1.29 | ||||||
| 50 | 1.02 | 1.12 | 1.26 | 1.31 | 1.33 | 1.34 | ||||||
| 100 | 1.03 | 1.18 | 1.30 | 1.33 | 1.35 | 1.35 | ||||||
| 500 | 1.12 | 1.30 | 1.35 | 1.35 | 1.36 | 1.36 | ||||||
| 1000 | 1.18 | 1.33 | 1.35 | 1.36 | 1.36 | 1.36 | ||||||
| 0.7 | 5 | 1.00 | 1.02 | 1.10 | 1.18 | 1.27 | 1.33 | |||||
| 10 | 1.00 | 1.04 | 1.17 | 1.26 | 1.35 | 1.40 | ||||||
| 50 | 1.02 | 1.16 | 1.36 | 1.42 | 1.45 | 1.47 | ||||||
| 100 | 1.04 | 1.25 | 1.41 | 1.45 | 1.47 | 1.48 | ||||||
| 500 | 1.16 | 1.41 | 1.47 | 1.48 | 1.49 | 1.49 | ||||||
| 1000 | 1.25 | 1.45 | 1.48 | 1.49 | 1.49 | 1.49 | ||||||
| 0.8 | 5 | 1.00 | 1.03 | 1.13 | 1.23 | 1.36 | 1.44 | |||||
| 10 | 1.01 | 1.06 | 1.22 | 1.34 | 1.46 | 1.52 | ||||||
| 50 | 1.03 | 1.21 | 1.46 | 1.54 | 1.59 | 1.61 | ||||||
| 100 | 1.06 | 1.32 | 1.54 | 1.59 | 1.62 | 1.63 | ||||||
| 500 | 1.21 | 1.53 | 1.62 | 1.63 | 1.63 | 1.64 | ||||||
| 1000 | 1.32 | 1.58 | 1.63 | 1.63 | 1.64 | 1.64 | ||||||
| 0.9 | 5 | 1.00 | 1.04 | 1.17 | 1.29 | 1.45 | 1.55 | |||||
| 10 | 1.01 | 1.07 | 1.28 | 1.43 | 1.58 | 1.66 | ||||||
| 50 | 1.04 | 1.27 | 1.59 | 1.69 | 1.75 | 1.77 | ||||||
| 100 | 1.07 | 1.41 | 1.68 | 1.74 | 1.78 | 1.79 | ||||||
| 500 | 1.27 | 1.68 | 1.78 | 1.80 | 1.80 | 1.81 | ||||||
| 1000 | 1.41 | 1.74 | 1.79 | 1.80 | 1.81 | 1.81 | ||||||
| 1 | 5 | 1.00 | 1.05 | 1.21 | 1.36 | 1.56 | 1.68 | |||||
| 10 | 1.01 | 1.09 | 1.34 | 1.53 | 1.71 | 1.81 | ||||||
| 50 | 1.05 | 1.34 | 1.72 | 1.85 | 1.93 | 1.96 | ||||||
| 100 | 1.09 | 1.50 | 1.84 | 1.92 | 1.96 | 1.98 | ||||||
| 500 | 1.33 | 1.83 | 1.96 | 1.98 | 1.99 | 2.00 | ||||||
| 1000 | 1.50 | 1.91 | 1.98 | 1.99 | 2.00 | 2.00 | ||||||
Estimation of the coefficient of variation of cluster size
Knowledge of coefficients of variation from previous similar trials.
Our illustration trials have cvs between 0.42 and 0.75 (Figure 1, Table 4), the lowest occurring for the LTMI trial in which only large training practices were eligible to participate. The other trials have cvs in a narrow range (0.61–0.75) in spite of varying design features. For similar trials expected values of cv could be estimated from these values.
Distribution of cluster sizes for six illustration trials
Distribution of cluster sizes and coefficient of variation for six illustration trials
| Coefficient of variation of cluster sizes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of clusters | Mean cluster size | Standard deviation | Minimum cluster size | Maximum cluster size | Observed | Expected, method 2 | Expected, method 3 | |||
| AD | 24 | 16.25 | 11.73 | 10 | 60 | 0.72 | 0.68 | 0.77 | ||
| DD | 40 | 6.25 | 3.81 | 1 | 18 | 0.61 | 0.71 | 0.68 | ||
| LTMI | 16 | 23.31 | 9.91 | 8 | 48 | 0.42 | 0.67 | 0.43 | ||
| HD | 55 | 109.78 | 68.06 | 41 | 295 | 0.62 | 0.63 | 0.58 | ||
| POST | 52 | 6.31 | 4.75 | 1 | 23 | 0.75 | 0.71 | 0.72 | ||
| ELECTRA | 41 | 7.78 | 4.95 | 2 | 28 | 0.64 | 0.72 | 0.84 | ||
| Coefficient of variation of cluster sizes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of clusters | Mean cluster size | Standard deviation | Minimum cluster size | Maximum cluster size | Observed | Expected, method 2 | Expected, method 3 | |||
| AD | 24 | 16.25 | 11.73 | 10 | 60 | 0.72 | 0.68 | 0.77 | ||
| DD | 40 | 6.25 | 3.81 | 1 | 18 | 0.61 | 0.71 | 0.68 | ||
| LTMI | 16 | 23.31 | 9.91 | 8 | 48 | 0.42 | 0.67 | 0.43 | ||
| HD | 55 | 109.78 | 68.06 | 41 | 295 | 0.62 | 0.63 | 0.58 | ||
| POST | 52 | 6.31 | 4.75 | 1 | 23 | 0.75 | 0.71 | 0.72 | ||
| ELECTRA | 41 | 7.78 | 4.95 | 2 | 28 | 0.64 | 0.72 | 0.84 | ||
Distribution of cluster sizes and coefficient of variation for six illustration trials
| Coefficient of variation of cluster sizes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of clusters | Mean cluster size | Standard deviation | Minimum cluster size | Maximum cluster size | Observed | Expected, method 2 | Expected, method 3 | |||
| AD | 24 | 16.25 | 11.73 | 10 | 60 | 0.72 | 0.68 | 0.77 | ||
| DD | 40 | 6.25 | 3.81 | 1 | 18 | 0.61 | 0.71 | 0.68 | ||
| LTMI | 16 | 23.31 | 9.91 | 8 | 48 | 0.42 | 0.67 | 0.43 | ||
| HD | 55 | 109.78 | 68.06 | 41 | 295 | 0.62 | 0.63 | 0.58 | ||
| POST | 52 | 6.31 | 4.75 | 1 | 23 | 0.75 | 0.71 | 0.72 | ||
| ELECTRA | 41 | 7.78 | 4.95 | 2 | 28 | 0.64 | 0.72 | 0.84 | ||
| Coefficient of variation of cluster sizes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of clusters | Mean cluster size | Standard deviation | Minimum cluster size | Maximum cluster size | Observed | Expected, method 2 | Expected, method 3 | |||
| AD | 24 | 16.25 | 11.73 | 10 | 60 | 0.72 | 0.68 | 0.77 | ||
| DD | 40 | 6.25 | 3.81 | 1 | 18 | 0.61 | 0.71 | 0.68 | ||
| LTMI | 16 | 23.31 | 9.91 | 8 | 48 | 0.42 | 0.67 | 0.43 | ||
| HD | 55 | 109.78 | 68.06 | 41 | 295 | 0.62 | 0.63 | 0.58 | ||
| POST | 52 | 6.31 | 4.75 | 1 | 23 | 0.75 | 0.71 | 0.72 | ||
| ELECTRA | 41 | 7.78 | 4.95 | 2 | 28 | 0.64 | 0.72 | 0.84 | ||
Investigating and modelling sources of variation
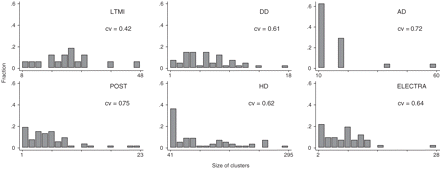
Using modelling, expected cvs for all practices agreeing to participate in a trial (Figure 2, top line) decrease from a maximum of 0.95 as mean cluster size increases. The more appropriate cv to use in a sample size calculation, that for all analysed practices (Figure 2, bottom line), is at a maximum of 0.71 at a mean cluster size of five and tends towards the underlying coefficient of variation of practice list sizes, 0.63, as mean cluster size increases. Using this method, expected cvs for our illustration trials range from 0.63 to 0.71 (Table 4).
Expected coefficient of variation of cluster size (top line represents coefficient for all practices randomized and bottom line coefficient of variation for all practices contributing to analysis, excluding randomized practices providing no patients) by average cluster size for trials randomizing UK general practices
When investigators can estimate likely minimum and maximum cluster sizes.
Using actual minimum and maximum cluster size values from our illustration trials, estimated cvs range from 0.43 to 0.84 and are close to actual cvs (Table 4). In practice actual minimum and maximum cluster sizes are unlikely to be available in advance of a trial, but reasonably accurate estimates may provide an adequate estimate of cv.
Estimating sample size requirements in practice
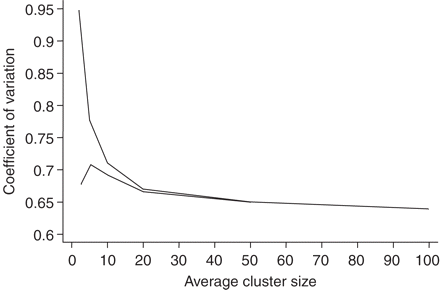
For our hypothetical trial, sample size estimates range from 34 to 38 practices when variable cluster size is accounted for, and 29 practices when it is not (Figure 3). Sampling distributions of design effects for cluster-level and GEE analyses are virtually identical for trials containing 29, 33, 34, or 38 clusters; we show the distribution for 38 clusters (Figure 4). As expected, GEE analyses are more efficient than cluster-level analyses. The design effect calculated ignoring variable cluster size underestimates sample size required in over 98% (99%) of trials using GEE (cluster-level) analyses.

The effect of variable cluster size on sample size requirements in a hypothetical trial. Note: The four design effects compared with sampling distributions of actual design effects are shown in bold in this figure
Four advance estimates of design effect compared with the sampling distribution of actual design effects for our hypothetical trial
Discussion
The design effect for a cluster randomized trial with unequal cluster sizes analysed using cluster-level analyses weighting by cluster size can be estimated from the coefficient of variation of cluster size, mean cluster size, and the ICC expected in the trial. This design effect is conservative for individual-level analyses. For a specific cv, the maximum possible increase in sample size required to allow for variable cluster size is 1 + cv2. Trials randomizing UK general practices commonly have cvs ∼ 0.65, which can result in sample size increases of up to 42%.
The strength of the simple design effect formula used in this paper is its simplicity. In addition to elements used in the sample size calculation assuming equal cluster sizes our formula only requires an estimate of either the standard deviation or cv. A potential weakness is that accurate estimates of these quantities may not always be easy to obtain. We have presented various methods of estimating cv. The accuracy of any method will depend on the extent to which it incorporates relevant important sources of cluster size variation.
A further drawback of using any simple design effect formula, including the one presented here, is that its appropriateness depends on the accuracy of ICC predictions. The size of many cluster randomized trials can lead to considerable sampling error in an ICC estimate, and any simple formula may work less well for small trials. Analysis method can also affect the value of the ICC.29 A Bayesian approach to analysis in which the ICC is determined by a prior distribution as well as the trial data itself may alleviate the problem of uncertainty in predicting the ICC.
Similar formulae to the one we present have been derived previously.11–13 Manatunga and Hudgens briefly discuss the implications of their formula for sample size calculations assuming that cluster size variation can be completely determined by the distribution of whole cluster sizes in the population of clusters. Our discussion of the estimation of cluster size variation incorporates other important sources of variation. Our formula is not directly applicable to individual-level analyses. We show the relative efficiency of GEE analyses compared with cluster-level analyses weighting by cluster size in one particular setting. Previous work has shown the increased efficiency advantages of analyses other than this type of cluster-level analysis when cluster sizes are large.14 We plan to explore relative efficiency further in a future paper.
One implication of our work is that investigators should consider the possible impact of variable cluster size on trial power, particularly when variation in cluster size, the ICC or mean cluster size are expected to be large. Given the uncertain nature of sample size calculations, however, it is almost certainly not necessary to adjust sample size to take account of this variation when cv is <0.23. Our results also emphasize the importance of small cluster sizes in an efficient design.
We focus here on applications in one specific context: primary health care. The basic techniques we present are completely general, but researchers working in other fields, with different types of clusters, will need to consider the methods in their own situations. We have only considered continuous and binary outcomes in this paper, and have not considered stratified designs. The comparison of design effects under different analyses needs developing further.
We would like to thank Obi Ukoumunne, Mike Campbell, and Chris Frost for helpful comments on this work, and the authors of the Diabetes Care from Diagnosis trial and Hampshire Depression Project for permission to use their trial data. Sandra Eldridge's work was funded by an NHS Executive Primary Care Researcher Development Award.
Many cluster randomized trials have variable cluster sizes, which should be accounted for in sample size calculations.
A simple formula provides a good estimate of sample size requirements for some types of analyses and a conservative estimate for other types of analyses.
The coefficient of variation of cluster size needed for this formula can be estimated in several ways.
For trials randomizing UK general practices individual-level analyses can be noticeably more efficient than cluster-level analyses weighting by cluster size.
When the coefficient of variation is <0.23, the effect of adjustment for variable cluster size on sample size is negligible.
References
Donner A, Klar N. Statistical considerations in the design and analysis of community intervention trials.
Donner A, Klar N. Design and Analysis of Cluster Randomised Trials in Health Research. London: Arnold,
Kerry SM, Bland JM. Trials which randomize practices I: how should they be analysed?
Donner A. Some aspects of the design and analysis of cluster randomised trials.
Hayes RJ, Bennett S. Simple sample size calculation for cluster-randomized trials.
Donner A. Sample size requirements for stratified cluster randomization designs.
Eldridge S, Ashby D, Feder G, Rudnicka AR, Ukoumunne OC. Lessons for cluster randomised trials in the twenty-first century: a systematic review of trials in primary care.
Lake S, Kammann E, Klar N, Betensky R. Sample size re-estimation in cluster randomization trials.
Manatunga AK, Hudgens MG. Sample size estimation in cluster randomised studies with varying cluster size.
Kang SH, Ahn CW, Jung SH. Sample size calculation for dichotomous outcomes in cluster randomization trials with varying cluster size.
Kerry SM, Bland JM. Unequal cluster sizes for trials in English and Welsh general practice: implications for sample size calculations.
Donner A, Birkett N, Buck C. Randomization by cluster. Sample size requirements and analysis.
Kerry SM, Bland JM. The intracluster correlation coefficient in cluster randomisation.
Pan W. Sample size and power calculations with correlated binary data.
Feder G, Griffiths C, Eldridge S, Spence M. Effect of postal prompts to patients and general practitioners on the quality of primary care after a coronary event (POST): randomised controlled trial.
Feder G, Griffiths C, Highton C, Eldridge S, Spence M, Southgate L. Do clinical guidelines introduced with practice based education improve care of asthmatic and diabetic patients? A randomised controlled trial in general practices in east London.
Griffiths C, Foster G, Barnes N et al. Specialist nurse intervention to reduce unscheduled asthma care in a deprived multiethnic area: the east London randomised controlled trial for high risk asthma (ELECTRA).
Thompson C, Kinmonth AL, Stevens L et al. Effects of a clinical-practice guideline and practice-based education on detection and outcome of depression in primary care: Hampshire Depression Project randomised controlled trial.
Woodcock AJ, Kinmonth AL, Campbell MJ, Griffin SJ, Spiegal NM. Diabetes care from diagnosis: effects of training in patient-centred care on beliefs, attitudes and behaviour of primary care professionals.
Burns T, Kendrick T. Care of long-term mentally ill patients by British general practitioners.
Department of Health. Primary Care Trusts.
Department of Health (
Spiegelhalter D, Thomas A, Best N. WinBUGS Version 1.4.
Verma V, Le T. An analysis of sampling errors for the Demographic Health Surveys.


{kind=link}
{kind=link}
{kind=link}
{kind=link}