Article Text

Abstract
Objectives The aim of this work was to train machine learning models to identify patients at end of life with clinically meaningful diagnostic accuracy, using 30-day mortality in patients discharged from the emergency department (ED) as a proxy.
Design Retrospective, population-based registry study.
Setting Swedish health services.
Primary and secondary outcome measures All cause 30-day mortality.
Methods Electronic health records (EHRs) and administrative data were used to train six supervised machine learning models to predict all-cause mortality within 30 days in patients discharged from EDs in southern Sweden, Europe.
Participants The models were trained using 65 776 ED visits and validated on 55 164 visits from a separate ED to which the models were not exposed during training.
Results The outcome occurred in 136 visits (0.21%) in the development set and in 83 visits (0.15%) in the validation set. The model with highest discrimination attained ROC–AUC 0.95 (95% CI 0.93 to 0.96), with sensitivity 0.87 (95% CI 0.80 to 0.93) and specificity 0.86 (0.86 to 0.86) on the validation set.
Conclusions Multiple models displayed excellent discrimination on the validation set and outperformed available indexes for short-term mortality prediction interms of ROC–AUC (by indirect comparison). The practical utility of the models increases as the data they were trained on did not require costly de novo collection but were real-world data generated as a by-product of routine care delivery.
- emergency medicine
- mortality
- machine learning
- advance care planning
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
In this study, we report the performance of supervised machine learning models that were trained on a population-based retrospective real-world material of high completeness with minimal loss to follow-up.
The models make use of standard data elements readily capturable in many electronic health record systems for training, which we believe facilitates their implementation across systems and reduces susceptibility to institution-specific biases.
The models were tuned using cross-validation and thereafter validated on an external sample from a site to which they were previously unexposed, improving external validity.
Prospective validation is needed to fully assess model impact in clinical practice.
Given the flexibility of machine learning models and the resulting risk of overfitting, models should be retrained if implemented at a new site and periodically when used in clinical practice.
Background
As healthcare costs increase in the USA and across the globe,1–3 evidence suggests that advances in healthcare technologies and increased utilisation of these technologies are important drivers.3 While technological advancements may result in improved diagnostics and treatments, the return on investment of healthcare spending in terms of life expectancy has decreased over time.4 In turn, this questions whether new medical technologies are always used wisely.
The definition of value in healthcare suggests that value is eroded when patients with low probability of benefit are overtreated with risky or costly procedures,5 potentially causing net harm. The fee-for-service model has been implicated in promoting such value erosion by incentivizing volume and price of care irrespective of its quality.6 Although randomised trials on the topic are lacking, observational studies of variation in US healthcare spending have failed to show an association between higher spending and better quality of care.7 8 Rather, higher spending has been associated with poorer care experiences.9 10 Associations between more aggressive treatment near end of life (EOL) and poorer quality of life in cancer patients,11 12 as well as indications that aggressive treatment may not always be in line with patient preferences13–16 even suggest that patient autonomy may be jeopardised at EOL. We are not aware of firm evidence linking overtreatment to the recently observed fall in US life expectancy.17
We argue that the first step in improving EOL care and reducing overtreatment at EOL is to identify terminally ill patients who could benefit from proactive discussions about their preferences in order to reduce the risk of overtreatment. While surrogate decision-making such as advance directives and do not resuscitate orders are already part of clinical practice, previous work indicates that they are used too infrequently and sometimes fail to take patients’ preferences into account.14 18 Buying into the hypothesis that patients who are given an opportunity to communicate their EOL preferences are more likely to receive EOL care that are in line with their preferences,14 19 we aimed to train supervised machine learning models to identify patients at EOL. Our ambition is that the final models can subsequently be used to systematically identify patients who may benefit from a discussion about EOL care without significantly adding to the workload of healthcare practitioners. We set out to study patients discharged from the emergency department (ED) as this population is both accessible for screening and contain terminally ill patients without clear advance directives, whose conditions deteriorate.
Methods
Study design
The study was conducted as a retrospective, population-based registry study utilising data from a comprehensive healthcare analysis platform in Region Halland, southern Sweden. A consecutive sample of ED visits in the region from 1 January 2015 to 31 December 2016 were included. Data were collected using an analysis platform that connects various sources, including medical (electronic health records, EHR) and administrative data from healthcare providers in the region. Data were linked to the Swedish population register to assess the outcome. All-cause 30-day mortality in patients discharged from the ED was used for the primary outcome as we believe it serves as a reasonable proxy for patients at EOL. Discharged patients were deliberately selected as they largely reflect situations where the attending physician judges that acute inpatient admission is of limited benefit. Visits resulting in admission to inpatient departments or referral to other hospitals on ED discharge were excluded, as well as visits where the patient died in the ED, and visits to the psychiatric ED. No interventions or treatments were administered. The study was approved by The Regional Ethical Review Board in Lund, Dnr 2016/517. Individual informed consent was not requested, but patients were given an opportunity to opt out from participation (12 patients exercised this option). The population of the studied region is 320 000 but expands during summer due to tourism. The Region hosts two separate EDs that are open 24/7.
Independent variables
The selection of independent variables was conducted a priori and was based on published literature and directed acyclic graphs as agreed on by a committee of physicians, researchers and informaticians. Descriptive statistics for the independent variables are shown in table 1 and variable definitions are available in the online supplementary appendix. The unit of analysis is one ED visit. Complete-case analysis was deployed as the proportion missing values was low.
Supplemental material
Descriptive statistics
Statistical analysis
Six different algorithms were selected for model training, based on their principally different approaches to prediction. These were L2 regularised logistic regression (LR),20 support vector machine (SVM),21 K-nearest neighbours(KNN) classifier,22 boosted gradient trees (AB),23 random forests (RF)24 and neural network (MLP).25 All selected predictors were fed into each of the models. As prediction algorithms assume that training sets have reasonably evenly distributed classes of the outcome, skewed data sets pose risks of biasing the algorithm towards the majority class. To mitigate this, we oversampled the minority class in the development set26 for KNN to equal proportions. For the other algorithms, we used an embedded cost matrix in the model function that penalised misclassified samples from the minority more than from the majority27 (proportional to the inverse probability of belonging to the minority class). Despite acknowledging the ongoing debate on reporting standards for rare event classifiers, we chose to optimise models for area under the ROC (ROC–AUC) as it makes for a straightforward comparison to models published by others and is recommended by the authorities for evaluating diagnostic tests.28 Once the optimal set of hyperparameters was identified through systematic grid-search (using fivefold cross-validation to reduce variance), the performance of each model was evaluated on the validation set. Performance on the development and validation set was compared to assess whether models were overfit or underfit. The development set consisted of visits to one ED in the region and the validation set consisted of visits to another. 95% CIs were obtained by identifying the fifth and 95th percentiles of a probability distribution of each relevant measure, obtained by refitting the final models on bootstrapped samples of the validation set (drawn with replacement over 1000 iterations).29 For face-validity, the relative importance of each predictor was assessed using the internal estimates of variable importance inherent to the RF algorithm.24 Continuous variables were normalised before being fed into the models. Observations were designated predicted positive if the predicted probability of the outcome was ≥50%. Performance was reported as sensitivity and specificity in accordance with STARD30 and benchmarked across models by comparing 95% CIs. Univariate comparisons were conducted using the Wilcoxon rank sum test for continuous variables and the χ2 test for indicator variables. Multicollinearity was addressed using Spearman’s r. Statistical analyses were undertaken in Python 3.6, scikit-learn 20.031 and Keras.32 Data analysis was conducted by one author (AA) with supervision from MCB and ASA. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis reporting guidelines were used.33
Results
Descriptive statistics
The development set included 65 776 observations and the validation set 55 164 observations, after excluding 3035 observations with missing information for comorbidity score. Of note, 3385 observations lacked information on provider experience, but as these variables were constructed as indicators, missing values for the source variable were not excluded. See table 2 for a detailed description of the construction of the study cohort. Patients in the validation set were older than patients in the development set and more of them were referred to the ED and subject to radiology orders, while fewer of them were cared for by a junior provider (see table 1).
Exclusion analysis
ED census and night-time discharge, along with hospital bed occupancy and weekend discharge, displayed moderate correlations (coefficients −0.46 and −0.52) (see online supplementary figure S1). All models converged and did not indicate multicollinearity.
Model performance
All models performed excellently on the development set, ranging from ROC–AUC 0.92 (95% CI 0.91 to 0.94) for KNN to 1.00 (1.00 to 1.00) for AB. The substantial decrease in performance of MLP and AB on the validation set indicated overfitting to the development set. The decrease in performance of these two models was driven by sensitivity, that is, an inability to correctly identify cases, which is in line with expectations for imbalanced tasks (ie, the low prevalence of cases incited the models to predict both cases and non-cases as negative). However, ROC–AUC was excellent for the remaining models on the validation set (LR, SVM, RF and KNN), suggesting little or no overfitting to the development set (see table 3 and figure 1). Detailed information about algorithm training is provided in the online supplementary appendix. Final models, source code and instructions are made available on request.
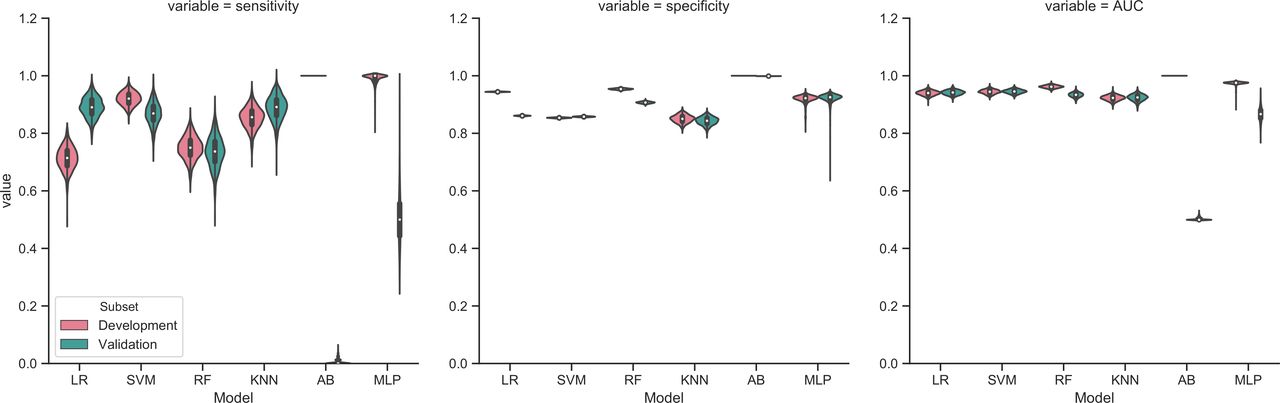
Algorithm performance (development and validation set). AB, boosted gradient trees; KNN, K-nearest neighbours; LR, logistic regression; MLP, neural network; RF, random forests; SVM, support vector machine.
Algorithm performance (development and validation set)
Patient age and comorbidity score displayed the highest relative importance among the independent variables, followed by arriving in the ED by ambulance (see figure 2). These findings are aligned with an expectation that older and comorbid patients are at increased risk of death as well as that arriving by ambulance may indicate a more serious condition. A posthoc sensitivity analysis that was undertaken on the final RF algorithm by retraining it on the top five features only (age, comorbidity score, arrival by ambulance, ED census and hospital bed occupancy, selected based on the mean decrease in Gini impurity) suggested only a small reduction in performance from limiting the number of features (ROC–AUC 0.937, 95% CI 0.922 to 0.949).

{kind=link}
{kind=link}
Variable importance using the RF algorithm. ED, emergency department; LAMA, leave against medical advice; RF, random forests.
Discussion
Four of the machine learning models predicted all-cause 30-day mortality with excellent discrimination on the validation set (ROC–AUC >0.900). This exceeds several previously reported models (by indirect comparison, as clinical data sets are not available), such as ROC–AUC 0.860 of a frequently cited algorithm for short-term mortality prediction proposed by Gagne et al 34 as well as ROC–AUC 0.930 of models aimed at identifying patients who may benefit from palliative care proposed by Avati et al 35 and an array of models trained on less heterogeneous patient subgroups that exhibit lower class imbalance (ie, higher baseline risk). A non-exhaustive sample of such models include the contributions made by Miro (ROC–AUC 0.836),36 Makar e t al (ROC–AUC 0.828)37 and Elfiky et al (ROC–AUC 0.940).38 Additionally, as the models proposed here are trained on data produced as a by-product of routine care delivery, we argue that our contributions are less resource intensive to implement in clinical practice than many traditional risk scores that require costly de novo data collection. Moreover, our models are distinguished by maintaining performance when validated on a distribution that they were unexposed to during training, which contrasts the common approach of validating on a random heterogeneous sample from the training distribution.35–39
Many clinicians recognise the challenges in hosting timely discussions about patients’ EOL preferences, which is reflected in findings suggesting that advance care planning often occurs too late or not at all. In turn, we believe this contributes to overtreatment and care that is not in line with patient preferences.2 40 41 We hope that our models can aid physicians who face such challenges to systematically identify patients at EOL to schedule for more timely planning, without significantly adding to their workload.
While screening healthy populations traditionally demands tests with high specificity, the desired level depends on the scheduled intervention. If the intervention scheduled for patients deemed high-risk by our models is a non-invasive follow-up visit to primary care, we argue that high sensitivity is more relevant than high specificity, as the direct physical risks to the patient are minimal. Depending on the cost of delivering the intervention, individual healthcare systems may want to fine-tune the prediction threshold to achieve a lower false-positive rate (and lower costs of the intervention) at the expense of sensitivity. At the discretion of the primary care physician, a follow-up visit could focus on advance care planning or on an overall evaluation, which likely adds value to the elderly patients with multiple comorbidities that constitute most of the high-risk patients. An evaluation in primary care could also benefit patients who are of high risk of death due to an acute condition that was not correctly identified in the ED. While the latter patient group is not the main focus of this work, the models can be retrained on a refined population to learn identify such erroneous discharges. Using follow-up in primary care as the intervention would also address the suggested benefits of involving primary care in advance care planning.41 It is already not uncommon to arrange follow-up in primary care after an ED visit, which makes us believe that scheduling patients with high predicted risk of death for such follow-up after ED discharge fits well within the general process of care. Moreover, an overall risk-assessment is already part of the emergency physician’s duties at discharge, which makes automated screening using our models fit well within the ED clinical workflow. While classic risk stratification tools developed in the past have been making use of linear equations that lend themselves well to translation into risk scores that can be retrieved from memory, the flexibility of machine learning models makes such use less straightforward. However, current methods for deploying predictive models in hospital information systems would allow models like these to be accessed through an application interface in healthcare workers’ clinical workflow, much like is the case with decision support systems or clinical systems used for placing for example, radiology orders.
While a case has been made in the past for targeting EOL care as a means of reducing overall healthcare spending, recent work has challenged the overall impact of such a strategy2 39 and we do not expect that implementing our models in clinical practice will prevent accelerating costs of care. Rather, we hope that the models can promote value in healthcare by bringing patients, physicians and families closer to meaningful EOL discussions. Additionally, the scarcity of evidence supporting EOL interventions42 poses a need for prospective trials, and the models may prove useful as a computable phenotype to identify study subjects for future research.
Strengths and limitations
One effect of the flexibility allowed by machine learning models is that they may overfit to the characteristics of the development set and therefore not perform similarly across sites.43 To mitigate this situation, we implemented cross-validation and validated model performance out of sample on data from a separate hospital, that the models were previously unexposed to. Also, the use of standard data-elements routinely captured in most EHR systems makes our models less susceptible to being overfit to the practices of a specific institution, as compared with models that make predictions from a wider array of data elements that tend to be more institution specific (eg, text in EHR notes that may reflect individual physicians’ documentation style or biases). As variations in local processes or populations are expected to occur over time, our models should be continuously monitored and periodically retrained to maintain performance when implemented in clinical practice. The inverse-probability weighting scheme maintained in this exercise makes it unlikely that algorithm performance is significantly impacted by retraining on data sets displaying different levels of class-imbalance.
Before deployment, we also suggest that the models are subject to prospective validation across several sites, and to a formal cost–benefit analysis in order to identify associated interventions that are safe, effective and add value. Further customisation of the models is achievable by optimising the decision threshold to produce the most favourable trade-off between false positives and false negatives in any given population, taking into account the characteristics of the intervention scheduled to follow algorithm predictions. Additionally, combining several models into an ensemble predictor for increased flexibility may improve performance further still.
Conclusions
In this paper, we report performance of supervised machine learning models that predict 30-day mortality in patients discharged from the ED with excellent discrimination. The models outperform other indexes previously developed for short-term mortality prediction in terms of ROC–AUC (by indirect comparison) without being dependent on costly de novo data collection, which makes them readily implementable in clinical practice.
Acknowledgments
We wish to acknowledge contributions made to this study by Thomas Wallenfeldt (CGI group Inc) and Ziad Obermeyer, MD. (Brigham and Women’s Hospital, Harvard Medical School).
References
Footnotes
Contributors MCB and ML came up with the study idea and drafted the first version of the study protocol. ASA, AA, ML and MCB developed the analysis plan. AA conducted all analyses for the paper with supervision from MCB and ASA. MCB, AA, ASA, PDA and ML provided critical input on the study protocol. MCB, AA, ASA, PDA and ML took part in interpreting preliminary results and drafting the manuscript.
Funding This work was partly funded by Region Halland, Sweden. The authors also wish to recognise the Health Technology Center (HCH) and Center for Applied Intelligent Systems Research (CAISR) at Halmstad University for support from the project HiCube - behovsmotiverad halsoinnovation.The initial stage of MCBs involvement in the work was funded by a grant for post-doctoral research from the Tegger Foundation. The funders/sponsors had no role in the design and conduct of the study; collection, management, analysis and interpretation of the data; preparation review, or approval of the manuscript and decision to submit the manuscript for publication.
Competing interests None declared.
Patient consent for publication This research was done without patient involvement. Patients were not invited to comment on the study design and were not consulted to develop patient relevant outcomes or interpret the results. Patients were not invited to contribute to the writing or editing of this document for readability or accuracy.
Provenance and peer review Not commissioned; externally peer reviewed.
Data availability statement Technical appendix, statistical code and final models available upon request. Individual-level patient data may not and therefore will not be shared.