Article Text

Abstract
Objective To empirically explore the level of agreement of the treatment hierarchies from different ranking metrics in network meta-analysis (NMA) and to investigate how network characteristics influence the agreement.
Design Empirical evaluation from re-analysis of NMA.
Data 232 networks of four or more interventions from randomised controlled trials, published between 1999 and 2015.
Methods We calculated treatment hierarchies from several ranking metrics: relative treatment effects, probability of producing the best value  and the surface under the cumulative ranking curve (SUCRA). We estimated the level of agreement between the treatment hierarchies using different measures: Kendall’s τ and Spearman’s ρ correlation; and the Yilmaz
and the surface under the cumulative ranking curve (SUCRA). We estimated the level of agreement between the treatment hierarchies using different measures: Kendall’s τ and Spearman’s ρ correlation; and the Yilmaz  and Average Overlap, to give more weight to the top of the rankings. Finally, we assessed how the amount of the information present in a network affects the agreement between treatment hierarchies, using the average variance, the relative range of variance and the total sample size over the number of interventions of a network.
and Average Overlap, to give more weight to the top of the rankings. Finally, we assessed how the amount of the information present in a network affects the agreement between treatment hierarchies, using the average variance, the relative range of variance and the total sample size over the number of interventions of a network.
Results Overall, the pairwise agreement was high for all treatment hierarchies obtained by the different ranking metrics. The highest agreement was observed between SUCRA and the relative treatment effect for both correlation and top-weighted measures whose medians were all equal to 1. The agreement between rankings decreased for networks with less precise estimates and the hierarchies obtained from  appeared to be the most sensitive to large differences in the variance estimates. However, such large differences were rare.
appeared to be the most sensitive to large differences in the variance estimates. However, such large differences were rare.
Conclusions Different ranking metrics address different treatment hierarchy problems, however they produced similar rankings in the published networks. Researchers reporting NMA results can use the ranking metric they prefer, unless there are imprecise estimates or large imbalances in the variance estimates. In this case treatment hierarchies based on both probabilistic and non-probabilistic ranking metrics should be presented.
- statistics & research methods
- epidemiology
- public health
This is an open access article distributed in accordance with the Creative Commons Attribution 4.0 Unported (CC BY 4.0) license, which permits others to copy, redistribute, remix, transform and build upon this work for any purpose, provided the original work is properly cited, a link to the licence is given, and indication of whether changes were made. See: https://creativecommons.org/licenses/by/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
To our knowledge, this is the first empirical study exploring the level of agreement of the treatment hierarchies from different ranking metrics in network meta-analysis (NMA).
The study also explores how agreement is influenced by network characteristics.
More than 200 published NMAs were re-analysed and three different ranking metrics calculated using both frequentist and Bayesian approaches.
Other potential factors not investigated in this study could influence the agreement between hierarchies.
Introduction
Network meta-analysis (NMA) is being increasingly used by policymakers and clinicians to answer one of the key questions in medical decision-making: ‘what treatment works best for the given condition?’.1 2 The relative treatment effects, estimated in NMA, can be used to produce ranking metrics: statistical quantities measuring the performance of an intervention on the studied outcomes, thus producing a treatment hierarchy from the most preferable to the least preferable option.3 4
Despite the importance of treatment hierarchies in evidence-based decision-making, various methodological issues related to the ranking metrics have been contested.5–7 This ongoing methodological debate focusses on the uncertainty and bias in a single ranking metric. Hierarchies produced by different ranking metrics are not expected to agree because ranking metrics differ. For example, a non-probabilistic ranking metric such as the treatment effect against a common comparator considers only the mean effect (eg, the point estimate of the odds ratio (OR)) and ignores the uncertainty with which this is estimated. In contrast, the probability that a treatment achieves a specific rank (a probabilistic ranking metric) considers the entire estimated distribution of each treatment effect. However, it is important to understand why and how rankings based on different metrics differ.
There are network characteristics that are expected to influence the agreement of treatment hierarchies from different ranking metrics, such as the precision of the included studies and their distribution across treatment comparisons.4 8 Larger imbalances in precision in the estimation of the treatment effects affects the agreement of the treatment hierarchies from probabilistic ranking metrics, but it is currently unknown whether in practice these imbalances occur and whether they should inform the choice between different ranking metrics. To our knowledge, no empirical studies have explored the level of agreement of treatment hierarchies obtained from different ranking metrics, or examined the network characteristics likely to influence the level of agreement. Here, we empirically evaluated the level of agreement between ranking metrics and examined how the agreement is affected by network features. The article first describes the methods for the calculation of ranking metrics and of specific measures to assess the agreement and to explore factors that affects it, respectively. Then, a network featuring one of the explored factors is shown as an illustrative example to display differences in treatment hierarchies from different ranking metrics. Finally, we present the results from the empirical evaluation and discuss their implications for researchers undertaking NMA.
Methods
Data
We re-analysed networks of randomised controlled trials from a database of articles published between 1999 and 2015, including at least four treatments; details about the search strategy and inclusion/exclusion criteria can be found in.9 10 We selected networks reporting arm-level data for binary or continuous outcomes. The database is accessible in the nmadb R package.11
Re-analysis and calculation of ranking metrics
All networks were re-analysed using the relative treatment effect that the original publication used: OR, risk ratio (RR), standardised mean difference (SMD) or mean difference (MD). We estimated relative effects between treatments using a frequentist random-effects NMA model using the netmeta R package.12 For the networks reporting ORs and SMDs we re-analysed them also using Bayesian models using self-programmed NMA routines in JAGS (https://github.com/esm-ispm-unibe-ch/NMAJags). To obtain probabilistic ranking metrics in a frequentist setting, we used parametric bootstrap by producing 1000 data sets from the estimated relative effects and their variance-covariance matrix. By averaging over the number of simulated relative effects we derived the probability of treatment i to produce the best value

where  is the estimated mean relative effect of treatment i against treatment j out of a set T of T competing treatments. We will refer to this as
is the estimated mean relative effect of treatment i against treatment j out of a set T of T competing treatments. We will refer to this as  . This ranking metric indicates how likely a treatment is to produce the largest values for an outcome (or smallest value, if the outcome is harmful). We also calculated the surface under the cumulative ranking curve (
. This ranking metric indicates how likely a treatment is to produce the largest values for an outcome (or smallest value, if the outcome is harmful). We also calculated the surface under the cumulative ranking curve ( )3
)3

where  are the cumulative probabilities that treatment i will produce an outcome that is among the r best values (or that it outperforms
are the cumulative probabilities that treatment i will produce an outcome that is among the r best values (or that it outperforms  treatments). SUCRA, unlike
treatments). SUCRA, unlike  , also considers the probability of a treatment to produce unfavourable outcome values. Therefore, the treatment with the largest SUCRA value represents the one that outperforms the competing treatments in the network, meaning that overall it produces preferable outcomes compared with the others. We also obtained SUCRAs within a Bayesian framework (
, also considers the probability of a treatment to produce unfavourable outcome values. Therefore, the treatment with the largest SUCRA value represents the one that outperforms the competing treatments in the network, meaning that overall it produces preferable outcomes compared with the others. We also obtained SUCRAs within a Bayesian framework ( ).
).
To obtain the non-probabilistic ranking metric we fitted an NMA model and estimated related treatment effects. To obtain estimates for all treatments we reparametrise the NMA model so that each treatment is compared with a fictional treatment of average performance.13 14 The estimated relative effects against a fictional treatment F of average efficacy  represent the ranking metric and the corresponding hierarchy is obtained simply by ordering the effects from the largest to the smallest (or in ascending order, if the outcome is harmful). The resulting hierarchy is identical to that obtained using relative effects from the conventional NMA model, irrespective of the reference treatment. In the rest of the manuscript, we will refer to this ranking metric simply as relative treatment effect.
represent the ranking metric and the corresponding hierarchy is obtained simply by ordering the effects from the largest to the smallest (or in ascending order, if the outcome is harmful). The resulting hierarchy is identical to that obtained using relative effects from the conventional NMA model, irrespective of the reference treatment. In the rest of the manuscript, we will refer to this ranking metric simply as relative treatment effect.
Agreement between ranking metrics
To estimate the level of agreement between the treatment hierarchies obtained using the three chosen ranking methods we employed several correlation and similarity measures.
To assess the correlation between ranking metrics we used Kendall’s τ15 and the Spearman’s ρ.16 Both Kendall’s τ and Spearman’s ρ give the same weight to each item in the ranking. In the context of treatment ranking, the top of the ranking is more important than the bottom. We therefore also used a top-weighted variant of Kendall’s τ, Yilmaz  ,17 which is based on a probabilistic interpretation of the average precision measure used in information retrieval18 (see online supplementary appendix).
,17 which is based on a probabilistic interpretation of the average precision measure used in information retrieval18 (see online supplementary appendix).
Supplemental material
The measures described so far can only be considered for conjoint rankings, that is, for lists where each item in one list is also present in the other list. Rankings are non-conjoint when a ranking is truncated to a certain depth k with such lists called top-k rankings. We calculated the Average Overlap,19 20 a top-weighted measure for top-k rankings that considers the cumulative intersection (or overlap) between the two lists and averages it over a specified depth (cut-off point) k (see online supplementary appendix for details). We calculated the Average Overlap between pairs of rankings for networks with at least six treatments (139 networks) for a depth k equal to half the number of treatments in the network,  (or
(or  if T is an odd number).
if T is an odd number).
We calculated the four measures described above to assess the pairwise agreement between the three ranking metrics within the frequentist setting and summarised them for each pair of ranking metrics and each agreement measure using the median and the first and third quartiles. The hierarchy according to  was compared with that of its frequentist equivalent to check how often the two disagree.
was compared with that of its frequentist equivalent to check how often the two disagree.
Influence of network features on the rankings agreement
The main network characteristic considered was the amount of information in the network (reflected in the precision of the estimates). Therefore, for each network we calculated the following measures of information:
The average variance, calculated as the mean of the variances of the estimated treatment effects
 , to show how much information is present in a network altogether;
, to show how much information is present in a network altogether;The relative range of variance, calculated as
, to describe differences in information about each intervention within the same networks;


The total sample size of a network over the number of interventions.
These measures are presented in scatter plots against the agreement measurements for pairs of ranking metrics.
All the codes for the empirical evaluation are available at https://github.com/esm-ispm-unibe-ch/rankingagreement
Patient and public involvement
Patients and the public were not involved in this study.
Illustrative example
To illustrate the impact of the amount of information on the treatment hierarchies from different ranking metrics, we used a network of nine antihypertensive treatments for primary prevention of cardiovascular disease that presents large differences in the precision of the estimates of overall mortality.21 The network graph and forest plot of relative treatment effects of each treatment versus placebo are presented in figure 1. The relative treatment effects reported are RR estimated using a random effects NMA model.

(Left panel) Network graph of network of nine antihypertensive treatments for primary prevention of cardiovascular disease. Line width is proportional to inverse standard error of random effects model comparing two treatments. (Right panel) Forest plots of relative treatment effects of overall mortality for each treatment versus placebo. ACE, Angiotensin Converting Enzyme; ARB, angiotensin receptor blockers; CCB, calcium channelblockers; RR, risk ratio.
Table 1 shows the treatment hierarchies obtained using the three ranking metrics described above. The highest overall agreement is between hierarchies from the  and the relative treatment effect as shown by both correlation (Spearman’s ρ = 0.93, Kendall’s τ = 0.87) and top-weighted measures (Yilmaz’s
and the relative treatment effect as shown by both correlation (Spearman’s ρ = 0.93, Kendall’s τ = 0.87) and top-weighted measures (Yilmaz’s  = 0.87; Average Overlap=0.85). The level of agreement decreases when
= 0.87; Average Overlap=0.85). The level of agreement decreases when  and the relative treatment effect are compared with
and the relative treatment effect are compared with  rankings (Spearman’s ρ = 0.63 and ρ = 0.85, respectively). Agreement with
rankings (Spearman’s ρ = 0.63 and ρ = 0.85, respectively). Agreement with  especially decreases when considering top ranks only (Average Overlap is 0.48 for
especially decreases when considering top ranks only (Average Overlap is 0.48 for  vs
vs  and 0.54 for
and 0.54 for  vs relative treatment effect). All agreement measures are presented in online supplementary table S1.
vs relative treatment effect). All agreement measures are presented in online supplementary table S1.
Example of treatment hierarchies from different ranking metrics for a network of nine antihypertensive treatment for primary prevention of cardiovascular disease
The reason for this disagreement is explained by the differences in precision in the estimated effects (figure 1). These RRs versus placebo range from 0.82 (diuretic/beta-blocker vs placebo) to 0.98 (beta-blocker vs placebo). All estimates are fairly precise except for the RR of conventional therapy versus placebo whose 95% confidence interval (CI) extends from 0.21 to 3.44. This uncertainty in the estimation is due to the fact that conventional therapy is compared only with angiotensin receptor blockers (ARB) via a single study. This large difference in the precision of the estimation of the treatment effects mostly affects the  ranking, which disagrees the most with both of the other rankings. Consequently, the conventional therapy is in the first rank in the
ranking, which disagrees the most with both of the other rankings. Consequently, the conventional therapy is in the first rank in the  hierarchy (because of the large uncertainty) but only features in the third/fourth and sixth rank using the relative treatment effects and
hierarchy (because of the large uncertainty) but only features in the third/fourth and sixth rank using the relative treatment effects and  hierarchies, respectively.
hierarchies, respectively.
To explore how the hierarchies for this network would change in case of increased precision, we reduced the standard error (SE) of the conventional versus ARB treatment effect from the original 0.7 to a fictional value of 0.01 resulting in a CI 0.77 to 0.96. The columns in the right-hand side of table 1 display the three equivalent rankings after the SE reduction. The conventional treatment has moved up in the hierarchy according to  and moved down in the one based on
and moved down in the one based on  , as expected. The treatment hierarchies obtained from the
, as expected. The treatment hierarchies obtained from the  and the relative treatment effect are now identical (conventional and ARB share the 3.5 rank because they have the same effect estimate) and the agreement with the
and the relative treatment effect are now identical (conventional and ARB share the 3.5 rank because they have the same effect estimate) and the agreement with the  rankings also improved (
rankings also improved ( vs
vs  Spearman’s ρ = 0.89, Average Overlap=0.85;
Spearman’s ρ = 0.89, Average Overlap=0.85;  vs relative treatment effect Spearman’s ρ = 0.91, Average Overlap=0.94; online supplementary table S1).
vs relative treatment effect Spearman’s ρ = 0.91, Average Overlap=0.94; online supplementary table S1).
Results
A total of 232 networks were included in our data set. Their characteristics are shown in table 2.
Characteristics of the 232 NMAs included in the re-analysis
The majority of networks (133 NMAs, 57.3%) did not report any ranking metrics in the original publication. Among those which used a ranking metric to produce a treatment hierarchy, the probability of being the best was the most popular metric followed by the SUCRA with 35.8% and 6.9% of networks reporting them, respectively.
Table 3 presents the medians and quartiles for each similarity measures. All hierarchies showed a high level of pairwise agreement, although the hierarchies obtained from the  and the relative treatment effect presented the highest values for both unweighted and with top-weighted measures (all measures’ median equals 1). Only four networks (less than 2%) had a Spearman’s correlation between
and the relative treatment effect presented the highest values for both unweighted and with top-weighted measures (all measures’ median equals 1). Only four networks (less than 2%) had a Spearman’s correlation between  and the relative treatment effect less than 90% (not reported). The correlation becomes less between the
and the relative treatment effect less than 90% (not reported). The correlation becomes less between the  rankings and those obtained from the other two ranking metrics with Spearman’s ρ median decreasing to 0.9 and Kendall’s τ decreasing to 0.8. The Spearman’s correlation between these rankings was less than 90% in about 50% of the networks (in 116 and 111 networks for
rankings and those obtained from the other two ranking metrics with Spearman’s ρ median decreasing to 0.9 and Kendall’s τ decreasing to 0.8. The Spearman’s correlation between these rankings was less than 90% in about 50% of the networks (in 116 and 111 networks for  vs
vs  and
and  vs relative effect, respectively; results not reported). The pairwise agreement between the
vs relative effect, respectively; results not reported). The pairwise agreement between the  rankings and the other rankings also decreased when considering only top ranks (
rankings and the other rankings also decreased when considering only top ranks ( vs
vs  Yilmaz’s
Yilmaz’s  = 0.77, Average Overlap=0.83;
= 0.77, Average Overlap=0.83;  vs relative treatment effect Yilmaz’s
vs relative treatment effect Yilmaz’s  = 0.79, Average Overlap=0.88).
= 0.79, Average Overlap=0.88).
Pairwise agreement between treatment hierarchies obtained from the different ranking metrics measured by Spearman ρ, Kendall τ, Yilmaz  and Average Overlap
and Average Overlap
The SUCRAs from frequentist and Bayesian settings ( and
and  ) were compared in 126 networks (82 networks using the Average Overlap measure) as these reported OR and SMD as original measures. The relevant rankings do not differ much as shown by the median values of the agreement measures all equal to 1 and their narrow interquartile ranges (IQRs) (table 3). Nevertheless, a few networks showed a much lower agreement between the two SUCRAs. These networks provide posterior effect estimates for which the normal approximation is not optimal, some of which due to rare outcomes. Such cases were however uncommon as in only 6% of the networks the Spearman’s correlation between and was less than 90%. Plots for the normal distributions from the frequentist setting and the posterior distributions of the log ORs for a network with a Spearman’s of 0.6 between the two SUCRAs is available in online supplementary figure S1.22
) were compared in 126 networks (82 networks using the Average Overlap measure) as these reported OR and SMD as original measures. The relevant rankings do not differ much as shown by the median values of the agreement measures all equal to 1 and their narrow interquartile ranges (IQRs) (table 3). Nevertheless, a few networks showed a much lower agreement between the two SUCRAs. These networks provide posterior effect estimates for which the normal approximation is not optimal, some of which due to rare outcomes. Such cases were however uncommon as in only 6% of the networks the Spearman’s correlation between and was less than 90%. Plots for the normal distributions from the frequentist setting and the posterior distributions of the log ORs for a network with a Spearman’s of 0.6 between the two SUCRAs is available in online supplementary figure S1.22
Figure 2 presents how Spearman’s ρ and the Average Overlap vary with the average variance of the relative treatment effect estimates in a network (scatter plots for the Kendall’s τ and the Yilmaz’s  are available in online supplementary figure S2). The treatment hierarchies agree more in networks with more precise estimates (left hand side of the plots).
are available in online supplementary figure S2). The treatment hierarchies agree more in networks with more precise estimates (left hand side of the plots).
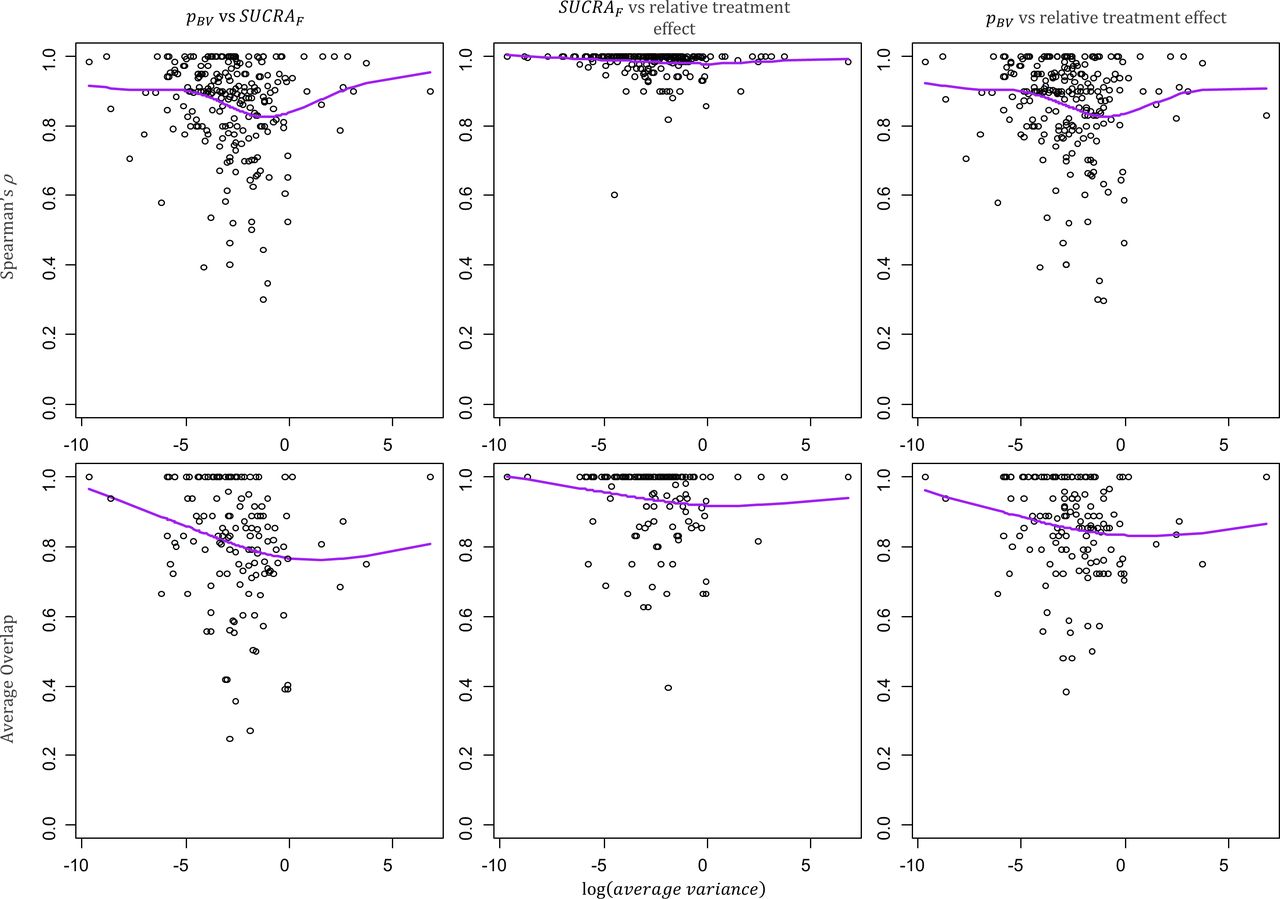
Scatter plots of the average variance in a network and the pairwise agreement between hierarchies from different ranking metrics. The average variance is calculated as the mean of the variances of the estimated treatment effects and describes the average information present in a network. More imprecise network are on the right-hand side of the plots. Spearman ρ (top row) and Average Overlap (bottom row) values for the pairwise agreement between  and SUCRAF (first column), SUCRAF and relative treatment effect (second column),
and SUCRAF (first column), SUCRAF and relative treatment effect (second column), and relative treatment effect (third column). Purple line: cubic smoothing spline with five degrees of freedom. p
BV, probability of producing the best value; SUCRAF, surface under the cumulative ranking curve (calculated in frequentist setting).
and relative treatment effect (third column). Purple line: cubic smoothing spline with five degrees of freedom. p
BV, probability of producing the best value; SUCRAF, surface under the cumulative ranking curve (calculated in frequentist setting).
The association between Spearman’s ρ or Average Overlap and the relative range of variance in a network (here transformed to a double logarithm of the inverse values) are displayed in figure 3. On the right-hand side of each plot we can find networks with smaller differences in the precision of the treatment effect estimates. Treatment hierarchies for these networks show a larger agreement than for those with larger differences in precision. The plots of the impact of the relative range of variance on all measures are available in online supplementary figure S3.

{kind=link}
{kind=link}
{kind=link}
Scatter plots of the relative range of variance in a network and the pairwise agreement between hierarchies from different ranking metrics. The relative range of variance, calculated as  , indicates how much the information differs between interventions in the same networks. Networks with larger differences in variance are on the left-hand side of the plots. Spearman ρ (top row) and Average Overlap (bottom row) values for the pairwise agreement between
, indicates how much the information differs between interventions in the same networks. Networks with larger differences in variance are on the left-hand side of the plots. Spearman ρ (top row) and Average Overlap (bottom row) values for the pairwise agreement between  and SUCRAF (first column), SUCRAF and relative treatment effect (second column),
and SUCRAF (first column), SUCRAF and relative treatment effect (second column),  and relative treatment effect (third column). Purple line: cubic smoothing spline with five degrees of freedom. pBV, probability of producing the best value; ; SUCRAF, surface under the cumulative ranking curve (calculated in frequentist setting).
and relative treatment effect (third column). Purple line: cubic smoothing spline with five degrees of freedom. pBV, probability of producing the best value; ; SUCRAF, surface under the cumulative ranking curve (calculated in frequentist setting).
The total sample size in a network over the number of interventions has a similar impact on the level of agreement between hierarchies. This confirms that the agreement between hierarchies increases for networks with a large total sample size compared with the number of treatments and, more generally, it increases with the amount of information present in a network (online supplementary figure S4).
Discussion
Our empirical evaluation showed that in practice the level of agreement between treatment hierarchies is overall high for all ranking metrics used. The agreement between treatment hierarchies from  and relative treatment effect was very often perfect. The agreement between the rankings from
and relative treatment effect was very often perfect. The agreement between the rankings from  or relative treatment effect and the ranking from
or relative treatment effect and the ranking from  was good but decreased when the top-ranked interventions are of interest. The agreement is higher for networks with precise estimates and small imbalances in precision.
was good but decreased when the top-ranked interventions are of interest. The agreement is higher for networks with precise estimates and small imbalances in precision.
Simulation studies6 23 using theoretical examples have shown the importance of accounting for the precision in the estimation of the treatment effects when a hierarchy is to be obtained. However, we show that cases of extreme imbalance in the precision of the treatment effects are rather uncommon.
Several factors can be responsible for imprecision in the estimation of the relative treatment effects in a network:
Large sampling error, determined by a small sample size, small number of events or a large standard deviation;
Poor connectivity of the network, when only a few links and few closed loops of evidence connect the treatments;
Residual inconsistency;
Heterogeneity in the relative treatment effects.
Random-effects models tend to provide relative treatment effects with similar precision as heterogeneity increases. In contrast, in the absence of heterogeneity when fixed-effects models are used, the precision of the effects can vary a lot according to the amount of data available for each intervention. In the latter case, the ranking metrics are likely to disagree. Also, the role of precision in ranking disagreement is more pronounced in cases where the interventions have similar effects.
Our results also confirm that a treatment hierarchy can differ when the uncertainty in the estimation is incorporated into the ranking metric (by using, for example, a probabilistic metric rather than ranking the point estimate of the mean treatment effect)8 24 and that rankings from the  seem to be the most sensitive to differences in precision in the estimation of treatment effects. We showed graphically that the agreement is less in networks with more uncertainty and with larger imbalances in the variance estimates. However, we also found that such large imbalances do not occur frequently in real data and in the majority of cases the different treatment hierarchies have a relatively high agreement.
seem to be the most sensitive to differences in precision in the estimation of treatment effects. We showed graphically that the agreement is less in networks with more uncertainty and with larger imbalances in the variance estimates. However, we also found that such large imbalances do not occur frequently in real data and in the majority of cases the different treatment hierarchies have a relatively high agreement.
We acknowledge that there could be other factors influencing the agreement between hierarchies that we did not explore, such as the chosen effect measures.25 However, we think it is unlikely that such features play a big role in ranking agreement unless assumptions are violated or data in the network is sparse.26 Adjustment via network meta-regression (for example, for risk of bias or small-study effects) might impact on the ranking of treatments not only by changing the point estimate but also by altering the total precision and the imbalance in the precision of the estimated treatment effects. We did not investigate the agreement between treatment hierarchies obtained from such adjusted analyses. We also did not explore non-methodological characteristics for networks with larger disagreement but we believe these characteristics are a proxy for the amount of information in a network, which is the main factor affecting the agreement between ranking metrics. For example, in some specific fields there are few or small randomised trials (eg, surgery) and, as a consequence, the resulting networks will have less information. Also, smaller (hence more imprecise) networks might be published more often in journal with lower impact factor and get less citations than large and precise networks.
To our knowledge, this is the first empirical study assessing the level of agreement between treatment hierarchies from ranking metrics in NMA and it provides further insights into the properties of the different methods. In this context, it is important to stress that neither the objective nor the findings of this empirical evaluation imply that a hierarchy for a particular metric works better or is more accurate than one obtained from another ranking metric. The reason why this sort of comparison cannot be made is that each ranking metric address a specific treatment hierarchy problem. For example, the  ranking addresses the issue of which treatment outperforms most of the competing interventions, while the ranking based on the relative treatment effect gives an answer to the problem of which treatment is associated with the largest average effect for the outcome considered.
ranking addresses the issue of which treatment outperforms most of the competing interventions, while the ranking based on the relative treatment effect gives an answer to the problem of which treatment is associated with the largest average effect for the outcome considered.
Our study shows that, despite theoretical differences between ranking metrics and some extreme examples, they produce very similar treatment hierarchies in published networks. In networks with large amount of data for each treatment, hierarchies based on SUCRA or the relative treatment effect will almost always agree. Large imbalances in the precision of the treatment effect estimates do not occur often enough to motivate a choice between the different ranking metrics. Therefore, our advice to researchers presenting results from NMA is the following: if the NMA estimated effects are precise, to use the ranking metric they prefer; if at least one NMA estimated effect is imprecise, to refrain from making bold statements about treatment hierarchy and present hierarchies from both probabilistic (eg, SUCRA or rank probabilities) and non-probabilistic metrics (eg, relative treatments effects).
References
Footnotes
Twitter @VirgieGinny, @eggersnsf, @Geointheworld
Contributors VC designed the study, analysed the data, interpreted the results of the empirical evaluation and drafted the manuscript. GS designed the study, interpreted the results of the empirical evaluation and revised the manuscript. AN provided input into the study design and the data analysis, interpreted the results of the empirical evaluation and revised the manuscript. TP developed and manages the database where networks’ data was accessed, provided input into the data analysis and revised the manuscript. ME provided input into the study design and revised the manuscript. All the authors approved the final version of the submitted manuscript.
Funding This work was supported by the Swiss National Science Foundation grant/award number 179158.
Competing interests None declared.
Patient consent for publication Not required.
Provenance and peer review Not commissioned; externally peer reviewed.
Data availability statement Data are available in a public, open access repository. The data for the network meta-analyses included in this study are available in the database accessible using the nmadb R package.