Article Text

Abstract
Introduction The choice of a basal insulin regimen to manage type 1 diabetes mellitus (T1DM) may have different risks of adverse events and effectiveness, due to the difference in the effectiveness of these agents across patient characteristics (eg, baseline glycosylated haemoglobin; A1C). Currently, there is a lack of high quality evidence to support the tailoring of insulin regimens according to an individual's needs. The aim of this study is to update our previous systematic review and perform an individual patient data network meta-analysis (IPD-NMA) to evaluate the comparative safety and effectiveness of long-acting versus intermediate-acting insulin in different subgroups of patients with T1DM.
Methods and analysis We will update our previous literature search from January 2013 onwards searching relevant electronic databases (eg, MEDLINE), as well as perform grey literature search through relevant society/association websites, and conference abstracts, and scan reference lists of the eligible studies. We will include randomised clinical trials of any duration examining long-acting versus intermediate-acting insulin preparations for adult patients with T1DM. We will focus on A1C and severe hypoglycaemia outcomes. For each pairwise treatment comparison, we will combine all IPD from all studies in a single multilevel model, where each study is a different cluster. For a connected network of trials, we will perform an IPD-NMA to identify potential effect modifiers, and estimate the most effective and safe treatments for patients with different characteristics. If we are not successful in obtaining IPD for at least one study, we will include aggregated data (AD) abstracted from the included RCTs in our analysis, combining IPD and AD into a single model. We will report our results using the PRISMA-IPD statement.
Ethics and dissemination The results of this systematic review and IPD-NMA will be of interest to stakeholders and will help in improving existing guideline recommendations.
PROSPERO registry number CRD42015023511.
- multiple treatments meta-analysis
- individual participant data
- insulin
- glycosylated hemoglobin
- hypoglycemia
This is an Open Access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/
Statistics from Altmetric.com
- multiple treatments meta-analysis
- individual participant data
- insulin
- glycosylated hemoglobin
- hypoglycemia
Strengths and limitations of this study
To the best of our knowledge, this study will be the first network meta-analysis using individual patient data evaluating the safety and effectiveness of long-acting versus intermediate-acting insulin in different subgroups of patients with type 1 diabetes mellitus (T1DM).
Our findings will directly inform clinical practice guidelines in the development of tailored management recommendations for patients with T1DM and facilitate individualised insulin treatment regimens for patients with T1DM.
A challenge of our study is that our data set relies on the authors’ willingness to share the data and their prompt response, but we will surmount this by using validated methods for author contact, including providing a cash incentive.
Although observational studies may provide data on safety, we will restrict to randomised clinical trials because this study design provides the highest quality of evidence for safety and effectiveness.
Introduction
A basal insulin regimen is required in the management of type 1 diabetes mellitus (T1DM) and this may include long-acting (glargine and detemir) and intermediate-acting (neutral protamine Hagedorn (NPH), and lente) insulin.1 Long-acting insulin has a longer duration of action than intermediate-acting insulin and potentially less intraindividual variability that may improve clinical outcomes. These choices may have different risks of adverse events and effectiveness. To help patients and clinicians optimally select between long-insulin and intermediate-insulin, knowledge regarding how the effectiveness of these agents differs across patient characteristics (eg, baseline glycosylated hemoglobin (A1C), risk of hypoglycaemia) is required. International expert committees, including the American and Canadian Diabetes Association, and the European Association for the Study of Diabetes, recommend that insulin regimens are tailored to the individual's treatment goals, lifestyle, diet, age, general health, motivation, hypoglycaemia awareness status and ability for self-management.1–4 For example, in patients with good glycemic control, the long-acting analogues result in less nocturnal hypoglycaemia compared with NPH insulin.5 ,6 Currently, there is a lack of high quality evidence to support the tailoring of insulin regimens according to an individual's characteristics or other treatment effect modifiers. As such, it is imperative to improve existing guideline recommendations and inform decision-makers about the safety and effectiveness of these interventions.
To address this gap and inform clinical practice guidelines, a systematic review and individual patient data (IPD) network meta-analysis (NMA) would the most trustworthy approach to perform. NMA allows the simultaneous analysis of randomised clinical trials (RCTs) involving different treatments. NMA provides the ability to get more precise estimates, draw inferences for the comparability between interventions that have never been compared in a RCT, and rank the interventions according to the probability for each treatment of being the best for each outcome.7–9 The validity of NMA results depends on the similarity of the RCT populations across treatment comparisons7 ,10 ,11 with respect to potential treatment effect modifiers,12 for example, A1C, risk of hypoglycemia, and age in the case of patients with T1DM. When a treatment effect modifier is a patient characteristic, IPD-NMA is the optimal approach, whereby data from each patient enrolled in each included trial are analysed. IPD-NMA is optimal because a relationship at the study level is not necessarily true at the individual patient level. For example, patients with a longer duration of T1DM are better able to control their A1C.13 Hence, older patients might be more likely to have better A1C control. Most NMAs use aggregated data (AD) (ie, summary point estimates from patients enrolled in each included trial) and thus information on important patient-level effect modifiers is not available.
There are two published NMAs for managing T1DM with insulin, including one conducted by our team.14 ,15 However, neither of these NMAs assessed the impact of different insulin regiments on individual patient characteristics (eg, baseline A1C levels ≤8.5% vs >8.5%, males vs females), because they used AD instead of IPD. Therefore, evidence cannot be tailored to these patient characteristics. This is particularly important because international expert committees, including the American and Canadian Diabetes Association, and the European Association for the Study of Diabetes, recommend tailoring treatment for patients with T1DM. The use of IPD in NMA can address this question providing the most reliable and least biased results.1–3
The aim of this study is to evaluate the comparative safety and effectiveness of long-acting insulin analogues (detemir/glargine) versus intermediate-acting (NPH and lente) and long-acting insulin in different subgroups of patients with T1DM. We will perform an IPD-NMA to identify potential treatment effect modifiers, and estimate the most effective and safe treatments for patients with different characteristics. Even if we obtain IPD from just one RCT, this will help us improve our understanding and possibly increase precision in results.16 This research will inform decision-making, as the IPD-NMA results will provide contextualised evidence to policymakers, guideline developers, healthcare providers and patients. Our outputs will include individualised treatment for patients with T1DM who are using these types of insulin, and will enhance the clinical practice guidelines providing tailored management recommendations for patients with T1DM.
Methods and analysis
This protocol has been registered with the PROSPERO database (CRD42015023511) and has been constructed according to the preferred reporting items for systematic reviews and meta-analyses protocols (PRISMA-P) guidelines.17
Eligibility criteria
We will update our previous systematic review,15 and we will use similar population, interventions, comparators, study designs and time period (PICOST) criteria. Eligible studies will be RCTs including adults with T1DM who were administered long-acting insulin compared to long-acting or intermediate-acting insulin. Premixed long-acting with intermediate-acting insulin preparations will be excluded. The specific PICOST are:
Population: adults (aged ≥18 years) with T1DM of any duration.
Interventions: long-acting insulin analogue preparations.
Comparators: long-acting or intermediate-acting insulin.
Outcomes: we will focus on two outcomes for which NMA was possible in our previous review:15 A1C and severe hypoglycaemia. The A1C reflects the average blood glucose levels of a patient over the past 3 months, and is reported as a percentage or millimoles (mmol/mol) (continuous variable).18 Severe hypoglycaemia is defined as a medical emergency in which patients need assistance to rapidly ingest sugar or receive an injection of glucose and is a dichotomous (yes/no) variable.
Study design: We will include RCTs. Quasi-RCTs, where allocation has been conducted using non-random methods (eg, date of birth and consecutive allocation), will be excluded. We will restrict our review to RCTs because this study design provides the highest quality of evidence for safety and effectiveness.18 Observational studies may provide data on safety, but these studies typically rely on administrative data and obtaining sufficient information on individual patients is challenging. Our systematic review15 showed that there are many RCTs available, and since the objective of this study is to improve the implementation of the clinical practice guideline that provides recommendations on how to target the intervention appropriately, we will only include RCTs.
Time: studies of any duration.
Other: we will include published and unpublished studies from any time point.
Search and study selection
We will update our literature search from January 2013 onwards using the terms from our previous review.15 We will search MEDLINE, Cochrane Central Register of Controlled Trials, and Embase, trial registry websites. We will also perform a grey literature search through relevant society/association websites and conference abstracts, and we will scan reference lists of included studies and relevant reviews. We will use the Synthesi.SR tool19 to screen citations and full-text articles. To ensure reliability, we will conduct a pilot-test before screening titles and abstracts using our eligibility criteria. This will entail screening a random sample of 50 citations by the entire team. When high agreement (>90%) is observed, pairs of team members will screen each title and abstract for inclusion, independently (level 1). After pilot-testing, the same reviewers will screen the full text of potentially relevant articles to determine inclusion (level 2) independently. Conflicts will be resolved by team discussion. Study selection will be reported using the PRISMA flow diagram.20 We will report the number of pilot-tests required at level 1 and level 2 screening, as well as the per cent agreement reached prior to embarking on full screening. We will provide reasons for study exclusion at level 1 and level 2 screening.
Data abstraction
Data collection from eligible papers will include study characteristics (eg, year of publication), aggregated patient characteristics (eg, type and number of patients), and outcome-level characteristics (eg, A1C). We will abstract the corresponding author's information (including mail and email addresses, and phone number), as well the funding source, which will be categorised as: (1) industry-sponsored trials (funded by or authored by an employee of a pharmaceutical or other commercial organisation), (2) publicly-sponsored trials (governmental sources and non-profit organisations, including universities, hospitals and foundations), (3) non-sponsored trials (no funding source), (4) unclear funding (eg, unclear how funding is categorised), and (5) funding not reported.21 Prior to embarking on data abstraction, we will conduct a pilot-test using a random sample of five included RCTs. When a high percent agreement has been reached (eg, >90%), full data abstraction will occur by two reviewers, independently.
We will search authors’ online research profiles (eg, Google Scholar) or publications via PubMed if their contact information is missing. To increase response rates, we will provide authors with a $100 cash incentive and we will use recommended approaches for increasing electronic surveys response rates,22 as follows: (1) in week 1, we will send an email to the corresponding author explaining the study purpose and requesting their data; (2) we will send reminder emails at the 3rd, 7th, 11th, and 15th weeks; (3) in week 7, we will send a reminder by post in addition to email; and (4) in week 15, we will contact the corresponding author by phone.
The data we aim to include in the analyses correspond to the data that the primary study authors used in their RCTs that were included in our previous NMA. In particular, we will ask authors to provide anonymous IPD on: (A) patients, including age, sex, pregnancy, baseline A1C level, presence of comorbid conditions, history of hypoglycaemia, other medications used for each participant, drop-outs along with reasons for drop-out and number of participants, (B) interventions, including treatment participant allocated, and dosage, (C) outcomes, including event and date of event and time taken to achieve severe hypoglycaemia, and A1C values and measurement dates, (D) study characteristics, such as date and method of randomisation. All IPD will be saved on a secure server, adhering to the personal health information protection act.
The process we will follow so as to be able to synthesise the trial IPD is depicted in figure 1.

Process followed for the conduction of the individual patient data network meta-analysis. AD, aggregated data; NMA, network meta-analysis; NPD, individual patient data.
Risk of bias and quality appraisal
We will appraise the risk of bias using the Cochrane Risk of Bias tool.18 After a pilot-test on a random sample of five RCTs, two review authors will independently assess the risk of bias in each included study, and any disagreements will be resolved by discussion with a third review author. As recommended by the PRISMA-IPD guidelines,23 we will check whether the randomisation of patients is adequate (ie, intervention and comparison groups are balanced for important patient characteristics), by comparing the number and type of patients in each arm, as well data consistency by comparing the IPD obtained from the authors with the AD from the publication.
For outcomes reported in ≥10 studies, we will draw a comparison-adjusted funnel plot.24 To account for each study estimating the relative effect of different treatments, we will order treatments chronologically and define all comparisons as newer treatment versus older treatment. We will plot the difference between each observed effect and the overall treatment effect of the same treatment comparison against the SE of the observed effect. If funnel plot asymmetry is observed, we will examine reasons for its prevalence (eg, selective reporting, publication bias, heterogeneity and inconsistency). To evaluate the quality of evidence in each NMA, two review authors will independently use the GRADE approach extended to network meta-analysis.25 ,26
Synthesis
We will describe the study and patient characteristics, as well as the risk of bias results using tables and figures. We will report our results using the PRISMA-IPD statement.23
For each pairwise comparison, we will combine all IPD from all studies in a single multilevel model, where each study is a different cluster. We will use the OR effect measure for severe hypoglycaemia27 and the mean difference (MD) effect measure for A1C levels.28 We anticipate there will be clinical and methodological heterogeneity between studies and thus we will use a random-effects model to incorporate the assumption that different studies are estimating different treatment effects. If IPD are not available for all trials, then a two-part model will be used; the first part will be exactly as described above, and the second part will be a one-stage pairwise meta-analysis to model AD.29 Both parts will share the same amount of between-study variance. We will account for treatment-by-covariate interactions, including patient characteristics (eg, age) in the model.29
For a connected network of trials (eg, figure 2), we will apply a random-effects NMA model assuming common within-network between-study variance across comparisons. If possible, we will combine information across a network of trials using only IPD. If we are not successful in obtaining IPD for at least one study, we will include the AD in our analysis that was abstracted from the included RCTs, and we will combine IPD and AD in a single model to allow all trials to contribute to the network treatment effect estimates.16 ,30 ,31 We will consider the patient-level covariates that are received from the authors (as described in the Data abstraction section) as potential treatment effect modifiers. We will statistically evaluate whether the analysis of the network evidence is valid at the AD-level using the design-by-treatment interaction model,32 ,33 and if global inconsistency is suggested, then we will use the loop-specific method34 ,35 to identify local inconsistency. We will explore substantial inconsistency and/or heterogeneity using IPD-NMA meta-regression approaches, with the treatment effect modifiers described in the ‘Data abstraction’ section as covariates.

{kind=link}
{kind=link}
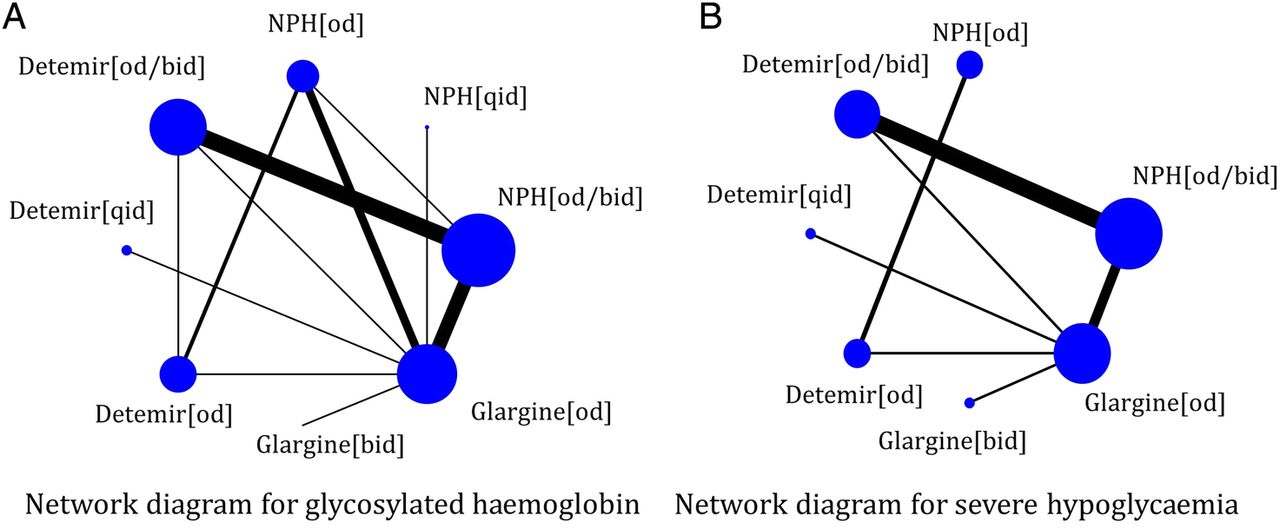
Network diagrams for (A) glycosylated haemoglobin (A1C) and (B) severe hypoglycaemia outcomes, as published in our previous systematic review and network meta-analysis;15 bid: twice daily; od: once daily; NPH: neutral protamine Hagedorn; qid: four times daily.
For the IPD-NMA, we will apply three model specifications using three different assumptions regarding the treatment-by-covariate interactions: (A) independent (ie, regression coefficients are different and unrelated across comparisons), (B) exchangeable (ie, regression coefficients are different but related, sharing the same distribution), and (C) common (ie, identical regression coefficients across comparisons).30 ,31 We will compare the results of the models by evaluating the statistical significance of the regression coefficients for interactions, monitoring the reduction in between-study variance, and using the deviance information criterion (DIC)36 to compare the overall fit and parsimony of the models. A difference of ≥3 units in DIC is considered important and the lowest value of DIC corresponds to the best fitting model.36 We will rank the interventions under the consistency assumption for each outcome using the surface under the cumulative ranking (SUCRA) curve.37
Our IPD analyses will be based on the intention-to-treat principle including all previously excluded patients. To evaluate the robustness of our results, we will conduct multiple sensitivity analyses, as follows: (1) restricting to studies of at least 12 weeks duration, as studies with shorter disease duration may do not provide relevant information on A1C, (2) restricting only to studies with IPD, (3) using different between-study variance priors,38–40 (4) restricting to studies with low risk of bias for allocation sequence generation, allocation concealment, and blinding and (5) using different imputation techniques. For A1C, missing outcome data will be handled by: (A) last observation carried forward, and (B) baseline observation carried forward,41 ,42 whereas for severe hypoglycaemia by: (A) imputed case analysis (ICA) best case scenario, where all missing participants in the treatment group are assumed non-events and all missing participants in the control group are considered events, and (B) ICA worst case scenario, where all missing participants in the treatment group are assumed events and all missing participants in the control group are considered non-events.43 ,44
We will perform all analyses within OpenBUGS.45 We will check convergence evaluating the mixing of two chains, after discarding the first 10 000 iterations. We will use vague priors for all model parameters apart from the between-study variance that we will use the informative priors suggested by Turner et al39 for dichotomous data and Rhodes et al40 for continuous data. The summary treatment effects will be presented using OR/MD with their corresponding credible intervals and predictive intervals, to facilitate the interpretation of results in light of the observed heterogeneity.46
Ethics and dissemination
In this study, we will evaluate the comparative safety and effectiveness of long-acting insulin versus intermediate-acting insulin for patients with T1DM. Our previous NMA15 suggested that long-acting insulin is statistically significantly superior to intermediate-acting insulin for glycaemic control and severe hypoglycaemia. Although this NMA provided important results, we were unable to make recommendations about tailoring the insulin to specific patients presenting with T1DM.
The results of this systematic review and IPD-NMA will be of interest to stakeholders, such as the American and Canadian Diabetes Association, and the European Association for the Study of Diabetes. The dissemination of our findings will be tailored to the needs of knowledge users. We will publish the results in an open-access journal and present them at relevant meetings. Team members will also use their networks to facilitate dissemination.
A challenge of our study is that our data set relies on the authors’ willingness to share the data and their prompt response.47 However, we have experience in contacting authors, as this is a regular process to ask for additional data on the eligible studies to enhance clarity, and on average we have a good response rate (>60%). Even if we obtain a handful of studies, this will help us achieve our aims, as it has been suggested that combining IPD with AD minimises the chances of confounding bias compared with AD-NMA.16 ,48
The IPD-NMA does not require ethical approval as it is not primary research and synthesises data from clinical trials, where informed consent has already been obtained from the patients by the trial investigators. We will request authors to share with us anonymous IPD of the RCTs that we included in our systematic review, where each patient will be linked to a specific identifier to prevent the patient's identity from being shared.
Acknowledgments
The authors thank Caitlyn Daly for providing some feedback on our protocol, as well Glenn McAuley and Dr Robert Peterson for their support on this study as knowledge users. The authors also thank Jaimie Ann Adams for formatting the current manuscript.
References
Footnotes
Contributors AAV, SES and ACT conceived and designed the study, and helped write the draft protocol. HMA registered the protocol with the PROSPERO database and edited the draft protocol. JSH and CY provided input into the design and draft of the protocol. All authors read and approved the final protocol.
Funding AAV is funded by the Canadian Institutes for Health Research (CIHR) Banting Postdoctoral Fellowship Program. SES is funded by a Tier 1 Canada Research Chair in Knowledge Translation. ACT is funded by a CIHR—Drug Safety and Effectiveness Network New Investigator Award in Knowledge Synthesis. This systematic review and individual patient data network meta-analysis was funded by the Knowledge Synthesis CIHR (grant number 351143).
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Data sharing statement Our study will be an update of our previous systematic review and we will contact the original authors to obtain anonymous individual patient data for our network meta-analysis. We plan to cite all relevant studies identified in our final publication, and provide a table with the summary results for each study.