Article Text

Abstract
Objective To assess predictive performance of universal early warning scores (EWS) in disease subgroups and clinical settings.
Design Systematic review.
Data sources Medline, CINAHL, Embase and Cochrane database of systematic reviews from 1997 to 2019.
Inclusion criteria Randomised trials and observational studies of internal or external validation of EWS to predict deterioration (mortality, intensive care unit (ICU) transfer and cardiac arrest) in disease subgroups or clinical settings.
Results We identified 770 studies, of which 103 were included. Study designs and methods were inconsistent, with significant risk of bias (high: n=16 and unclear: n=64 and low risk: n=28). There were only two randomised trials. There was a high degree of heterogeneity in all subgroups and in national early warning score (I2=72%–99%). Predictive accuracy (mean area under the curve; 95% CI) was highest in medical (0.74; 0.74 to 0.75) and surgical (0.77; 0.75 to 0.80) settings and respiratory diseases (0.77; 0.75 to 0.80). Few studies evaluated EWS in specific diseases, for example, cardiology (n=1) and respiratory (n=7). Mortality and ICU transfer were most frequently studied outcomes, and cardiac arrest was least examined (n=8). Integration with electronic health records was uncommon (n=9).
Conclusion Methodology and quality of validation studies of EWS are insufficient to recommend their use in all diseases and all clinical settings despite good performance of EWS in some subgroups. There is urgent need for consistency in methods and study design, following consensus guidelines for predictive risk scores. Further research should consider specific diseases and settings, using electronic health record data, prior to large-scale implementation.
PROSPERO registration number PROSPERO CRD42019143141.
- adult intensive & critical care
- risk management
- clinical governance
- epidemiology
Data availability statement
All data relevant to the study are included in the article or uploaded as supplementary information.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
The first systematic review to investigate the performance of early warning scores (EWS) in different patient disease subgroups and clinical settings.
Meta-analysis was performed for different EWS and national EWS validation studies in different disease and clinical setting subgroups.
This study is limited to specific diseases and settings and does not consider the use of EWS in the general population.
Analysis of predictive accuracy of EWS is based on area under the curve, not other validation measures.
During the study period 1997–2019, approaches to EWS and their validation have changed.
Introduction
Across diseases, patient deterioration can range from critical care review and sepsis to cardiorespiratory arrest and death.1 2 Delays or failures in timely detection of deterioration adversely affect prognosis, morbidity, mortality and healthcare utilisation.3 For example, the 20 000 in-hospital cardiac arrests per year in England are associated with costs of £50 million for resuscitation and postarrest care.4 Around the world, earlier recognition and prevention of deterioration in unwell patients has far-reaching implications for reduction in mortality and morbidity, reduction in the cost of healthcare and allocation of scarce high dependency and critical care resources. Preventive interventions are needed to overcome these challenges.5
Specific characteristics have long been known to be associated with deteriorating patient health,2 5–8 including physiological parameters, such as heart rate and blood pressure.5 9–12 Early warning scores (EWS), widely used in high-income countries, were borne out of the need for early detection of patient deterioration. EWS are tools derived from prediction models that assess patient characteristics and physiological parameters to stratify the risk of developing a worsening event or need for medical attention.13 The algorithms underlying EWS can be ‘aggregate-weighted’ to sum up a set of parameters to produce a score or use more advanced statistical modelling.14 EWS inform clinical decision making, enabling escalation of attention and care when required. Universal tools, such as the modified early warning score (MEWS),15 were developed for use across different hospital settings, but specialised, non-standard EWS are also designed for particular subgroups, for example, Rapid Emergency Medicine Score16 and Quick Sequential Organ Failure Assessment (qSOFA)17 for patients with infections. In recognising different settings, EWS may have compromised simplicity and timeliness of assessment.13 For example, a number of EWS rely on parameters that do not exist in the first hours of assessment, such as blood investigations and imaging.1 18 19
From fragmented implementation and inadequate early assessment via specialised tools, EWS have shifted back to universal prediction models, particularly, the national early warning score (NEWS),20 followed by NEWS2.21 NEWS was designed to produce a universal assessment of acute illness severity across the National Health Service (NHS).22 While showing good discrimination compared with other EWS, especially in predicting mortality, there was a need to accommodate additional clinical parameters in the score. The updated NEWS2, emphasising appropriate scoring for type 2 respiratory failure, confusion and severe sepsis,21 was formally endorsed by NHS England23 to be the EWS used in acute care. However, there have been concerns regarding excessive calls to clinicians, administrative workload and variable symptoms across diseases and settings.24 The effectiveness of the universal EWS (box 1) with standardised use across all settings is not clear in specific disease populations25 and requires validation to estimate discrimination and calibration, like other clinical prediction models.26 While internal validation is useful, generalisability and reproducibility needs external validation.27
Definitions
Universal early warning scores (EWS): EWS that are globally adopted and applicable in every setting and for any disease subgroup.
Standardised EWS: EWS model with a set of parameters used in a unified approach to predict deterioration in any patient subgroup.8 23
External validation: evaluation of the model’s predictive accuracy with data different than the one sued for model development.27
Internal validation: evaluation of a model’s predictive accuracy with the same data set used for the development or in a population in which the model is intended for use.27
Discrimination: the ability of a model to distinguish between the patients who will develop an outcome of interest and the ones who will not.26
Calibration: the accuracy of risk estimates in relation to the observed number of events.73
Systematic reviews have evaluated EWS in prehospital, intensive care unit (ICU) and general settings,3 28 29 and sepsis,15 with narrow inclusion criteria and inadequate assessment of study quality. A recent systematic review evaluated development and validation of EWS in general patients but did not include studies in specific disease subgroups or settings.30
Objective
In a systematic review, we will assess performance of universal EWS in particular diseases and clinical settings in predicting mortality, transfer to ICU and cardiac arrest.
Methods
Search strategy
The protocol adhered to Preferred Reporting Items for Systematic Review and Meta-Analysis Protocols guidelines.31 Published articles were identified in MEDLINE, CINHAL and Embase, between 1997 (initial development of EWS) and 2019. The Cochrane database was searched for systematic reviews (CDSR) and trials (CENTRAL). For grey literature, Google Scholar was searched. During the screening procedure, studies were added from references in review articles and studies. Search strategies were developed by two authors (BA and AB) and reviewed by a third author (TB). Terms used for searching databases include terms for early warning or track and trigger scores and acronyms, identified subgroups and settings (eg, Medical Subject Heading (MeSH)) and free-text search terms (figure 1; online supplemental methods).
Supplemental material

Search strategy and included studies regarding universal early warning scores (EWS) in different disease subgroups and clinical settings.
Inclusion and exclusion criteria
Patient subgroups were identified according to disease categories and clinical settings (online supplemental methods). Studies were included if: (1) validation of a universal EWS with standardised prediction model in adult patients; (2) EWS validation was in a specific setting or disease; (3) the performance of the EWS, or the impact on mortality, transfer to ITU and cardiac arrest, was examined; and (4) they were prospective or retrospective cohort, cross-sectional, case–control design or trials.
Studies were excluded if: (1) patients were less than 16 years of age; (2) EWS performance was only examined in derivation, not validation; (3) non-universal EWS was developed for a specific subgroup, for example, obstetric early warning score for obstetric patients or qSOFA for patients with infections; or (4) EWS validation was performed in a general patient dataset or setting, for example, validation in a general hospital without consideration of hospital subgroups.
Data extraction
Articles were screened by title and abstract by one author (BA), then full-text screening was by two reviewers (BA and AB). Data were extracted independently by two reviewers (BA and AB) using a standardised and piloted data form. A third reviewer (TB) resolved any disagreements. Items for extraction for studies examining predictive accuracy were based on the CHARMS32 checklist, except for tool derivation, which was excluded.
Quality assessment
Risk of biases in validation studies was assessed using Prediction model Risk Of Bias ASsessment Tool (PROBAST),33 which classifies studies as low, unclear or high risk of bias in four aspects: participant selection, predictors, outcomes and analysis within the overall risk of bias and the study applicability domains.
Evidence synthesis
We conducted the analysis using MS Excel and R programs. We summarised the results using descriptive statistics and graphical plots. Meta-analysis was performed, in different subgroups, using area under the curve (AUC) for identified universal EWS and for NEWS in studies. Fisher-Z transformation for correlation coefficients was conducted for AUC into normally distributed Z with 95% CI to evaluate the effect size and test for the heterogeneity. Where applicable, narrative synthesis was conducted.
Patient and public involvement
Patients or the public were not involved in the design, or conduct, or reporting, or dissemination plans of our research.
Results
Study characteristics
Of the 16 181 articles identified by our search, we screened 1355 articles by title and abstract, assessing 770 articles in full for eligibility. We included 103 studies, published between 2006 and 2019, in the final stage. These studies were predominantly observational (retrospective=65, prospective=36 and RCT=2). Emergency department (ED) (n=48) was the most common clinical setting, followed by medical (n=12), ICU (n=12) and surgical (n=9) settings. Sepsis (n=33) was the most common disease subgroup. Other subgroups ranged from respiratory (n=8) to renal (n=1)(figures 1 and 2). Mortality was the main studied outcome. Cardiac arrest was infrequently studied (n=8).

Number of studies regarding performance of early warning scores in different disease subgroups and clinical settings. Each bubble represents the disease subgroup and/or setting where different early warning scores were examined. The size of the bubble represents the number of studies (n), and overlapping bubbles show studies where disease subgroup and settings overlap. CVD, cardiovascular diseases; ED, emergency department; GiI, gastrointestinal diseases; ICU, intensive care unit.
Quality assessment
There was a significant risk of bias found in majority of studies (high risk=16; unclear risk=64) and low risk in only 28 studies. In terms of applicability, narrow inclusion of conditions in a certain disease group was commonly related to risk of bias, while in general settings, biases were often due to low sample size or unspecified timing of EWS assessment. There was a wide variation in sample size (median: 551 and range: 43–920 029). There was variation in defining study population by number of patients, hospital admissions or not specifying the particular study sample. Almost half of the studies (n=49; 48%) validated in <500 patients with either multiple observations or a single observation set (tables 1–4). External validation was more common (n=83) than internal validation (n=18), and two studies included internal and external validations (online supplemental table S1).
Studysetting and design for included studies of predictive performance for early warning scores in patient subgroups and settings
Early warning scores, predictive measures and outcomes for included studies in patient subgroups and settings
Study design and setting forincluded studies of predictive performance for early warning scores in clinical settings
Early warning scores, predictive measures and outcomes for included studies of predictive performance for early warning scores in clinical settings
EWS validation in patient subgroups
Subgroups and EWS
In the studies validating EWS, there was heterogeneity in subgroup definitions, models and methods of predictive accuracy. There was overlap between diseases and settings commonly between studies of patients with infections receiving care in ED34–36 and patients with sepsis admitted to ICU.37 38 EWS models that were integrated with electronic health records (EHRs) were examined in recent studies (n=9). Research on datasets using EWS-embedded EHRs had larger sample sizes, ranging from 50439 to 13 014 patients40 (tables 1–4), with moderate to high predictive ability (AUC: 0.65–0.85). Several studies included comparison between different EWS in the same cohort (n=21)35 38 41 (online supplemental table S2).
Methodology
There was significant heterogeneity in methods across studies. The majority of studies were observational. Evaluation of predictive accuracy of different EWS in the same study was common.22 42–44 To measure accuracy of EWS, AUC was most commonly used (n=94), especially when comparing different EWS in the same study.22 45 Presentation of results was variable; for example, confidence intervals were missing in many studies. Other measures, such as analysing sensitivity and specificity, prognostic index and ORs, were found in only eight studies (tables 1–4). Consequently, it was only feasible to analyse predictive accuracy in studies where AUC was the selected measure.
Timing from EWS assessment to endpoints was variable. Many studies included (n=43) AUC within 24–48 hours, while 11 studies had endpoints more than 48 hours after EWS. However, the majority (n=65; 63%) did not specify time horizon or in-hospital outcome.
Predictive performance of EWS
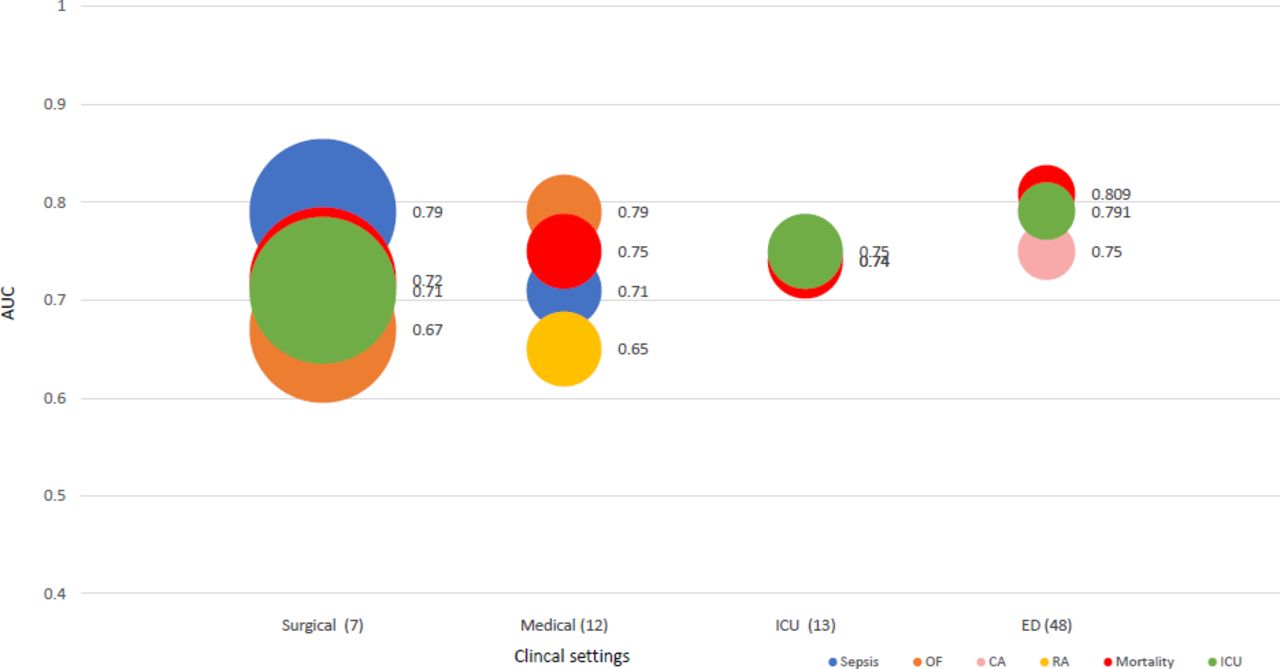
Outcomes were most commonly mortality, transfer to ICU, developing sepsis (in patients with infections) and cardiac arrest. Few studies examined other outcomes, for example, respiratory arrest (n=1) and organ failure (n=4). Mortality, ICU admission and cardiac arrest were best predicted in medical (AUC mean: 0.74, 0.75 and 0.74)46–48 and surgical settings (0.80, 0.79 and 0.75),49 50 and respiratory diseases (0.75, 0.80 and 0.75), respectively. EWS prediction of sepsis had reasonable predictive performance in all subgroups (AUC: 0.71–0.79) and infectious diseases in particular (AUC: 0.79). Certain outcomes related to specific disease groups were not studied, for example, cardiac arrest was not studied in cardiac patients22; respiratory arrest was not tested in respiratory patients.46–52
The best predictive performance was found in studies examining cardiac,46 stroke46 53 and renal46 diseases (AUC: 0.93, 0.88 and 0.87, respectively). In emergency settings, predictive accuracy was variable (AUC: 0.56–0.91).54–58 In haematology and oncology diseases, EWS predictive accuracy was suboptimal in mortality (online supplemental figure S1), cardiac arrest and ICU transfer (AUC: 0.52–0.69; figures 3 and 4).59–61 EWS prediction of ICU transfer was reasonable in ED,57 62 infectious diseases,63 64 and where both groups overlap,42 65 but not in gastroenterology and haematology (AUC: 0.64 and 0.60)60 66 (online supplemental figure S2) Cardiac arrest was the least examined outcome among the three endpoints (n=8) and unstudied in cardiac diseases (figures 3 and 4, online supplemental figure S3).

Early warning score performance in different disease subgroups. Each bubble represents critical events predicted by early warning scores for each disease subgroup with average AUC of studies beside each event type. The size of the bubble represents the number of studies in each subgroup. CA, cardiac arrest; CVD, cardiovascular diseases; GI, gastrointestinal diseases; ICU, intensive care unit; OF, organ failure; RA, respiratory arrest.

Early warning score performance in different clinical settings. Each bubble represents critical events predicted by early warning scores for each disease subgroup with average AUC of studies beside each event type. The size of the bubble represents the number of studies in each subgroup. CA, cardiac arrest; ED, emergency department; ICU, intensive care units; OF, organ failure; RA, respiratory arrest.
For mortality prediction, meta-analysis of included EWS showed high degree of statistical heterogeneity across all subgroups (I2=72%–99%) (figure 5). In validation studies of NEWS in different disease subgroups, there was also significant heterogeneity (I2=99%; figure 6).

Forest plot of predictive accuracy of universal early warning scores (EWS) for mortality in different disease subgroups and clinical settings. CVD, cardiovascular diseases; ED, emergency department; GI, gastrointestinal diseases; Hem, haematological diseases; ICU, intensive care units; Infec, infectious diseases; Med, medical settings; Onco, oncology diseases; Renal, renal diseases; renal diseases; Resp, respiratory diseases; stroke, patients who had a stroke; Surg, surgical settings . Note: number following author(s) and year indicate more than one EWS evaluated in the study.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Forest plot of predictive accuracy of NEWS for mortality. AUC, area under the curve; NEWS, national early warning score.
Discussion
In this comprehensive review of universal EWS across all diseases and settings, we had three main findings. First, EWS studies in different diseases and clinical settings were heterogeneous in methodology, predictive performance measures and number of studies in each subgroup. Second, validation of EWS is limited in specialised settings, including cardiac disease. Third, despite widespread EHR and EWS integration, few studies have explored EHR-based EWS.
Inconsistency in evaluation and the lack of high-quality validation make the evidence of validity questionable, ultimately affects how EWS can and should be used in clinical practice as a risk score for deterioration prediction. Heterogeneity across studies in all subgroups challenges implementation of EWS in all diseases and all settings. In methodology, observations selections method, time horizon between EWS score and event and the metric used in assessment were inconsistent. Choosing multiple observations or a single observation prior the outcome may not significantly affect the ranking of EWS.67 Yet, selecting a single observation is generally associated with high AUC compared with multiple observations,46 67 supporting the use of multiple observations for each episode. Moreover, AUC, the most commonly used measure of predictive performance, has limitations and other metrics, including positive predictive value, should also be assessed.68 Recording observations at an agreed threshold point before events in a standardised method is necessary to evaluate EWS effectively.
The universal EWS with standardised models were primarily designed for general patient populations in wards and EDs and remain underevaluated in specific diseases and settings. In medical and ED contexts, EWS perform well, suggesting the role of EWS in general settings, or at the early stage of clinical assessment. Our positive findings in respiratory disease may indicate the emphasis of several EWS, such as NEWS2, on respiratory changes when patients are deteriorating. Specific disease areas may show unique alarm signs when critical events are anticipated, which may not be captured by universal EWS, such as NEWS2, where prediction of deterioration is based on predefined thresholds in all patients.23 Critical events are commonly associated with CVD. With CVD being a leading cause of mortality globally, and the significant impact of morbidity on health and social care, early detection of deterioration is necessary.69 However, EWS are poorly validated in CVD, some of the parameters may not be applicable and EWS may be unrepresentative.25 A recent study of NEWS2 in patients with COVID-19 infection found poor performance in severity prediction,70 despite pre-existing conditions being common and predictive in patients with severe outcomes. EWS may need to take account of disease-specific risk factors and comorbidities.
Widespread uptake of EHR and digitisation of patient observations are expected to contribute to efficient use of EWS by reducing human errors in documentation and calculation, as well as delays in escalation of care. However, relatively few studies have considered EHR-based EWS, and those studies have not analysed whether predictive performance of EWS is related to EHR use, diseases or settings. Investigating implementation and adoption of EWS is necessary to understand the application and performance of EWS. Predictive algorithms derived by machine learning have been successfully used in developing and validating EWS41 71 but will require robust evaluation. Studying the implementation process of EWS within EHR will provide opportunities for qualitative and quantitative insights into escalation of care, as well as facilitators and barriers to use of EWS in routine practice.
There are several limitations in this review and in included studies. We aimed for a comprehensive investigation of all EWS developing since 1997, but this long study period may lead to bias in comparing studies with old and new validation approaches statistically and technically. We excluded EWS specifically derived and validated for particular disease populations or settings and excluded studies considering a general patient population. Meta-analysis was only done for studies using AUC, excluding other methods for assessing performance of EWS. The distinction between general patient settings and specific disease or patient subgroups is dependent on hospital, healthcare system and country, and there is inevitably overlap between patients and settings at different stages in patient pathways. It was only feasible to include studies with a clear disease or setting identified to avoid confusion.
Validation of EWS in disease subgroups should consider similarities and differences across diseases, sample size and include measures of model discrimination and calibration. Further research should adhere to established guidelines on clinical outcomes and predictive clinical scoring for decision making, such as the PROGRESS framework.72
Conclusion
Universal EWS in specific disease subgroups and settings require further validation of their performance in detecting worsening outcomes. Despite good performance in respiratory patients and medical and surgical settings in studies to date, the predictive accuracy of EWS in all disease subgroups and all clinical settings remains unknown. The current evidence base does not necessarily support use of standard EWS in all patients in all settings. Future research should include validation of EWS in particular patient subgroups and settings, with standardised methodology following established guidelines. Going towards the utilisation of EHR for EWS development, validation and implementation within EHR should be considered for improved EWS systems.
Data availability statement
All data relevant to the study are included in the article or uploaded as supplementary information.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Twitter @BaneenAlhmoud, @DrRiyazPatel, @amibanerjee1
Contributors AB conceived the study. BA, AB and TB conducted the search, data extraction and data analysis. BA wrote the initial draft of the manuscript. All authors contributed to interpretation of findings, critical review and revisions of the manuscript.
Funding BA has received PhD funding from the Saudi Arabian Cultural Bureau.
Competing interests AB has received research grants from AstraZeneca.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.